Suppose that the stationary time series model that is fitted to the data
{x1, x2, ... , xn} is known and we would like to predict the future values of the series
Xn+1, Xn+2, ... , Xn+h based on the realization of the time series up to time
n. The time
n is called the
origin of the forecast and
h the
lead time. A linear predictor is a linear combination of
{X1, X2, ... , Xn} for predicting future values; the
best linear predictor is defined to be the linear predictor with the minimum mean square error. Let
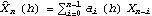
denote the linear predictor for
Xn+h at lead time
h with the origin
n and
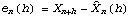
the forecast error. Finding the best linear predictor is reduced to finding the coefficients
ai(h),
i=0, 1, ... , n-1, such that the mean square error
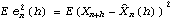
is a minimum.
Although the idea is straightforward, the derivation of the best linear predictor is too involved to be presented here. A detailed derivation of the best linear predictor using the projection theorem and the innovations algorithm is provided in Brockwell and Davis (1987), Chapter 5, pp. 159-177.
gives the best linear prediction and its mean square error up to
h time steps ahead based on the finite sample data and given model. It uses the innovations algorithm to calculate the forecasts and their errors. Here the errors are obtained under the assumption that the model is known exactly. Estimated model parameters can give rise to additional errors. However, they are generally negligible when
n is large. See the discussion in Harvey (1981), p. 162.
The first entry of the above list is the prediction for the next five values of the series; the second entry, mean square errors of the prediction. Note that for an MA(
q) model,
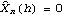
for
h>q since after
q time steps we lose all previous information and the best we can predict is the mean value of the series which is zero.
