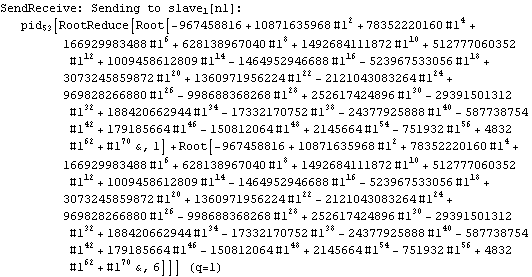
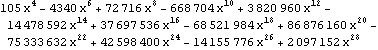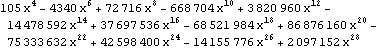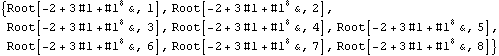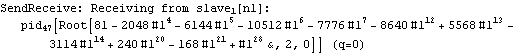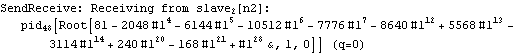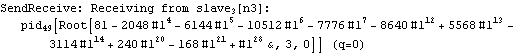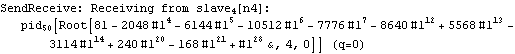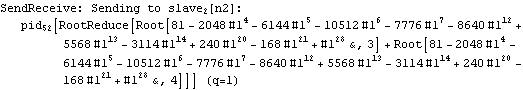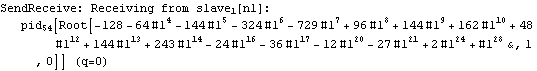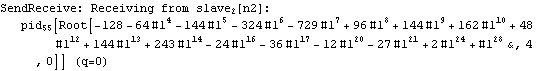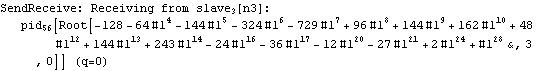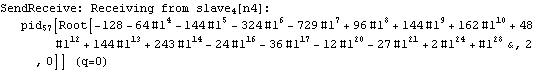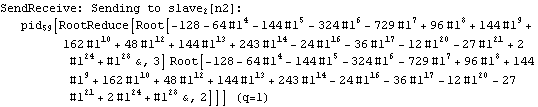Parallel Computing Toolkit — Examples The Cascade (Binary Trees)PreparationMake sure you have at least two kernels available. Binary TreesGiven an associative binary operation f, compute f[a1,...,an] using a binary tree by splitting the list {a1,...,an} into pairs, applying f to the pairs, and repeating the process. Formally we evaluate f[a1,...,an] as f[... f[f[a1,a2],f[a3,a4]],...]. Code for Cascade[]For simplicity of coding, we generate a sublist of length one if the number of elements of the list is odd and apply f to that single element. This is justified because we can assume that f[a]=a for an associative function f. Careful study of the documentation of Partition[] should allow us to find the required parameters to allow for the extra odd last element (which normally is thrown away). Apply f to the pairs (and the odd last element). The last two steps can be repeated until there is only one element left. Here is the code for Cascade[f,list]. To parallelize the application of f, we simply compose f with Queue. The loop terminates as soon as only one element is left. Test and TraceThe SendReceive tracing option allows you to see which expressions are sent to the remote kernels. ExamplesPolynomial ArithmeticThis example multiplies and expands out a list of Chebyshev polynomials. In this case, a simple parallel product is probably faster. Arithmetic with Algebraic NumbersWe generate the roots of a polynomial as algebraic numbers and then add or multiply them. The large example can lead to several hours of computing time. The smaller examples should finish within a few seconds. The optional SendReceive tracing allows you to see the intermediate algebraic numbers. Large, slow example: Smaller, faster examples: The sum of the roots is the coefficient of xn-1. The product of the roots is the coefficient of x0, the constant coefficient. In case you want to abort the computation, follow the abort of the master kernel by ResetSlaves[]. A Hybrid Method for Long ListsIf the number of elements in the cascade is much larger than the number of remote processors, it may make sense to follow a hybrid strategy:
- first, divide the list into as many parts as there are processors and work on these sublists in parallel
- second, apply the ordinary cascade to the results CodeHere is the extra code for long lists, followed by the unmodified old code. The first case is a straightforward application of ParallelEvaluate[]. For a number of elements equal to twice the number of processors, the first case degenerates into the second case, so we use it only for longer lists. For completeness, we also treat the case of no elements, which should just give f[]. Example and Trace |