|
6.1 Full-Order State Estimation
The state estimation problem is described briefly in the following only for the continuous-time systems Eq. (6.1). Adaptation to the discrete-time systems is straightforward. The state-space system is assumed to be observable.
Given the matrices A, B, C, and D and the input and output vectors u(t) and y(t) of the continuous-time system,
 where 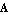 is is 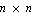 , , 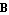 is is 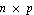 ( (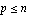 ), and ), and 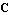 is is 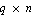 ( (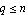 ), the state estimation problem is one of finding an ), the state estimation problem is one of finding an 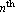 order estimator order estimator 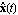 of of 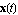 , satisfying , satisfying

such that the error 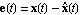 approaches zero as approaches zero as 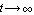 . Figure 6.1 presents a feedback design scheme that uses an estimator in block diagram form. As seen in the diagram, the estimator uses the control input . Figure 6.1 presents a feedback design scheme that uses an estimator in block diagram form. As seen in the diagram, the estimator uses the control input 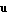 and the actual output measurement and the actual output measurement  to produce the estimate to produce the estimate  of the system states. When the estimator computes values of all of the system states. When the estimator computes values of all  states, the problem is called the full-order state estimation problem to distinguish it from the reduced-order state estimation problem, where only values of some states are estimated while the remaining ones are estimated directly from the input and output vectors (see Section 6.2). To obtain states, the problem is called the full-order state estimation problem to distinguish it from the reduced-order state estimation problem, where only values of some states are estimated while the remaining ones are estimated directly from the input and output vectors (see Section 6.2). To obtain 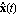 from Eq. (6.2), one finds the matrix from Eq. (6.2), one finds the matrix 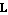 such that the matrix such that the matrix 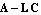 is stable. This can be done using either the pole assignment algorithms or solving the associated Sylvester-observer equation. The function EstimatorGains in Control System Professional (Section 9.2) uses the pole assignment approach to solve the full-order state estimation problem. is stable. This can be done using either the pole assignment algorithms or solving the associated Sylvester-observer equation. The function EstimatorGains in Control System Professional (Section 9.2) uses the pole assignment approach to solve the full-order state estimation problem.
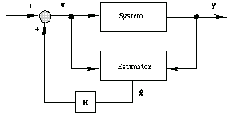
Figure 6.1. The feedback design scheme that uses the state estimator.
New numerical methods introduced in Advanced Numerical Methods to solve the pole assignment problem are available for the function EstimatorGains.
Make sure that the package is available.
In[1]:=
Load the collection of test examples.
In[2]:=
This is a simplified magnetic tape control problem.
In[3]:=
Out[3]=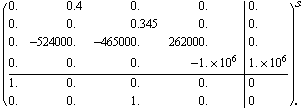
Here are the system poles.
In[4]:=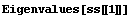
Out[4]=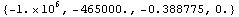
This finds the estimator gains for the system by replacing the unstable pole  with the pole at with the pole at 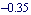 while preserving the remaining stable poles. while preserving the remaining stable poles.
In[5]:=
Out[5]=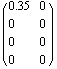
|