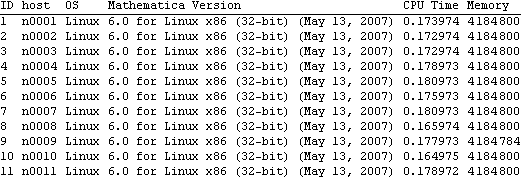
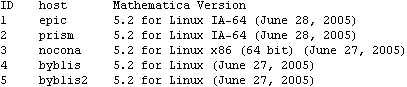
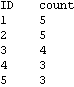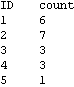Parallel Computing Toolkit — Examples Performance Measurement and CalibrationPreparationMake sure you have at least two kernels available. ProcessorSpeed CalibrationRemote kernels have a speed property that you can set when you launch the kernels or later, as is shown in this example. The default speed is 1. If the remote machines have different performance, setting the speed correctly helps in scheduling parallel computations. This section was evaluated on a heterogeneous collection of workstations connected by a 100Mb/s network. Here are the current (default) settings. The function ParallelEvaluate[] takes speed settings into account when distributing a computation to remote kernels. This section shows how to experimentally determine the relative processor speeds. We use a high-precision numerical calculation for the measurements. To get reproducible results, any cached values in the kernels should be cleared first. Here we measure the CPU time used for the test calculation on each remote kernel. The results depend mostly on the CPU speed or frequency, but might be influenced by memory cache performance on a heavily loaded machine. Alternatively, we can measure elapsed time, which takes into account effects of time-sharing on a heavily loaded machine. (AbsoluteTiming[] is not available in Mathematica versions earlier than 5.0.) The speeds are the inverses of the times, normalized such that the lowest speed is 1. Here we set each kernel's speed property to the respective speed value. A Calibration FunctionRemoteCalibrate[] performs the previous steps given any suitable test evaluation. The second argument is the timing function to be used and defaults to Timing for measuring CPU times. Another suitable value for the second argument is AbsoluteTiming for measuring elapsed time. Processor UtilizationPerformance measures several timing values that are of interest for judging the performance of a parallel computation. The argument is any (parallel) command. The function returns these values in a list:
- the elapsed time of the computation
- the CPU time used on the master kernel
- the CPU times on all remote kernels in the form of a list
- the sum of all CPU times of the remote kernels
- the result of the computation Measuring the Effect of CalibrationHere we measure the performance of a ParallelTable command. Ideally the CPU times on all remote kernels are identical and the total elapsed time is not much more than the largest remote CPU time. The time spent in the master kernel should be small. If your remote kernels run on different types of machines, you may want to perform a speed calibration as described in the previous section and then repeat the performance measurement. Now the times should be nearly identical and the elapsed time correspondingly smaller. Comparison of ParallelTable and QueueingThis section uses the Performance[] function defined in the previous section. Basic ComparisonParallelTable[] does a single dispatch and evaluates part of the table on each remote kernel. Wait[] and Queue[] generate a single job for each iteration of the table. Note: The computing times for the two operations on the remote kernels are about the same, but there is more communication, and therefore, more work for the master kernel and a larger elapsed time for the queueing method. The queueing method is advantageous if the individual evaluations do not all take the same amount of time or the processor speeds have not been calibrated because it performs automatic load balancing if the number of jobs is large enough. Uneven JobsThis example does evaluations of widely varying time. The evaluations return the process ID of the processor on which they were performed. Here we count the number of evaluations on each remote kernel. Scheduling is not very good because the largest jobs are scheduled last (the order is given by the order in which they were queued). Using Priority QueuesWe can improve performance considerably by scheduling "heavy" jobs first. To specify scheduling in Queue[], we need to use priority queues. If the current queue type is not priorityQueue, we load the corresponding package and change the queue type. Not only are the heavier jobs scheduled first, but they are also assigned to the processors with the highest speed. The different number of evaluations on the different kernels reflect that fact that some evaluations are much shorter than other ones and scheduling automatically assigns new jobs to processors that finish sooner. |