

ParallelDo
ParallelDo[expr,{imax}]
evaluates expr in parallel imax times.
ParallelDo[expr,{i,imax}]
evaluates expr in parallel with the variable i successively taking on the values 1 through imax (in steps of 1).
ParallelDo[expr,{i,imin,imax}]
starts with i=imin.
ParallelDo[expr,{i,imin,imax,di}]
uses steps di.
ParallelDo[expr,{i,{i1,i2,…}}]
uses the successive values i1, i2, ….
ParallelDo[expr,{i,imin,imax},{j,jmin,jmax},…]
evaluates expr looping in parallel over different values of j, etc. for each i.
Details and Options


- ParallelDo is a parallel version of Do that automatically distributes different evaluations of expr among different kernels and processors.
- If side effects involve unshared variables, they will in general work differently than in Do.
- Parallelize[Do[expr,iter, …]] is equivalent to ParallelDo[expr,iter,…].
- The following options can be given:
-
Method Automatic granularity of parallelization DistributedContexts $DistributedContexts contexts used to distribute symbols to parallel computations ProgressReporting $ProgressReporting whether to report the progress of the computation - The Method option specifies the parallelization method to use. Possible settings include:
-
"CoarsestGrained" break the computation into as many pieces as there are available kernels "FinestGrained" break the computation into the smallest possible subunits "EvaluationsPerKernel"->e break the computation into at most e pieces per kernel "ItemsPerEvaluation"->m break the computation into evaluations of at most m subunits each Automatic compromise between overhead and load balancing - Method->"CoarsestGrained" is suitable for computations involving many subunits, all of which take the same amount of time. It minimizes overhead, but does not provide any load balancing.
- Method->"FinestGrained" is suitable for computations involving few subunits whose evaluations take different amounts of time. It leads to higher overhead, but maximizes load balancing.
- The DistributedContexts option specifies which symbols appearing in expr have their definitions automatically distributed to all available kernels before the computation.
- The default value is DistributedContexts:>$DistributedContexts with $DistributedContexts:=$Context, which distributes definitions of all symbols in the current context, but does not distribute definitions of symbols from packages.
- The ProgressReporting option specifies whether to report the progress of the parallel computation.
- The default value is ProgressReporting:>$ProgressReporting.
Examples
open all close allBasic Examples (3)
ParallelDo works like Do, but in parallel:
No results are returned by ParallelDo:
Use a shared variable to communicate results found to the master kernel:
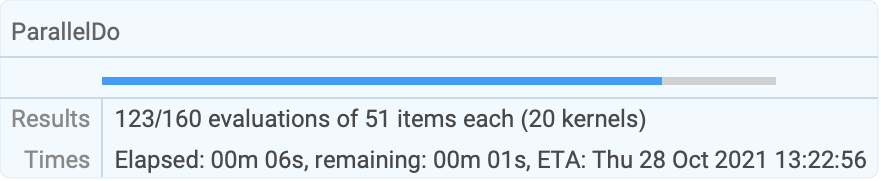
| |
Options (9)
Method (2)
DistributedContexts (5)
By default, definitions in the current context are distributed automatically:
Do not distribute any definitions of functions:
Distribute definitions for all symbols in all contexts appearing in a parallel computation:
Distribute only definitions in the given contexts:
Restore the value of the DistributedContexts option to its default:
ProgressReporting (2)
Do not show a temporary progress report:
Use Method"FinestGrained" for the most accurate progress report:
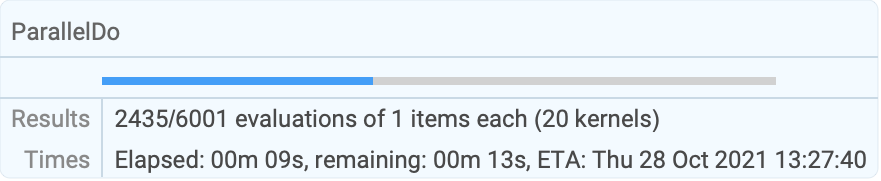
| |
Applications (1)
Properties & Relations (2)
ParallelDo performs the same iterations as ParallelTable, but does not return the values:
Possible Issues (2)
Text
Wolfram Research (2008), ParallelDo, Wolfram Language function, https://reference.wolfram.com/language/ref/ParallelDo.html (updated 2021).
CMS
Wolfram Language. 2008. "ParallelDo." Wolfram Language & System Documentation Center. Wolfram Research. Last Modified 2021. https://reference.wolfram.com/language/ref/ParallelDo.html.
APA
Wolfram Language. (2008). ParallelDo. Wolfram Language & System Documentation Center. Retrieved from https://reference.wolfram.com/language/ref/ParallelDo.html