

DiscreteLQRegulatorGains
DiscreteLQRegulatorGains[sspec,wts,τ]
gives the discrete-time state feedback gains with sampling period τ for the continuous-time system specification sspec that minimizes a cost function with weights wts.
DiscreteLQRegulatorGains[…,"prop"]
gives the value of the property "prop".
Details and Options
- DiscreteLQRegulatorGains is also known as discrete linear quadratic regulator, discrete linear quadratic cost equivalent regulator or discrete linear quadratic emulated regulator.
- DiscreteLQRegulatorGains is typically used to compute a digital implementation of a regulating controller or tracking controller.
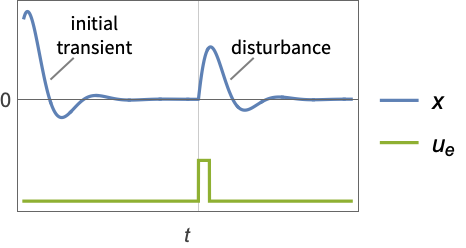
- A regulating controller aims to maintain the system at an equilibrium state despite disturbances
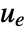 pushing it away. Typical examples include maintaining an inverted pendulum in its upright position or maintaining an aircraft in level flight.
pushing it away. Typical examples include maintaining an inverted pendulum in its upright position or maintaining an aircraft in level flight. - The regulating controller is given by a control law of the form
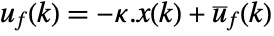 , where
, where 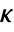 is the computed gain matrix.
is the computed gain matrix. - The continuous-time cost function is given by
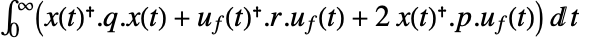 .
. - A tracking controller aims to track a reference signal despite disturbances
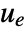 interfering with it. Typical examples include a cruise control system for a car or path tracking for a robot.
interfering with it. Typical examples include a cruise control system for a car or path tracking for a robot. - The tracking controller is given by a control law of the form
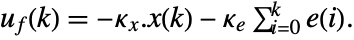 , where
, where 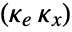 is the computed gain matrix for the augmented system, which includes the system sys as well as the dynamics for
is the computed gain matrix for the augmented system, which includes the system sys as well as the dynamics for 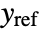 .
. - The approximate discrete-time system:
- The continuous-time cost function is given by
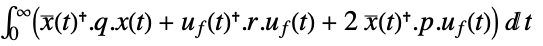 , where
, where 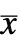 are the augmented states.
are the augmented states. - The number of augmented states is given by
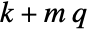 , where
, where 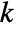 is given by SystemsModelOrder of sys,
is given by SystemsModelOrder of sys, 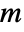 the order of yref and
the order of yref and 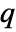 the number of signals yref.
the number of signals yref. - The choice of weighting matrices results in a tradeoff between performance and control effort, and a good design is arrived at iteratively. Their starting values can be diagonal matrices with entries
![TemplateBox[{{1, /, z}, i, 2}, Subsuperscript]](Files/DiscreteLQRegulatorGains.en/21.png "TemplateBox[{{1, /, z}, i, 2}, Subsuperscript]") , where zi is the maximum admissible absolute value of the corresponding xi or ui.
, where zi is the maximum admissible absolute value of the corresponding xi or ui. - DiscreteLQRegulatorGains computes the discrete-time controller using an approximated discrete-time equivalent of a continuous-time cost function.
- The discrete-time approximated cost function is
![sum_(k=0)^infty(x^^(k).phi.x^^(k)+TemplateBox[{{{u, _, f}, (, k, )}}, ConjugateTranspose].rho.u_f(k)+2 TemplateBox[{{{x, ^, ^}, (, k, )}}, ConjugateTranspose].psi.u_f(k))](Files/DiscreteLQRegulatorGains.en/22.png "sum_(k=0)^infty(x^^(k).phi.x^^(k)+TemplateBox[{{{u, _, f}, (, k, )}}, ConjugateTranspose].rho.u_f(k)+2 TemplateBox[{{{x, ^, ^}, (, k, )}}, ConjugateTranspose].psi.u_f(k))") , with the following terms:
, with the following terms: -
state weight matrix 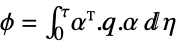
input weight matrix 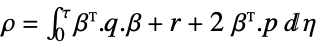
cross-coupling weight matrix 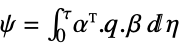
state vector 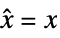 for regulation and
for regulation and 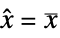 for tracking
for tracking - The weights wts can have the following forms:
-
{q,r} cost function with no cross-coupling {q,r,p} cost function with cross-coupling matrix p - The system specification sspec is the system sys together with the uf, yt and yref specifications.
- The system sys can be given as StateSpaceModel[{a,b,c,d}], where a, b, c and d represent the state, input, output and feed-through matrices in the continuous-time system
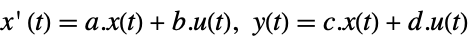 .
. - The discrete-time design model dsys is a zero-order hold approximation
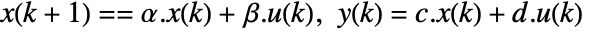 with the following terms:
with the following terms: -
state matrix 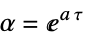
input matrix 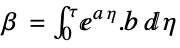
- The system specification sspec can have the following forms:
-
StateSpaceModel[…] linear control input and linear state AffineStateSpaceModel[…] linear control input and nonlinear state NonlinearStateSpaceModel[…] nonlinear control input and nonlinear state SystemModel[…] general system model <…> detailed system specification given as an Association - The detailed system specification can have the following keys:
-
"InputModel" sys any one of the models "FeedbackInputs" All the feedback inputs uf "TrackedOutputs" None the tracked outpus yt "TrackedSignal" Automatic the dynamics of yref - The feedback inputs can have the following forms:
-
{num1,…,numn} numbered inputs numi used by StateSpaceModel, AffineStateSpaceModel and NonlinearStateSpaceModel {name1,…,namen} named inputs namei used by SystemModel All uses all inputs - For nonlinear systems such as AffineStateSpaceModel, NonlinearStateSpaceModel and SystemModel, the system will be linearized around its stored operating point.
- DiscreteLQRegulatorGains[…,"Data"] returns a SystemsModelControllerData object cd that can be used to extract additional properties using the form cd["prop"].
- DiscreteLQRegulatorGains[…,"prop"] can be used to directly give the value of cd["prop"].
- Possible values for properties "prop" include:
-
"BlockDiagram" sampled-data block diagram of csys "ClosedLoopSystem" sampled-data closed-loop system csys {"ClosedLoopSystem",cspec} detailed control over the form of csys "Design" type of controller design "DesignModel" model used for the design "DiscreteTimeBlockDiagram" block diagram of dcsys "DiscreteTimeClosedLoopPoles" poles of "DiscreteTimeClosedLoopSystem" "DiscreteTimeClosedLoopSystem" dcsys {"DiscreteTimeClosedLoopSystem",cspec} detailed control over the form of dsys "DiscreteTimeControllerModel" dcm "DiscreteTimeDesignModel" approximated discrete-time model dsys "DiscreteTimeFeedbackGainsModel" dgm or {dgm1,dgm2} "DiscreteTimeOpenLoopPoles" poles of dsys "DiscreteTimeWeights" weights ϕ, ρ, π of the approximated cost "FeedbackGains" gain matrix κ or its equivalent "FeedbackInputs" inputs uf of sys used for feedback "InputCount" number of inputs u of sys "InputModel" input model sys "OpenLoopPoles" poles of "DesignModel" "OutputCount" number of outputs y of sys "SamplingPeriod" sampling period τ "StateCount" number of states x of sys "TrackedOutputs" outputs yt of sys that are tracked - Possible keys for cspec include:
-
"InputModel" input model in csys "Merge" whether to merge dcsys "ModelName" name of csys - The diagram of the approximated discrete-time regulator layout.
- The diagram of the approximated discrete-time tracker layout.
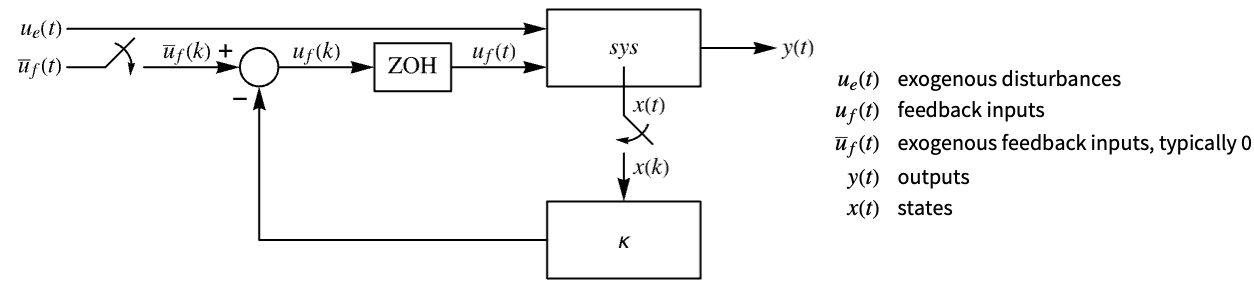
The approximate discrete-time system:
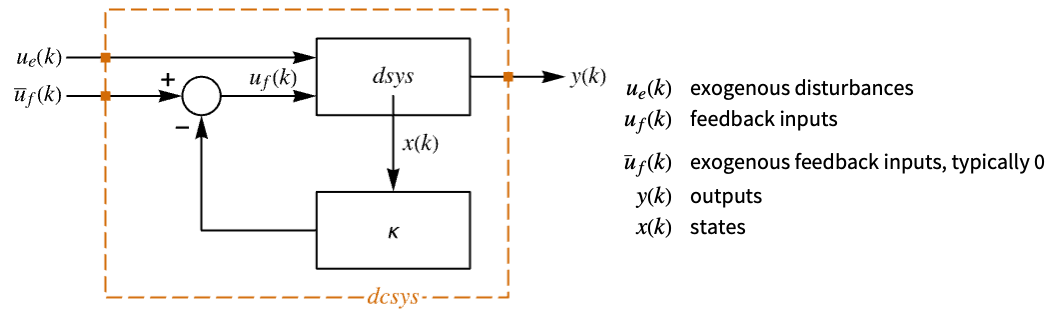
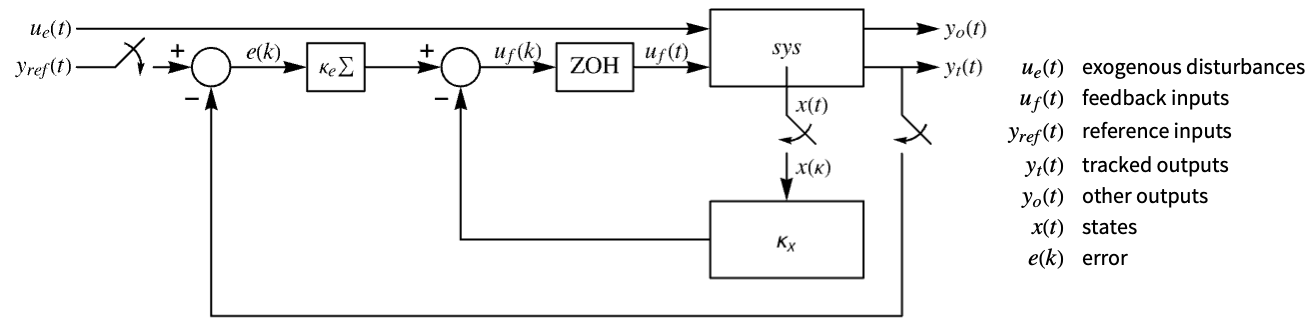
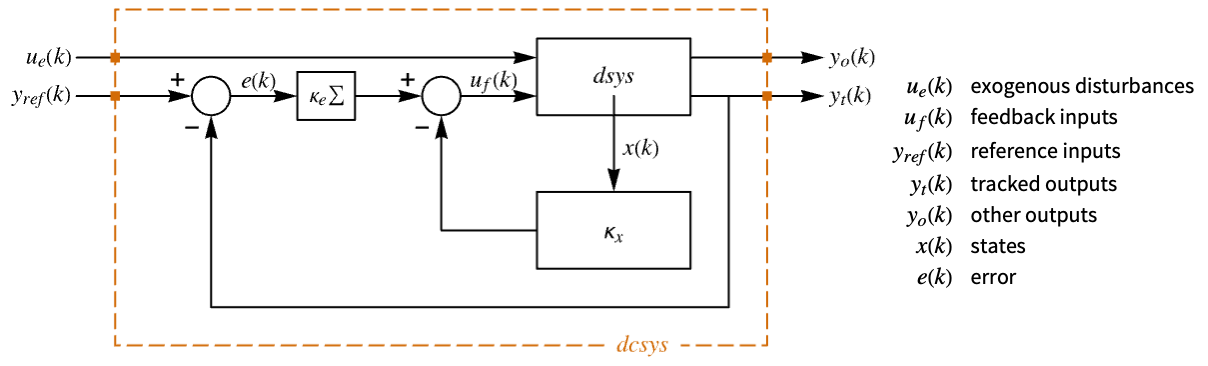
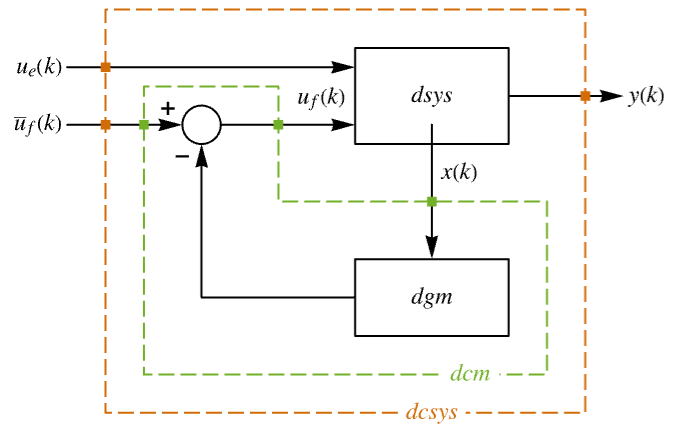
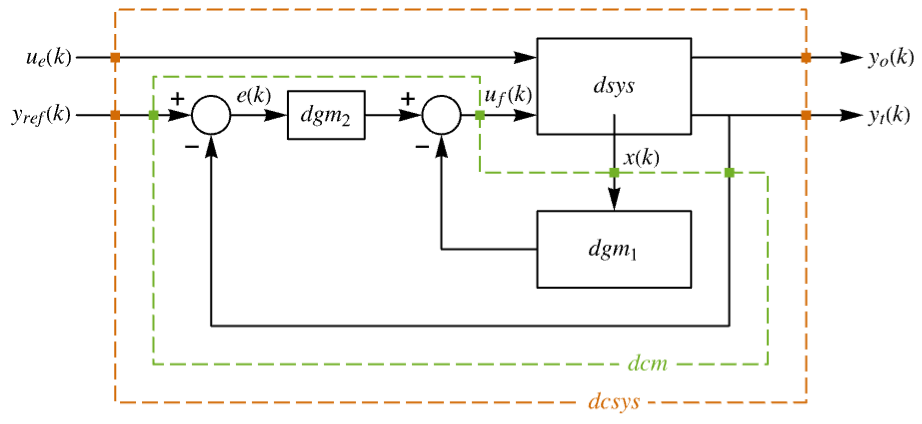
Examples
open all close allBasic Examples (4)
The system specification sspec of a system with feedback input uf and exogenous input ue:
sspec = <|"InputModel" -> StateSpaceModel[{{{2, 1}, {4, -5}}, {{1, 0}, {0, 0.1}}, {{1, 0}}, {{0, 0}}},
SamplingPeriod -> None, SystemsModelLabels ->
{{Subscript[u, f], Subscript[u, e]}}], "FeedbackInputs" -> 1|>;A set of regulator weights and a sampling period:
wts = {(| | |
| -- | -- |
| 10 | 0 |
| 0 | 10 |), {{0.1}}};
τ = 0.5;The discrete-time LQ regulator gains:
DiscreteLQRegulatorGains[sspec, wts, τ]A nonlinear system with feedback input u:
nssm = NonlinearStateSpaceModel[{{-1 + 3*Subscript[x, 2],
u + 2*Subscript[x, 1] - Subscript[x, 2]},
{Subscript[x, 1] + Subscript[x, 2]}},
{{Subscript[x, 1], 0}, {Subscript[x, 2], 1}}, {{u, 1}},
{Automatic}, Automatic, SamplingPeriod -> None];A set of regulator weights and a sampling period:
wts = {(| | |
| - | - |
| 1 | 0 |
| 0 | 1 |), {{0.25}}};
τ = 0.2;The discrete-time regulator gains:
DiscreteLQRegulatorGains[nssm, wts, τ]The discrete-time system with an output to be tracked:
sspec = <|"InputModel" -> StateSpaceModel[{{{3, 0}, {-1, 5}}, {{0, 1}, {1, 0}}, {{1, 0}}, {{0, 0}}}, SamplingPeriod -> None,
SystemsModelLabels -> None], "TrackedOutputs" -> 1|>;A set of weights and a sampling period:
wts = {(| | | |
| -- | ---- | -- |
| 10 | 0 | 0 |
| 0 | 10^2 | 0 |
| 0 | 0 | 10 |), (| | |
| - | - |
| 1 | 0 |
| 0 | 1 |)};
τ = 0.1;DiscreteLQRegulatorGains[sspec, wts, τ]ssm = StateSpaceModel[{{{0., 1.}, {-6., 5.}}, {{0.}, {1.}}, {{1, 0}}, {{0.}}}, SamplingPeriod -> None,
SystemsModelLabels -> None];A set of regulator weights and a sampling period:
wts = {(| | |
| - | - |
| 1 | 0 |
| 0 | 1 |), {{0.25}}};
τ = 0.2;dlqr = DiscreteLQRegulatorGains[ssm, wts, τ, "Data"]The open-loop and discrete-time closed-loop poles can be obtained as properties:
{olPoles, clPoles} = dlqr[{"OpenLoopPoles", "DiscreteTimeClosedLoopPoles"}]The unstable open-loop poles are on the right half of the s plane:
PoleZeroPlot[dlqr["InputModel"]]The stable closed-loop poles are within the unit circle of the z plane:
PoleZeroPlot[dlqr["DiscreteTimeClosedLoopSystem"]]Scope (30)
Basic Uses (7)
Compute the discrete-time state feedback gain of a system:
ssm = StateSpaceModel[{{{-1}}, {{1}}}, SamplingPeriod -> None, SystemsModelLabels -> None];κ = DiscreteLQRegulatorGains[ssm, {{{1}}, {{1}}}, 0.1]The discrete-time approximation is stable:
dssm = ToDiscreteTimeModel[ssm, 0.1, Method -> "ZeroOrderHold"]The discrete-time closed-loop system is even more stable:
SystemsModelStateFeedbackConnect[dssm, κ]The gain for an unstable system:
ssm = StateSpaceModel[{{{-1}}, {{1}}}, SamplingPeriod -> None, SystemsModelLabels -> None];κ = DiscreteLQRegulatorGains[ssm, {{{1}}, {{1}}}, 0.1]The discrete-time approximation is also unstable:
dssm = ToDiscreteTimeModel[ssm, 0.1, Method -> "ZeroOrderHold"]The discrete-time closed-loop system is stable:
SystemsModelStateFeedbackConnect[dssm, κ]The gains for various sampling periods:
ssm = StateSpaceModel[{{{-1}}, {{1}}}, SamplingPeriod -> None, SystemsModelLabels -> None];
vl = {0.01, 0.1, 1.0};κ = Table[DiscreteLQRegulatorGains[ssm, {{{1}}, {{1}}}, τ], {τ, vl}]The discrete-time approximations:
dssm = Table[ToDiscreteTimeModel[ssm, τ, Method -> "ZeroOrderHold"], {τ, vl}]The discrete-time closed-loop systems:
MapThread[SystemsModelStateFeedbackConnect, {dssm, κ}]Compute the state feedback gains for a multiple-state system:
ssm = StateSpaceModel[{{{-3, 0}, {0, -1}}, {{0.5}, {-0.5}}, {{-1, -1}}, {{0}}}, SamplingPeriod -> None,
SystemsModelLabels -> None];κ = DiscreteLQRegulatorGains[ssm, {(| | |
| - | - |
| 5 | 0 |
| 0 | 5 |), (1)}, 0.5]The dimensions of the result correspond to the number of inputs and the system's order:
Dimensions[κ]{SystemsModelDimensions[ssm][[1]], SystemsModelOrder[ssm]}Compute the gains for a multiple-input system:
ssm = StateSpaceModel[{{{0, 0, -5}, {1, 0, -9.5}, {0, 1, -5.5}}, {{-5, 1}, {-4.5, 0}, {-1, 0}},
{{0, 0, 1}}, {{1, 0}}}, SamplingPeriod -> None, SystemsModelLabels -> None];MatrixForm[κ1 = DiscreteLQRegulatorGains[ssm, {(| | | |
| - | - | - |
| 1 | 0 | 0 |
| 0 | 1 | 0 |
| 0 | 0 | 1 |), (| | |
| - | - |
| 1 | 0 |
| 0 | 2 |)}, 0.1]]Reverse the weights of the feedback inputs:
MatrixForm[κ2 = DiscreteLQRegulatorGains[ssm, {(| | | |
| - | - | - |
| 1 | 0 | 0 |
| 0 | 1 | 0 |
| 0 | 0 | 1 |), (| | |
| - | - |
| 2 | 0 |
| 0 | 1 |)}, 0.1]]A higher weight does not lead to a smaller norm:
Norm /@ κ1
Norm /@ κ2Increase the weight even more to reduce the relative signal size:
Norm /@ DiscreteLQRegulatorGains[ssm, {(| | | |
| - | - | - |
| 1 | 0 | 0 |
| 0 | 1 | 0 |
| 0 | 0 | 1 |), (| | |
| -- | - |
| 10 | 0 |
| 0 | 1 |)}, 0.1]Compute the gains when the cost function contains cross-coupling of the states and feedback inputs:
ssm = StateSpaceModel[{{{1, 0, 0}, {0, -2, 0}, {0, 0, 3}}, {{0, 0, -1}, {1, 0, -2}, {0.1, 0, 0.5}},
{{1, 0, 0}}, {{0, 0, 0}}}, SamplingPeriod -> None, SystemsModelLabels -> None];
MatrixForm[DiscreteLQRegulatorGains[ssm, {(| | | |
| -- | --- | - |
| 10 | 0 | 0 |
| 0 | 0.1 | 0 |
| 0 | 0 | 1 |), (| | | |
| - | - | - |
| 1 | 0 | 0 |
| 0 | 1 | 0 |
| 0 | 0 | 1 |), (| | | |
| - | - | - |
| 1 | 2 | 0 |
| 2 | 0 | 0 |
| 0 | 1 | 1 |)}, 1]]Compute the gains for a nonlinear system:
nssm = NonlinearStateSpaceModel[{{x2, u*(1 + x1) +
x1*x2 + Cos[x1]}, {x1}},
{{x1, 0}, {x2, -1}}, {{u, -1}}, {Automatic}, Automatic,
SamplingPeriod -> None];DiscreteLQRegulatorGains[nssm, {(| | |
| - | - |
| 1 | 0 |
| 0 | 1 |), (1)}, 0.1]The controller for the approximate linear system:
ssm = StateSpaceModel[nssm];DiscreteLQRegulatorGains[ssm, {(| | |
| - | - |
| 1 | 0 |
| 0 | 1 |), (1)}, 0.1]Plant Models (5)
DiscreteLQRegulatorGains[StateSpaceModel[{{{0, 1, 0}, {0, 0, 1}, {5, 9, 3}}, {{0}, {0}, {1}}, {{8, 2, 1}}, {{0}}},
SamplingPeriod -> None, SystemsModelLabels -> None], {(| | | |
| - | -- | -- |
| 1 | 0 | 0 |
| 0 | 10 | 0 |
| 0 | 0 | 10 |), (1)}, 0.1]A descriptor StateSpaceModel:
DiscreteLQRegulatorGains[StateSpaceModel[{{{-0.3, 0.65, 0}, {0, 1, 0}, {0.25, -0.5, -0.6}}, {{-1}, {0.5}, {0.7}},
{{1, 0, 0}}, {{0}}, {{3, 0, 0}, {5, 0, 0}, {0, 1, 0}}}, SamplingPeriod -> None,
SystemsModelLabels -> None], {(| | | |
| - | - | - |
| 4 | 0 | 0 |
| 0 | 3 | 0 |
| 0 | 0 | 5 |), (1)}, .1]DiscreteLQRegulatorGains[AffineStateSpaceModel[{{Sin[Subscript[x, 1]] + Subscript[x, 2],
-Subscript[x, 1] - Subscript[x, 2]},
{{Subscript[x, 1]}, {1}}, {Subscript[x, 1]}, {{0}}},
{Subscript[x, 1], Subscript[x, 2]}, {{u, 0}}, {Automatic},
Automatic, SamplingPeriod -> None], {(| | |
| - | - |
| 1 | 0 |
| 0 | 1 |), (1)}, 0.1]DiscreteLQRegulatorGains[NonlinearStateSpaceModel[
{{Subscript[x, 2] + Subscript[x, 1]*Subscript[x, 2],
u + Subscript[x, 1]}, {Subscript[x, 1]}},
{Subscript[x, 1], Subscript[x, 2]}, {u}, {Automatic},
Automatic, SamplingPeriod -> None], {(| | |
| - | - |
| 1 | 0 |
| 0 | 1 |), (1)}, 0.1]A SystemModel:
sm = CreateSystemModel[{x''[t] + x'[t] + x[t] == u[t], y[t] == x[t]}, t, {"u"∈"Modelica.Blocks.Interfaces.RealInput", "y"∈"Modelica.Blocks.Interfaces.RealOutput"}];DiscreteLQRegulatorGains[sm, {(| | |
| - | - |
| 1 | 0 |
| 0 | 1 |), (1)}, 0.1]Properties (14)
DiscreteLQRegulatorGains returns the discrete-time feedback gains by default:
DiscreteLQRegulatorGains[StateSpaceModel[{{{0, 1}, {-1, -2}}, {{0}, {1}}, {{1, 0}}, {{0}}}, SamplingPeriod -> None,
SystemsModelLabels -> None], {(| | |
| - | - |
| 1 | 0 |
| 0 | 1 |), (1)}, 1.0]% == DiscreteLQRegulatorGains[StateSpaceModel[{{{0, 1}, {-1, -2}}, {{0}, {1}}, {{1, 0}}, {{0}}}, SamplingPeriod -> None,
SystemsModelLabels -> None], {(| | |
| - | - |
| 1 | 0 |
| 0 | 1 |), (1)}, 1.0, "FeedbackGains"]In general, the feedback is affine in the states:
κ = DiscreteLQRegulatorGains[NonlinearStateSpaceModel[
{{-Subscript[x, 1] + u*Subscript[x, 1] +
Subscript[x, 2]/E^Subscript[x, 1],
E^Subscript[x, 2] - Subscript[x, 1]}, {Subscript[x, 2]}},
{{Subscript[x, 1], 1}, {Subscript[x, 2], 0}}, {{u, 1.}},
{Automatic}, Automatic, SamplingPeriod -> None], {(| | |
| - | - |
| 1 | 0 |
| 0 | 1 |), (1)}, 1.0]It is of the form κ0+κ1.x, where κ0 and κ1 are constants:
{κ0, κ1} = {κ /. {Subscript[x, _] -> 0}, D[κ, {{Subscript[x, 1], Subscript[x, 2]}}]}The systems model of the feedback gains:
DiscreteLQRegulatorGains[StateSpaceModel[{{{0, 1}, {-1, -2}}, {{0}, {1}}, {{1, 0}}, {{0}}}, SamplingPeriod -> None,
SystemsModelLabels -> None], {(| | |
| - | - |
| 1 | 0 |
| 0 | 1 |), (1)}, 1.0, "DiscreteTimeFeedbackGainsModel"]An affine systems model of the feedback gains:
DiscreteLQRegulatorGains[NonlinearStateSpaceModel[{{Subscript[x, 2], -2/3 + u -
Subscript[x, 1]/3 - Subscript[x, 2]/2},
{Subscript[x, 1]}}, {{Subscript[x, 1], 1},
{Subscript[x, 2], 0}}, {{u, 1.}}, {Automatic}, Automatic,
SamplingPeriod -> None], {(| | |
| - | - |
| 1 | 0 |
| 0 | 1 |), (1)}, 1.0, "DiscreteTimeFeedbackGainsModel"]The discrete-time closed-loop system:
DiscreteLQRegulatorGains[StateSpaceModel[{{{0., 1.}, {-0.05, -0.9}}, {{0}, {1}}, {{1, 0}}, {{0}}},
{Subscript[x, 1], Subscript[x, 2]}, {{f, 0}},
SamplingPeriod -> None, SystemsModelLabels -> None], {(| | |
| - | - |
| 1 | 0 |
| 0 | 1 |), (1)}, 1.0, "DiscreteTimeClosedLoopSystem"]The block diagram of the discrete-time closed-loop system:
DiscreteLQRegulatorGains[StateSpaceModel[{{{0., 1.}, {-0.05, -0.9}}, {{0}, {1}}, {{1, 0}}, {{0}}},
{Subscript[x, 1], Subscript[x, 2]}, {{f, 0}},
SamplingPeriod -> None, SystemsModelLabels -> None], {(| | |
| - | - |
| 1 | 0 |
| 0 | 1 |), (1)}, 1.0, "DiscreteTimeBlockDiagram"]The sampled-data closed-loop system:
DiscreteLQRegulatorGains[StateSpaceModel[{{{0., 1.}, {-0.05, -0.9}}, {{0}, {1}}, {{1, 0}}, {{0}}},
{Subscript[x, 1], Subscript[x, 2]}, {{f, 0}},
SamplingPeriod -> None, SystemsModelLabels -> None], {(| | |
| - | - |
| 1 | 0 |
| 0 | 1 |), (1)}, 1.0, "ClosedLoopSystem"]The block diagram of the sampled-data closed-loop system:
DiscreteLQRegulatorGains[StateSpaceModel[{{{0., 1.}, {-0.05, -0.9}}, {{0}, {1}}, {{1, 0}}, {{0}}},
{Subscript[x, 1], Subscript[x, 2]}, {{f, 0}},
SamplingPeriod -> None, SystemsModelLabels -> None], {(| | |
| - | - |
| 1 | 0 |
| 0 | 1 |), (1)}, 1.0, "BlockDiagram"]The poles of the linearized closed-loop system:
assm = AffineStateSpaceModel[{{Subscript[x, 2], -0.05*Subscript[x, 1] -
0.9*Subscript[x, 2]^2}, {{0}, {1}}, {Subscript[x, 1]}, {{0}}},
{Subscript[x, 1], Subscript[x, 2]}, {{f, 0}}, {Automatic},
Automatic, SamplingPeriod -> None];
{wts, τ} = {{(| | |
| - | - |
| 1 | 0 |
| 0 | 1 |), (1)}, 1.0};DiscreteLQRegulatorGains[assm, wts, τ, "DiscreteTimeClosedLoopPoles"]Increasing the weight of the states makes the system more stable:
DiscreteLQRegulatorGains[assm, {10wts[[1]], wts[[2]]}, τ, "DiscreteTimeClosedLoopPoles"]Increasing the weight of the feedback inputs makes the system less stable:
DiscreteLQRegulatorGains[assm, {wts[[1]], 10wts[[2]]}, τ, "DiscreteTimeClosedLoopPoles"]The model used to compute the feedback gains:
assm = AffineStateSpaceModel[{{Subscript[x, 2], -0.05*Subscript[x, 1] -
0.9*Subscript[x, 2]^2}, {{0}, {1}}, {Subscript[x, 1]}, {{0}}},
{Subscript[x, 1], Subscript[x, 2]}, {{f, 0}}, {Automatic},
Automatic, SamplingPeriod -> None];
{wts, τ} = {{(| | |
| - | - |
| 1 | 0 |
| 0 | 1 |), (1)}, 1.0};DiscreteLQRegulatorGains[assm, wts, τ, "DesignModel"]The poles of the design model:
DiscreteLQRegulatorGains[assm, wts, τ, "OpenLoopPoles"]The discrete-time approximate model used to compute the feedback gains:
DiscreteLQRegulatorGains[assm, wts, τ, "DiscreteTimeDesignModel"]The poles of the approximate discrete-time model:
DiscreteLQRegulatorGains[assm, wts, τ, "DiscreteTimeOpenLoopPoles"]The approximate discrete-time weights:
DiscreteLQRegulatorGains[AffineStateSpaceModel[{{Subscript[x, 2], -0.05*Subscript[x, 1] -
0.9*Subscript[x, 2]^2}, {{0}, {1}}, {Subscript[x, 1]}, {{0}}},
{Subscript[x, 1], Subscript[x, 2]}, {{f, 0}}, {Automatic},
Automatic, SamplingPeriod -> None], {(| | |
| - | - |
| 1 | 0 |
| 0 | 1 |), (1)}, 1.0, "DiscreteTimeWeights"];MatrixForm /@ %DiscreteLQRegulatorGains[AffineStateSpaceModel[{{Subscript[x, 2], -0.05*Subscript[x, 1] -
0.9*Subscript[x, 2]^2}, {{0}, {1}}, {Subscript[x, 1]}, {{0}}},
{Subscript[x, 1], Subscript[x, 2]}, {{f, 0}}, {Automatic},
Automatic, SamplingPeriod -> None], {(| | |
| - | - |
| 1 | 0 |
| 0 | 1 |), (1)}, 1.0, "Design"]Properties related to the input model:
Dataset[Table[{prop, DiscreteLQRegulatorGains[IconizedObject[«sys»], IconizedObject[«wts»], 1.0, prop]}, {prop, IconizedObject[«props»]}]]Get the controller data object:
𝒸𝒹 = DiscreteLQRegulatorGains[IconizedObject[«sspec»], IconizedObject[«wts»], 1.0, "Data"]𝒸𝒹["Properties"]𝒸𝒹["DiscreteTimeClosedLoopPoles"]Tracking (4)
Design a discrete-time tracking controller:
sspec = <|"InputModel" -> StateSpaceModel[{{{0, 7}, {-1, -6}}, {{0}, {1}}, {{5, 0}}, {{0}}}, SamplingPeriod -> None,
SystemsModelLabels -> None], "TrackedOutputs" -> 1|>;𝒸𝒹 = DiscreteLQRegulatorGains[sspec, {(| | | |
| --- | - | --- |
| 100 | 0 | 0 |
| 0 | 1 | 0 |
| 0 | 0 | 0.5 |), (1)}, 0.75, "Data"]The closed-loop system tracks the reference signal ![]() :
:
OutputResponse[𝒸𝒹["DiscreteTimeClosedLoopSystem"], ref = Table[1, 30]];
ListStepPlot[{ref, %[[1]]}, IconizedObject[«plotOpts»]]A block diagram of the closed-loop system:
𝒸𝒹["DiscreteTimeBlockDiagram"]sspec = <|"InputModel" -> StateSpaceModel[{{{2., 0}, {0, -2}}, {{1., 0}, {0, 1}}, {{1, 0}, {3., 1}}, {{0, 0}, {0, 0}}},
SamplingPeriod -> None, SystemsModelLabels -> None], "TrackedOutputs" -> {1, 2}|>;𝒸𝒹 = DiscreteLQRegulatorGains[sspec, {(| | | | |
| - | - | --- | --- |
| 1 | 0 | 0 | 0 |
| 0 | 1 | 0 | 0 |
| 0 | 0 | 100 | 0 |
| 0 | 0 | 0 | 100 |), (| | |
| - | - |
| 1 | 0 |
| 0 | 1 |)}, 0.75, "Data"]The closed-loop system tracks two different reference signals:
refs = Table[ConstantArray[RandomInteger[{-12, -4}], 30], 2];
or = OutputResponse[𝒸𝒹["DiscreteTimeClosedLoopSystem"], refs];ListStepPlot[Riffle[refs, or], IconizedObject[«plotOpts»]]Compute the controller effort:
sspec = <|"InputModel" -> StateSpaceModel[{{{0, 1}, {-5, -3}}, {{0}, {1}}, {{5, 0}}, {{0}}}, SamplingPeriod -> None,
SystemsModelLabels -> None], "TrackedOutputs" -> 1|>;𝒸𝒹 = DiscreteLQRegulatorGains[sspec, {(| | | |
| -- | - | -- |
| 10 | 0 | 0 |
| 0 | 1 | 0 |
| 0 | 0 | 10 |), {{1}}}, 1.0, "Data"]cm = 𝒸𝒹["DiscreteTimeControllerModel"]ref = Table[1, 30]dcsys = 𝒸𝒹["DiscreteTimeClosedLoopSystem"];Short[sr = StateResponse[dcsys, {ref}]]Short[or = OutputResponse[dcsys, {ref}]]The controller inputs are computed from the reference inputs, output and state responses:
cinps = Join[{ref}, or, sr];OutputResponse[cm, cinps];
ListStepPlot[%[[1]], PlotRange -> All]Track a desired reference signal:
tSig = Function[{r, t}, r''[t] + 0.5r[t]]The reference signal is of order 2:
m = Max[Join[Cases[tSig[r, t], Derivative[n_][r][t] :> n], {0}]]ref = DSolveValue[{tSig[r, t] == 0, r[0] == 0, r'[0] == 1}, r[t], t]
dref = Table[ref, {t, 0, 20 π, τ = 0.4}];
len = Length[dref]ListStepPlot[dref, DataRange -> {0, τ (len - 1)}]Design a controller that tracks the output of a single output system:
sspec = <|"InputModel" -> StateSpaceModel[{{{-1}}, {{1}}, {{1}}, {{0}}}, SamplingPeriod -> None, SystemsModelLabels -> None], "TrackedOutputs" -> 1, "TrackedSignal" -> tSig|>;{q, k} = {Length[sspec["TrackedOutputs"]], SystemsModelOrder[sspec["InputModel"]]}The dimensions of the state weighting matrix qq is k+m q:
{qq, rr} = {(| | | |
| - | --- | - |
| 1 | 0 | 0 |
| 0 | 100 | 0 |
| 0 | 0 | 1 |), {{0.01}}};
Join[Dimensions[qq], {k + m q}]𝒸𝒹 = DiscreteLQRegulatorGains[sspec, {qq, rr}, τ, "Data"]The closed-loop system tracks the reference:
or = OutputResponse[𝒸𝒹["DiscreteTimeClosedLoopSystem"], dref][[1]];ListStepPlot[{dref, or}, PlotRange -> All, PlotStyle -> {Dashing[{Small, Small}], Automatic}, PlotLegends -> {"ref.", "actual"}, DataRange -> {0, τ (len - 1)}]Applications (12)
Mechanical Systems (5)
Regulate the motion of a spring-mass-damper system with a nonlinear spring:
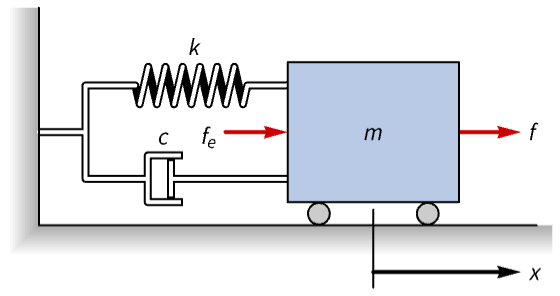
nssm = NonlinearStateSpaceModel[IconizedObject[«eqns»] /. IconizedObject[«pars»], {x[t], v[t]}, {f[t], Subscript[f, e][t]}, {x[t], v[t]}, t]The open-loop response of the cart to a disturbance force fe is unregulated and takes ~40 seconds to settle:
OutputResponse[nssm, {0, 0.1 UnitStep[t]}, {t, 0, 60}];
Plot[%, {t, 0, 60}, PlotLegends -> {x, v}, PlotRange -> All]sspec = <|"InputModel" -> nssm, "FeedbackInputs" -> 1|>;Specify a set of control weights and a sampling time for the controller design:
wts = {DiagonalMatrix[{10, 1}], {{0.1}}};
τ = 0.4;dlqr = DiscreteLQRegulatorGains[sspec, wts, τ, "Data"]Obtain the closed-loop system:
dcsys = dlqr["DiscreteTimeClosedLoopSystem"]The cart's motion is regulated and it settles in ~3 seconds:
or = OutputResponse[{dcsys, {0, 0.1}}, Table[{0, 0}, 20]];
ListStepPlot[%, DataRange -> {0, 19 τ}, PlotRange -> All, PlotLegends -> {x, v}]cm = dlqr["DiscreteTimeControllerModel"]OutputResponse[cm, Join[Table[{0}, 20], or]];
ListStepPlot[%, DataRange -> {0, 19 τ}, PlotRange -> All]Regulate the swinging motion of a spring-pendulum:
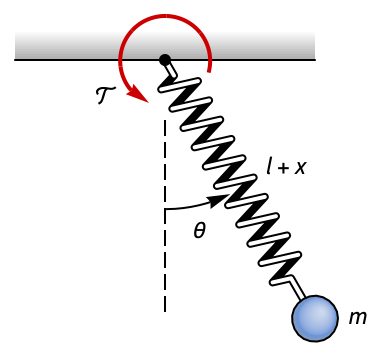
pend = NonlinearStateSpaceModel[IconizedObject[«eqns»] /. IconizedObject[«pars»], {x[t], x'[t], θ[t], θ'[t]}, 𝒯[t], {x[t], θ[t]}, t]The motion of the pendulum is unregulated:
OutputResponse[{pend, {0.1, 0, 0.2, 0}}, {0, 0}, {t, 0, 10}];
Plot[%, {t, 0, 10}, PlotRange -> All, PlotLegends -> {x, θ}]Set the system specifications:
sspec = <|"InputModel" -> pend, "MeasuredOutputs" -> 2|>;Specify a set of control weights and a sampling time for the controller design:
wts = {DiagonalMatrix[{1, 1, 1, 1}], {{1}}};
τ = 0.5;dlqr = DiscreteLQRegulatorGains[sspec, wts, τ, "Data"]Obtain the discrete-time closed-loop system:
dcsys = dlqr["DiscreteTimeClosedLoopSystem"]Only the swinging motion θ is regulated:
sr = StateResponse[{dcsys, {0.1, 0, 0.2, 0}}, Table[{0, 0}, 60]];
ListStepPlot[{%[[1]], %[[3]]}, DataRange -> {0, 59 τ}, IconizedObject[«plotOpts»]]It is not possible to completely control the system:
ControllableModelQ[StateSpaceModel[pend]]cm = dlqr["DiscreteTimeControllerModel"]OutputResponse[cm, Join[Table[{0, 0}, 60], sr]];
ListStepPlot[%, DataRange -> {0, 59 τ}, PlotRange -> All]The zero is unaffected by the controller:
Grid[{Table[PoleZeroPlot[{sys}, ImageSize -> Small], {sys, {dlqr["DiscreteTimeDesignModel"], dcsys}}]}, Spacings -> 2]Dampen the oscillations of a rotary pendulum:
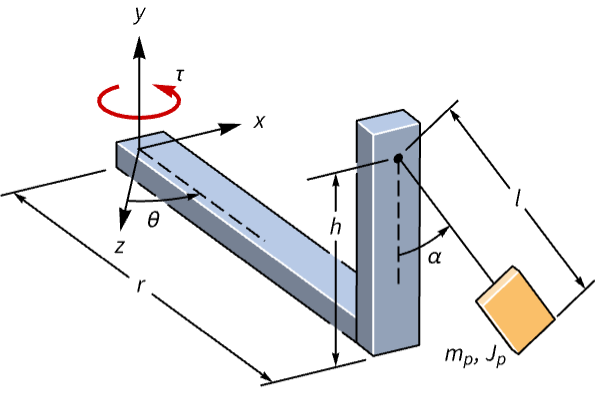
pend = NonlinearStateSpaceModel[IconizedObject[«eqns»] /. IconizedObject[«pars»], {θ[t], α[t], θ'[t], α'[t]}, Subscript[v, m][t], {θ[t], α[t]}, t]//Chop//FullSimplifyThe open-loop response to a perturbation is oscillatory:
OutputResponse[{pend, {0.3, 0.2}}, 0, {t, 0, 300}];
Plot[%, {t, 0, 100}, PlotRange -> All, PlotLegends -> {θ, α}]Specify a set of control weights and a sampling time:
wts = {DiagonalMatrix[{10^2, 10^4, 10, 10}], {{1}}};
τ = 0.1;Compute the discrete-time LQR:
dlqr = DiscreteLQRegulatorGains[pend, wts, τ, "Data"]Obtain the closed-loop system:
dcsys = dlqr["DiscreteTimeClosedLoopSystem"]The oscillations are damped by the controller:
sr = StateResponse[{dcsys, {0.3, 0.2}}, Table[0, 150 ]];
ListStepPlot[%[[{1, 2}]], DataRange -> {0, 149 τ}, IconizedObject[«plotOpts»]]The discrete-time controller model:
dcm = dlqr["DiscreteTimeControllerModel"]OutputResponse[dcm, Join[{Table[0, 150 ]}, sr]];
ListStepPlot[%, DataRange -> {0, 149 τ}, PlotRange -> All]Keep a ball-bot robot upright:
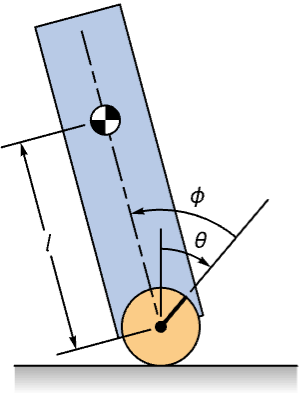
bbot = NonlinearStateSpaceModel[IconizedObject[«eqns»] /. IconizedObject[«pars»], {θ[t], ϕ[t], θ'[t], ϕ'[t]}, {Subscript[𝒯, 1][t], Subscript[𝒯, 2][t]}, {θ[t], ϕ[t]}, t]//Chop//SimplifyWithout a controller, the robot tips over:
or = OutputResponse[{bbot, {0, 0.15, 0, 0}}, {0, 0}, {t, 0, 10}];Table[Plot[ℴ𝓇[[1]], {t, 0, 10}, IconizedObject[«plotOpts»]], {ℴ𝓇, ({or, {θ, ϕ}})}]Specify a set of regulator weights and a sampling time:
wts = {10(| | | | |
| - | - | - | - |
| 5 | 0 | 0 | 0 |
| 0 | 5 | 0 | 0 |
| 0 | 0 | 1 | 0 |
| 0 | 0 | 0 | 1 |), 0.1(| | |
| - | - |
| 1 | 0 |
| 0 | 1 |)};
τ = 0.1;dlqr = DiscreteLQRegulatorGains[bbot, wts, τ, "Data"]Obtain the discrete-time closed-loop system:
dcsys = dlqr["DiscreteTimeClosedLoopSystem"]//SimplifyThe robot returns to the upright position despite an initial disturbance in its states:
sr = StateResponse[{dcsys, {0, 0.15, 0, 0}}, Table[{0, 0}, 60]];
ListStepPlot[{%[[1]], %[[2]]}, DataRange -> {0, 59 τ}, IconizedObject[«plotOpts»]]Obtain the discrete-time controller model:
cm = dlqr["DiscreteTimeControllerModel"]//SimplifyOutputResponse[cm, Join[Table[{0, 0}, 60], sr]];
ListStepPlot[%, DataRange -> {0, 59 τ}, IconizedObject[«plotOpts»]]Make a toy train stop at stations using a tracking controller:
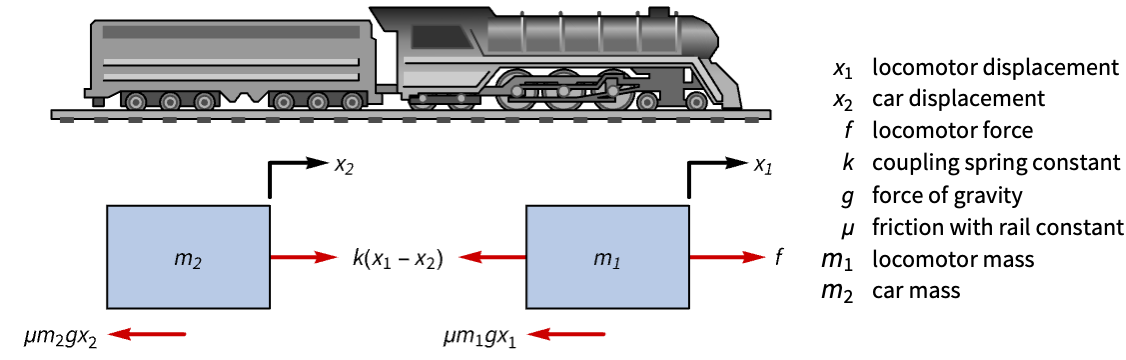
train = StateSpaceModel[IconizedObject[«eqns»] /. IconizedObject[«pars»], {Subscript[x, 1][t], Subscript[x, 2][t], Subscript[x, 1]'[t], Subscript[x, 2]'[t]}, f[t], {Subscript[x, 1][t], Subscript[x, 2][t]}, t, IconizedObject[«labels»]]A displacement of the train's locomotive's position ![]() will cause unregulated oscillations:
will cause unregulated oscillations:
OutputResponse[{train, {0.1, 0, 0, 0}}, 0, {t, 0, 100}];
Plot[%, {t, 0, 30}, PlotRange -> All, PlotLegends -> {Subscript[x, 1], Subscript[x, 2]}]This is because its open-loop poles are lightly damped:
Eigenvalues[First@Normal@train]//ChopThe train's route modeled as a piecewise function:
tSig = Table[Splice[ConstantArray[i, 40]], {i, {2, 5, 9}}];
tSigPlot = ListStepPlot[%, IconizedObject[«plotOpts»]]Specify the position of the train's locomotive as the tracked output:
sspec = <|"InputModel" -> train, "TrackedOutputs" -> 1|>;Specify a set of control weights and a sampling period:
wts = {DiagonalMatrix[{1, 1, 1, 1, 1}], {{0.1}}};
τ = 0.2;dlqr = DiscreteLQRegulatorGains[sspec, wts, τ, "Data"]Obtain the closed-loop system:
dcsys = dlqr["DiscreteTimeClosedLoopSystem"]The train follows the route and makes the 3 stops:
sr = StateResponse[dcsys, tSig];Show[tSigPlot, ListStepPlot[Take[sr, 2], PlotLegends -> {Subscript[x, 1], Subscript[x, 2]}]]The engine and cart velocities during the route:
ListStepPlot[sr[[{3, 4}]], PlotLegends -> {Derivative[1][Subscript[x, 1]], Derivative[1][Subscript[x, 2]]}]Obtain the discrete-time controller model:
dcm = dlqr["DiscreteTimeControllerModel"]cinps = Join[{tSig}, sr[[1 ;; 1]], sr[[1 ;; 4]]];ListStepPlot[OutputResponse[dcm, cinps]]Aerospace Systems (3)
Stabilize an aircraft's pitch:
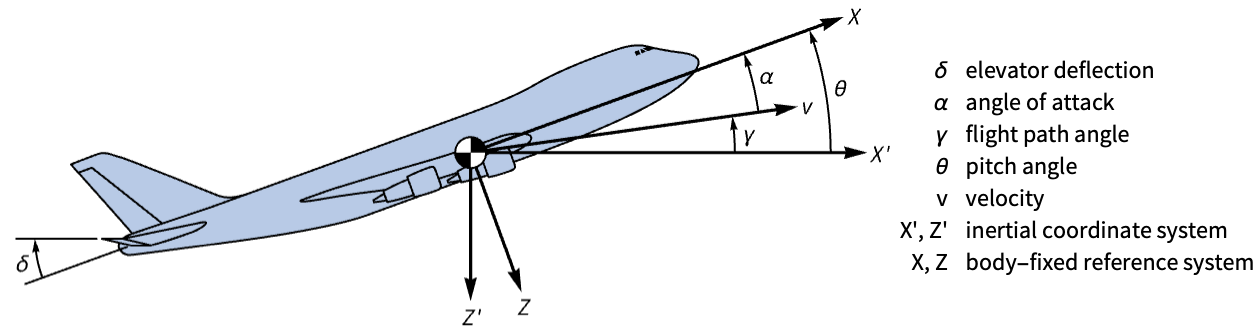
A model of the aircraft's longitudinal dynamics:
ssm = StateSpaceModel[IconizedObject[«eqns»], IconizedObject[«states»], δ[t], θ[t], t, IconizedObject[«labels»]]The aircraft's pitch ![]() is unstable to a step input:
is unstable to a step input:
OutputResponse[{ssm, {0, 0, 0}}, UnitStep[t], {t, 0, 10}];
Plot[%, {t, 0, 10}, PlotRange -> All]This is because there is a pole at the origin of the s plane, making it unstable:
PoleZeroPlot[ssm]Specify a set of control weights and sampling time for the discrete-time LQR controller design:
wts = {DiagonalMatrix[{10, 10, 100}], {{0.1}}};
τ = 0.5;Compute the discrete-time LQR controller:
dlqr = DiscreteLQRegulatorGains[ssm, wts, τ, "Data"]Obtain the discrete-time closed-loop system:
dcsys = dlqr["DiscreteTimeClosedLoopSystem"]The discrete-time closed-loop system's poles are within the unit circle, making it stable:
PoleZeroPlot[dcsys]sr = StateResponse[dcsys, Table[1, 30]];
ListStepPlot[sr[[3]], DataRange -> {0, 29 τ}, IconizedObject[«plotOpts»]]Obtain the discrete-time controller model:
cm = dlqr["DiscreteTimeControllerModel"]OutputResponse[cm, Join[{Table[1, 30]}, sr]];
ListStepPlot[%, DataRange -> {0, 29 τ}, IconizedObject[«plotOpts»]]Regulate the orbit of a satellite with a thruster failure:
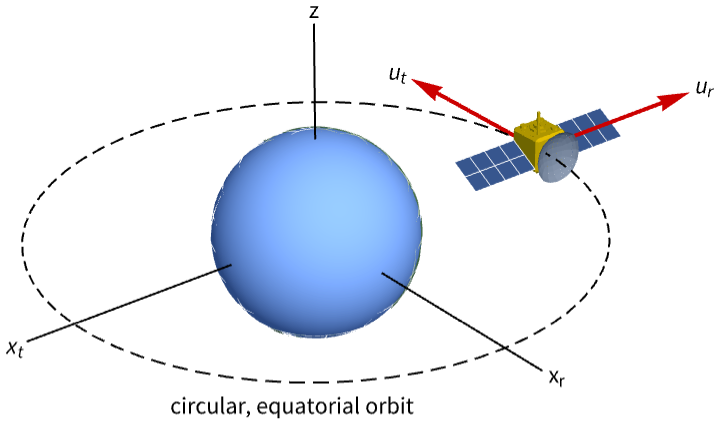
A model of the satellite's orbital dynamics:
sat = StateSpaceModel[IconizedObject[«abc»], IconizedObject[«labels»]] /. ω -> 0.0011Without corrective thruster inputs, a perturbation in the states will cause the satellite's orbit to deviate:
OutputResponse[{sat, {0, -1, 0, 1}}, {0, 0}, {t, 0, 10800}];
Plot[%, {t, 0, 10800}, PlotRange -> All, PlotLegends -> {Subscript[x, r], Subscript[x, t]}]The orbit is controllable if the tangential thrusters fail, but not if the radial thrusters fail:
Table[ControllableModelQ[SystemsModelExtract[sat, i]], {i, 2}]Set the system specification to control the satellite using only the tangential thrusters:
sspec = <|"InputModel" -> sat, "FeedbackInputs" -> 2|>;Specify a set of control weights and sampling time:
wts = {DiagonalMatrix[{1, 100, 1, 1}], {{1}}};
τ = 0.5;dlqr = DiscreteLQRegulatorGains[sspec, wts, τ, "Data"]Obtain the closed-loop system:
dcsys = dlqr["DiscreteTimeClosedLoopSystem"]The satellite's orbit is regulated using only the tangential thruster:
sr = StateResponse[{dcsys, {0, -1, 0, 1}}, Table[{0, 0}, 5400]];
ListStepPlot[sr[[{1, 3}]], DataRange -> {0, 5399 τ}, IconizedObject[«plotOpts»]]Obtain the discrete-time controller model:
cm = dlqr["DiscreteTimeControllerModel"]OutputResponse[cm, Join[{Table[0, 5400]}, sr]];
ListStepPlot[%, DataRange -> {0, 5399 τ}, IconizedObject[«plotOpts»]]Suppress the fluid slosh disturbance on an accelerating rocket:
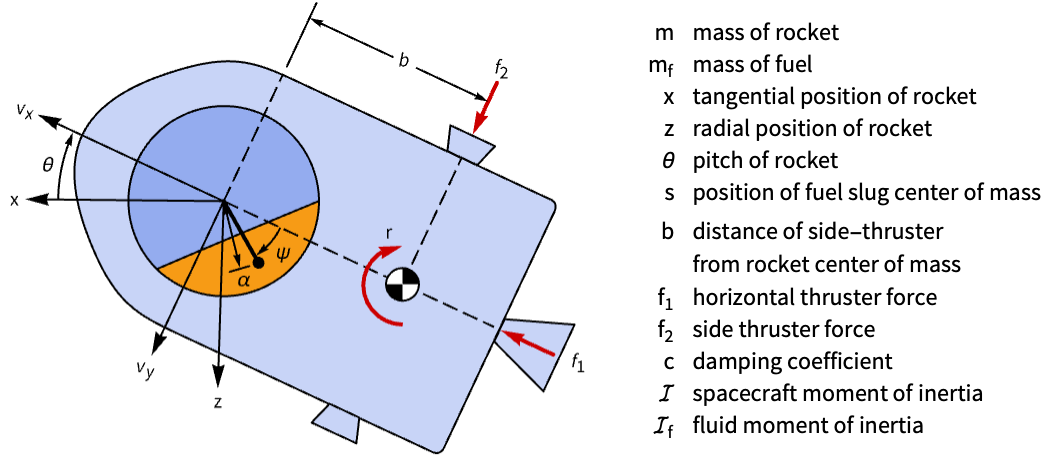
A model of the rocket that approximates the fluid slosh as a swinging pendulum:
assm = AffineStateSpaceModel[IconizedObject[«eqns»] /. IconizedObject[«pars»], IconizedObject[«states»], {𝓇[t], Subscript[𝒻, 1][t], Subscript[𝒻, 2][t]}, {θ[t], ψ[t], ω[t], γ[t]}, t]The sloshing makes the system unstable:
OutputResponse[{assm, {0, 0.25, 0, 0, 0, -1}}, {0, 0, 0}, {t, 0, 60}];
GraphicsRow@Table[Plot[%[[i]], {t, 0, 60}, IconizedObject[«plotOpts»]], {i, 2}]The controllability matrix is not full rank, as only six of the eight states are controllable:
ssm = StateSpaceModel[assm];
cm = ControllabilityMatrix[ssm];{MatrixRank[cm], SystemsModelOrder[ssm]}Determine indices of state pairs that are uncontrollable:
notC = Cases[Subsets[Range[8], {2}], _ ? (ControllableModelQ[SystemsModelDelete[ssm, None, None, #]]&)]Grid[Table[Part[IconizedObject[«states»], i], {i, notC}], Frame -> {True, {True, True, True}}]Obtain a controllable model by deleting the third pair of uncontrollable states:
assmDesign = SystemsModelDelete[assm, None, None, notC[[3]]]A set of control weights and sampling times:
wts = {DiagonalMatrix[{10^7, 10^6, 1, 10^5, 10^5, 10^4}], DiagonalMatrix[{0.75, 1, 0.5}]};
τ = 0.01;Compute a discrete-time LQR controller:
dlqr = DiscreteLQRegulatorGains[assmDesign, wts, τ, "Data"]Obtain the closed-loop system:
dcsys = dlqr[{"DiscreteTimeClosedLoopSystem"}]//Simplify//Chop[#, 10^-5]&The slosh disturbance is suppressed:
sr = StateResponse[{dcsys, {0, 0.25, 0, 0, -1, 0}}, Table[{0, 0, 0}, 2000]];
Table[ListStepPlot[%[[i]], DataRange -> {0, 1999 τ}, IconizedObject[«plotOpts»]], {i, 2}]dcm = dlqr["DiscreteTimeControllerModel"]OutputResponse[dcm, Join[Table[{0, 0, 0}, 2000], sr]];
ListStepPlot[%, DataRange -> {0, 1999 τ}, IconizedObject[«plotOpts»]]Biological Systems (1)
Regulate the concentration of alcohol in the human body:
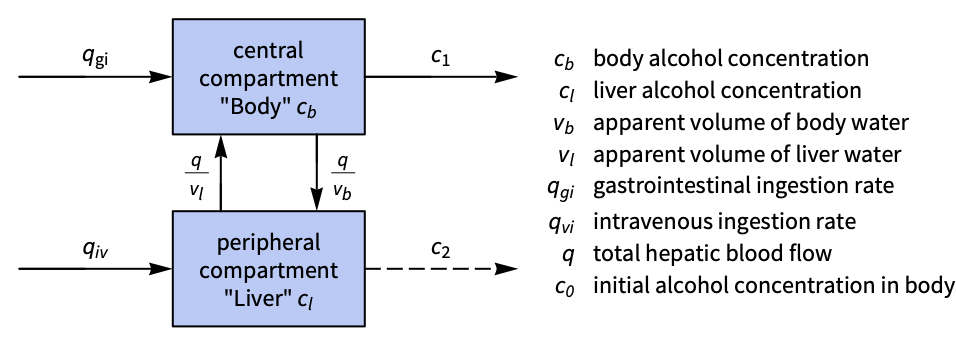
A two-compartment model with gastrointestinal and intravenous inputs:
nssm = NonlinearStateSpaceModel[IconizedObject[«eqns»], {Subscript[c, b][t], Subscript[c, l][t]}, {Subscript[q, gi][t], Subscript[q, iv][t]}, Subscript[c, b][t], t] /. IconizedObject[«pars»]Linearize the system using StateSpaceModel:
ssm = N@StateSpaceModel[nssm, IconizedObject[«labels»]]Without intervention, it takes ![]() for the body to regulate the alcohol concentration:
for the body to regulate the alcohol concentration:
StateResponse[{ssm, {12, 3}}, {0, 0}, {t, 0, 200}];
Table[Plot[𝓈𝓇[[1]], {t, 0, 200}, IconizedObject[«plotOpts»]], {𝓈𝓇, ({%, {Subscript[c, b], Subscript[c, l]}})}]Specify a set of control weights and a sampling time:
wts = {DiagonalMatrix[{10000, 1}], DiagonalMatrix[{10^2, 10^4}]};
τ = 0.5;dlqr = DiscreteLQRegulatorGains[ssm, wts, τ, "Data"]Obtain the discrete-time closed-loop system:
dcsys = dlqr["DiscreteTimeClosedLoopSystem"]//SimplifyThe alcohol concentration is regulated faster:
sr = StateResponse[{dcsys, {12, 3}}, ConstantArray[{0, 0}, 300]];
Table[ListStepPlot[𝓈𝓇[[1]], IconizedObject[«plotOpts»]], {𝓈𝓇, ({%, {Subscript[c, b], Subscript[c, l]}})}]Obtain the discrete-time controller model:
cm = dlqr["DiscreteTimeControllerModel"]OutputResponse[cm, Join[Table[{0, 0}, 300], sr]];
ListStepPlot[%, DataRange -> {0, 299 τ}, IconizedObject[«plotOpts»]]Chemical Systems (1)
Control a fed-batch reactor's biomass concentration:
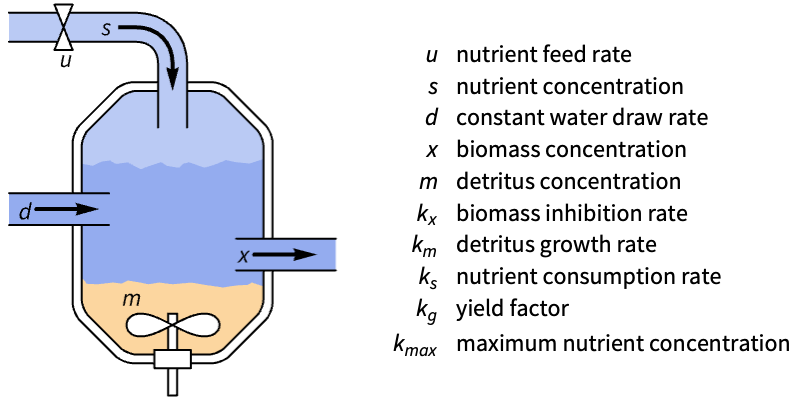
A nonlinear model of the reactor:
nssm = NonlinearStateSpaceModel[IconizedObject[«eqns»], {{x[t], Subscript[x, 0]}, {s[t], Subscript[s, 0]}, {m[t], Subscript[m, 0]}}, u[t], x[t], t] /. IconizedObject[«pars»]The unregulated system's response to a perturbation of the states:
StateResponse[{nssm, {0.75, 0.01, 2}}, 0, {t, 0, 60}];
Plot[%, {t, 0, 60}, PlotRange -> All, PlotLegends -> {x, s, m}]Set the system specification to track the output ![]() :
:
sspec = <|"InputModel" -> nssm, "TrackedOutputs" -> 1|>;And specify a set of control weights and sampling period:
wts = {DiagonalMatrix[{10, 1, 1, 10^2}], {{300}}};
τ = 0.2;dlqr = DiscreteLQRegulatorGains[sspec, wts, τ, "Data"]Obtain the discrete-time closed-loop system:
dcsys = dlqr["DiscreteTimeClosedLoopSystem"]Simulate the system, tracking a constant biomass concentration of 1.25:
Subscript[x, ref] = 1.25;sr = StateResponse[{dcsys, {0.75, 0, 2}}, Table[Subscript[x, ref], 300]];ListStepPlot[sr[[1]], IconizedObject[«plotOpts»]]cm = dlqr["DiscreteTimeControllerModel"]cinps = Join[{Table[Subscript[x, ref], 300], sr[[1]]}, sr[[1 ;; 3]]];
ListStepPlot[OutputResponse[cm, cinps], PlotRange -> All]Electrical Systems (1)
Improve the disturbance rejection of a permanent magnet synchronous motor (PMSM):
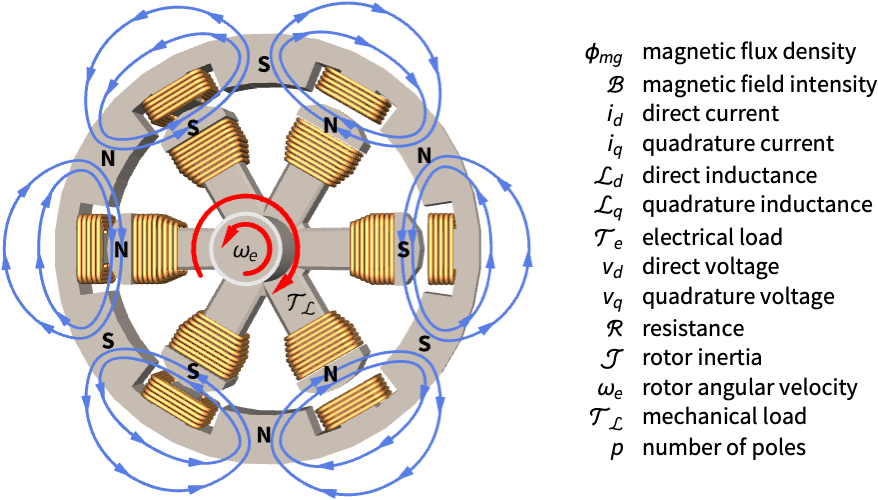
pmsm = NonlinearStateSpaceModel[IconizedObject[«eqns»] /. IconizedObject[«pars»], {Subscript[i, d][t], Subscript[i, q][t], Subscript[ω, e][t]}, {Subscript[v, d][t], Subscript[v, q][t], Subscript[𝒯, ℒ][t]}, Subscript[ω, e][t], t]//SimplifyIt takes around ![]() to settle to a step-input disturbance:
to settle to a step-input disturbance:
OutputResponse[pmsm, {0, 0, UnitStep[t - 1]}, {t, 0, 1500}];
Plot[%, {t, 0, 1500}, PlotRange -> All]Set the control system specifications:
sspec = <|"InputModel" -> pmsm, "FeedbackInputs" -> {1, 2}|>;Specify a sampling period and a set control weights for a maximum control effort of 24v:
τ = (1/60.0);
wts = {DiagonalMatrix[{1, 1, 1000}], DiagonalMatrix[{(1/24^2), (1/24^2)}]};dlqr = DiscreteLQRegulatorGains[sspec, wts, τ, "Data"]Obtain the closed-loop system:
dcsys = dlqr["DiscreteTimeClosedLoopSystem"]//ChopThe closed-loop system takes ~5 seconds to settle to a step-input disturbance:
sr = StateResponse[dcsys, Table[{0, 0, 1}, 1000]];
ListStepPlot[sr[[3]], DataRange -> {0, 999 τ}, PlotRange -> All]Obtain the discrete-time controller model:
cm = dlqr["DiscreteTimeControllerModel"]The control effort is within the ±24v range:
OutputResponse[cm, Join[Table[{0, 0}, 1000], sr]];
ListStepPlot[%, DataRange -> {0, 999 τ}, IconizedObject[«plotOpts»]]Marine Systems (1)
Control the depth and pitch of a submarine:
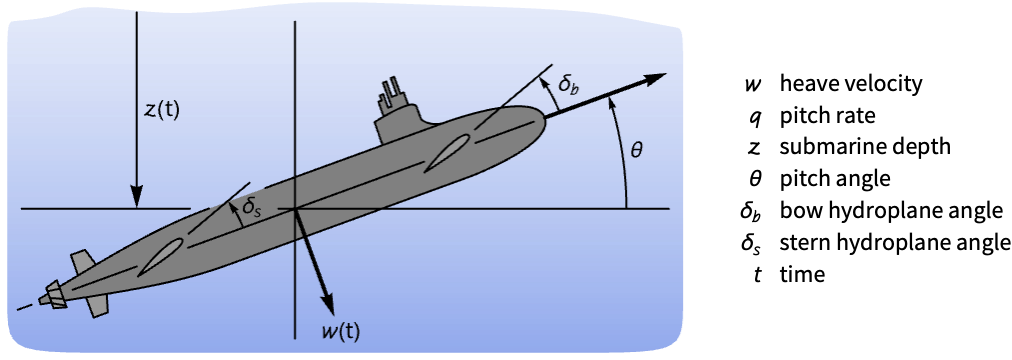
submarine = StateSpaceModel[IconizedObject[«abcd»], IconizedObject[«labels»]]Without a controller, the submarine's pitch and depth are unstable to a disturbance in the states:
OutputResponse[{submarine, {1, 0, 0.5, 0.2}}, {0, 0}, {t, 0, 20}];
Table[Plot[ℴ𝓇[[1]], {t, 0, 20}, IconizedObject[«plotOpts»]], {ℴ𝓇, ({%, {𝓏, θ}})}]Set the depth ![]() and pitch
and pitch ![]() , which are outputs 1 and 2, as tracked outputs:
, which are outputs 1 and 2, as tracked outputs:
sspec = <|"InputModel" -> submarine, "TrackedOutputs" -> {1, 2}|>;Specify a set of control weights and a sampling period:
wts = {DiagonalMatrix[{5, 5, 10, 10, 10^3, 10^3}], 10^3IdentityMatrix[2]};
τ = 0.2;Compute the discrete-time LQR controller:
dlqr = DiscreteLQRegulatorGains[sspec, wts, τ, "Data"]Obtain the closed-loop system:
dcsys = dlqr["DiscreteTimeClosedLoopSystem"]The submarine tracks the reference depth of –10 and the pitch angle ![]() of 0:
of 0:
sr = StateResponse[dcsys, Table[{-10, 0}, 750]];
Table[ListStepPlot[𝓈𝓇[[1]], IconizedObject[«plotOpts»]], {𝓈𝓇, ({sr[[3 ;; 4]], {𝓏, θ}})}]cm = dlqr["DiscreteTimeControllerModel"]The inputs to the controller model:
cinps = Join[Table[{-10, 0}, 750], sr[[{3, 4, 1, 2, 3, 4}]]];ListStepPlot[OutputResponse[cm, cinps], IconizedObject[«plotOpts»]]Properties & Relations (5)
DiscreteLQRegulatorGains is computed as the gains for an emulated discrete-time system:
ssm = StateSpaceModel[{a = (| | |
| - | --- |
| 0 | 1 |
| 0 | -10 |), b = (| |
| - |
| 0 |
| 1 |), c = (1 0)}]A set of weights and a sampling period for the continuous-time model:
{{q, r}, τ} = {{(| | |
| -- | - |
| 10 | 0 |
| 0 | 0 |), (1)}, 0.1};The emulated discrete-time system:
ssmd = ToDiscreteTimeModel[ssm, τ, Method -> "ZeroOrderHold"]The state weight matrix for the emulated system:
ϕ = Subsuperscript[∫, 0, τ]MatrixExp[a t].q.MatrixExp[a t]ⅆtρ = Subsuperscript[∫, 0, τ](r + (Subsuperscript[∫, 0, t]MatrixExp[a η].bⅆη).q.Subsuperscript[∫, 0, t]MatrixExp[a η].bⅆη)ⅆtThe cross-coupling weight matrix:
ψ = Subsuperscript[∫, 0, τ]MatrixExp[a t].q.(Subsuperscript[∫, 0, t]MatrixExp[a η].bⅆη) ⅆtThe discrete LQ gains using the emulated system and weights:
LQRegulatorGains[ssmd, {ϕ, ρ, ψ}]DiscreteLQRegulatorGains gives the same result:
DiscreteLQRegulatorGains[ssm, {q, r}, τ]The discrete-time system is an approximation of the sampled-data system:
eqns = {Derivative[1][Subscript[x, 1]][t] == Subscript[x, 2][t], u[t] == -2 Subscript[x, 1][t] + Subscript[x, 2][t] + Derivative[1][Subscript[x, 2]][t]};
states = {Subscript[x, 1][t], Subscript[x, 2][t]};ssm = StateSpaceModel[eqns, states, u[t], Subscript[x, 1][t], t]The controller data for a set of weights and sampling periods:
τ = 0.4;
cd = DiscreteLQRegulatorGains[ssm, {(| | |
| - | - |
| 1 | 0 |
| 0 | 1 |), {{1}}}, τ, "Data"]The approximate discrete-time closed-loop system:
dcsys = cd["DiscreteTimeClosedLoopSystem"]Its state response for initial conditions ![]() :
:
sr = StateResponse[{dcsys, {1, -1}}, Table[0, 10 / τ]];
p = ListStepPlot[%, IconizedObject[«plotOpts»]]The discrete-time feedback law:
fb = WhenEvent@@{Mod[t, τ] == 0, u[t] -> First[-cd["FeedbackGains"].states]}The equations of the sampled-data system for initial conditions ![]() :
:
ceqns = Join[eqns, {Subscript[x, 1][0] == 1, Subscript[x, 2][0] == -1, u[0] == 0}, {fb}]The state response of the sampled-data system:
NDSolve[ceqns, Join[states, {u[t]}], {t, 0, 7}, DiscreteVariables -> u[t]];
csols = First[states /. %]Compare the approximate discrete and sampled-data responses:
Legended[Show[Plot[csols, {t, 0, 7}, IconizedObject[«plotOpts»]], p], IconizedObject[«lineLegend»]]Decreasing the sampling period better approximates the sampled-data system:
τ = {0.4, 0.1, 0.025};The discrete-time closed-loop systems and feedback gains for the various ![]() :
:
{dcsys, κ} = Table[DiscreteLQRegulatorGains[IconizedObject[«ssm»], IconizedObject[«wts»], i, IconizedObject[«props»]], {i, τ}];Grid[{dcsys, κ}, IconizedObject[«gridOpts»]]The state responses for the initial condition ![]() :
:
sr = Table[StateResponse[{dcsys[[i]], {1, -1}}, Table[0, 8 / τ[[i]]]], {i, 3}];
p = Table[ListStepPlot[sr[[i, k]], DataRange -> {0, 8}, IconizedObject[«plotOpts»]], {i, 3}, {k, 2}]The state responses of the sampled-data systems:
sols = Table[NDSolve[{IconizedObject[«ssmEqns»], Subscript[x, 1][0] == 1, Subscript[x, 2][0] == -1, u[0] == 0, WhenEvent[Mod[t, τ[[i]]] == 0, u[t] -> -First[κ[[i]].IconizedObject[«states»]]]}, Join[IconizedObject[«states»], {u[t]}], {t, 0, 8}, DiscreteVariables -> u[t]], {i, 3}];Shallow[xSols = Table[First[IconizedObject[«states»] /. %[[i]]], {i, 3}]]As the sampling period decreases, the difference between the systems' responses also decreases:
Table[Legended[Show[Plot[Evaluate@xSols[[i, k]], {t, 0, 8}, IconizedObject[«plotOpts»]], p[[i, k]]], IconizedObject[«leg»]], {i, 3}, {k, 2}];
Grid[%, Spacings -> {2.5, 1}]Decreasing the sampling period gives a better approximation of the sampled-data system's control effort:
τ = {0.4, 0.1, 0.025};The state responses of the discrete-time system from the previous example:
Short[sr = IconizedObject[«sr»]]The state responses of the sample data system from the same example:
Short[sols = IconizedObject[«sols»]]dcm = Table[DiscreteLQRegulatorGains[IconizedObject[«ssm»], IconizedObject[«wts»], i, "DiscreteTimeControllerModel"], {i, τ}]The control signals for initial condition ![]() :
:
ce = Table[OutputResponse[dcm[[i]], Join[{Table[0, 8 / τ[[i]]]}, sr[[i]]]], {i, 3}];
p = Table[ListStepPlot[ce[[i]], DataRange -> {0, 8}, IconizedObject[«plotOpts»]], {i, 3}]The sampled-data system's control effort:
csols = Table[First[{u[t]} /. sols[[i]]], {i, 3}]As the sampling period decreases, the difference between the systems' control effort also decreases:
Grid[{Table[Legended[Show[Plot[csols[[i]], {t, 0, 8}, IconizedObject[«plotOpts»]], p[[i]]], IconizedObject[«leg»]], {i, 3}]}, Spacings -> 2]Decreasing the sampling period results in closed-loop poles closer to the unit circle, i.e. closer to instability:
τ = {0.4, 0.1, 0.025};The discrete-time closed-loop systems:
dcsys = Table[DiscreteLQRegulatorGains[IconizedObject[«ssm»], IconizedObject[«wts»], i, "DiscreteTimeClosedLoopSystem"], {i, τ}]As the sampling period decreases, the system is less stable:
Table[Eigenvalues@First@Normal[dcsys[[i]]], {i, 3}];
Grid[{{"τ = 0.4", "τ = 0.1", "τ = 0.025"}, %}, IconizedObject[«gridOpts»]]Possible Issues (1)
It is not possible to compute an optimal regulator for a system that is not stabilizable:
ssm = StateSpaceModel[{{{-3, 1}, {0, 2}}, {{1}, {0}}, {{1, 0}, {0, 1}}, {{0}, {0}}},
SamplingPeriod -> None, SystemsModelLabels -> None];DiscreteLQRegulatorGains[ssm, {(| | |
| - | -- |
| 1 | 0 |
| 0 | 1. |), (1)}, 1]The system is not stabilizable because the unstable pole 2 is also uncontrollable:
Table[{λ, ControllableModelQ[{ssm, λ}]}, {λ, Eigenvalues[Normal[ssm][[1]]]}]Text
Wolfram Research (2010), DiscreteLQRegulatorGains, Wolfram Language function, https://reference.wolfram.com/language/ref/DiscreteLQRegulatorGains.html (updated 2021).
CMS
Wolfram Language. 2010. "DiscreteLQRegulatorGains." Wolfram Language & System Documentation Center. Wolfram Research. Last Modified 2021. https://reference.wolfram.com/language/ref/DiscreteLQRegulatorGains.html.
APA
Wolfram Language. (2010). DiscreteLQRegulatorGains. Wolfram Language & System Documentation Center. Retrieved from https://reference.wolfram.com/language/ref/DiscreteLQRegulatorGains.html