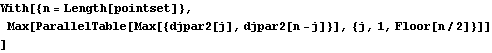Parallel Computing Toolkit — Examples Diameter of a Point SetPreparationMake sure you have at least two kernels available. Problem StatementGiven a list of points in the plane, with each point given as a pair of coordinates {x,y}, what is the maximum distance between any two points? This value is called the diameter of the point set. Here is a sample point set. Sequential SolutionThe distance between two points is the square root of the sum of the squares of the coordinate differences. Here is a definition for the distance function for 2D points. However, we can easily make the definition independent of the dimension. In a procedural program you might write a double loop over the list or array of points and compare the distance of the two points with the maximum obtained so far. One obvious optimization is to compare only half of the pairs, as the distance between pi and pj is equal to the distance between pj and pi and there is no need to compute the distance of a point with itself. To prepare for parallelization, we note that the inner loop (over j) computes the distance between point j and all other points (or more precisely, all points pi with i>j). We can express this computation as a function of j and the set of points. The diameter is now simply the maximun of dj[pts,j] over all j. This computation takes twice as long as the previous optimized loop, because we compute all pairs {i, j}, not just those with j>i, but it is easier to parallelize. We will take care of the performance later. ParallelizationStraightforwardIn realistic applications, the number of points will be much greater than the number of remote processors. It is therefore more efficient to send the list of points once to all processors and not as part of each evaluation. Now the list of points is a global variable on each remote kernel, and we can specialize the definition for dj[], to avoid sending the list of points to the remote kernels for every invocation. Using ParallelTable in place of Table in the sequential solution gives us the first parallel version. Here is a function that sets up the computation and then cleans up the remote kernels. ImprovementsWe can change the definition of djpar so that only the distances between pj and pi with i>j are computed. This computation should only take half as long as the previous one, but it appears slower than that. The reason is that now the individual computations djpar2[j] do not all take the same amount of time, an assumption that the dispatcher inside ParallelTable makes. The easiest way to make all evaluations take the same amount of time is to pair them as {djpar2[1],djpar2[n-1]}, {djpar2[2],djpar2[n-2]}, .... (The timings will be equal only if all processors have the same speed or their speed has been calibrated.) Here are the functions for these computations. The wallclock timings show the improvements we made. |