

TextRecognize
TextRecognize[image]
recognizes text in image and returns it as a string.
TextRecognize[image,level]
returns a list of strings at the specified structural level.
TextRecognize[image,level,prop]
returns prop for text at the given level.
TextRecognize[video,…]
recognizes text in frames of video.
Details and Options




- Text recognition, also known as OCR, is the process of detecting text in an image and converting it to text. It is typically used to extract text from scanned books, pictures of documents and more.
- TextRecognize works with arbitrary grayscale and multichannel images, operating on the intensity value of each pixel.
- TextRecognize[{image1,image2,…}] returns recognition for all imagei.
- By default, the recognized text is returned as a single string for the whole image. Recognized text can be split into levels.
- Structural elements specified in level include:
-
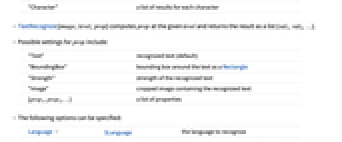
Automatic text found in the whole image as a single string (default) "Block" a list of results for each block of text "Line" a list of results for each line "Word" a list of results for each word "Character" a list of results for each character - TextRecognize[image,level,prop] computes prop at the given level and returns the result as a list {val1,val2,…}.
- Possible settings for prop include:
-
"BoundingBox" bounding box around the text as a Rectangle "Confidence" strength of the recognized text "Image" cropped image containing the recognized text "Text" recognized text (default) {prop1,prop2,…} a list of properties - The following options can be specified:
-
Language $Language the language to recognize Masking All the region of interest that includes text Method Automatic the method to use RecognitionPrior Automatic assumption about text in each masked area - TextRecognize accepts a Language option. By default, Language:>$Language is used. Using Language->{lang1,lang2,…} can be used to perform multi-language recognition.
- The following Language settings can be used:
-

- By default, the text found anywhere in the image is returned. Use Masking to specify the region of interest. Possible settings include:
-
All all of the image mask a single region of interest {mask1,mask2,…} multiple regions of interest - Possible settings for Method, specifying the type of document, include:
-
Automatic automatic choice of the method "Document" optimized for detection in scanned documents "NaturalScene" optimized for detection in natural scene images - Possible settings for Method, specifying the engine, include:
-
Automatic automatic choice of the method "EasyOCR" optimized for scanned documents "OperatingSystem" using the operating system (macOS only) "Tesseract" optimized for scanned documents - RecognitionPrior makes an assumption about the kind of text present in the whole image or in each masked area. Possible settings include:
-
Automatic automatic structure recognition (default) "Column" a single column of text "Line" a single line of text "Word" a single word "Character" a single character "SparseText" text in no particular structure - TextRecognize uses machine learning. Its methods, training sets and biases included therein may change and yield varied results in different versions of the Wolfram Language.
- TextRecognize may download resources that will be stored in your local object store at $LocalBase, and that can be listed using LocalObjects[] and removed using ResourceRemove.
Examples
open all close allBasic Examples (2)
Scope (14)
Basic Uses (5)
Levels (5)
Properties (4)
By default, the recognized text is returned as a string:
The bounding box containing the recognized text:
The strength of the recognition:
The image containing the recognized text:
The subimages containing each word:
Get the recognized text and its strength for each word:
Get the images of the recognized text per line:
Construct a dataset from multiple properties of the recognized text per word:
Options (11)
Language (4)
The default recognition language is $Language:
Specify the language of the text to recognize:
Masking (1)
Method (3)
Applications (7)
Perform a frequency analysis on the recognized text:
Visualize the result, highlighting the less frequent words:
Use LanguageIdentify to identify the language of some recognized text:
Use the identified language to improve the OCR result:
Format the recognized text to interactively show the definition of each word:
Split the text to have all the words separated:
Keep the text content structure, including spaces and punctuation signs, for further reconstruction:
Write a function to look up a word's definition in the dictionary:
Apply the function to the words present in the extracted text:
Recombine the text in a single cell:
Recognize characters in a geometrical diagram:
Specify the regions that contain text:
Extract some properties and highlight them on the image:
Highlight each character with the recognized text and strength:
Recognize lines of text and their corresponding bounding boxes:
Highlight the bounding box of each recognized line using a tooltip for each box:
Recognize, group and highlight all occurrences of a single word in an image:
Properties & Relations (2)
Possible Issues (8)
Rotated text may not be recognized correctly:
Text of different colors may not be recognized:
The quality of recognized text may improve by processing the image:
Fonts smaller than a certain size cannot be recognized:
The quality of recognized text may improve by enlarging the image:
When recognizing formatted numbers, whitespace may cause OCR errors:
Text of different colors may not be fully recognized:
Some color adjustments and upsampling might help improve the recognition result:
Text given as outlines cannot be recognized properly:
Fill the background to improve the result:
Text surrounded by some non-textual content may not be properly recognized:
Specifying the content type might improve the recognition result:
Sometimes small text in a large image is not recognized:
Specify the regions that contain text to improve recognition:
Text
Wolfram Research (2010), TextRecognize, Wolfram Language function, https://reference.wolfram.com/language/ref/TextRecognize.html (updated 2025).
CMS
Wolfram Language. 2010. "TextRecognize." Wolfram Language & System Documentation Center. Wolfram Research. Last Modified 2025. https://reference.wolfram.com/language/ref/TextRecognize.html.
APA
Wolfram Language. (2010). TextRecognize. Wolfram Language & System Documentation Center. Retrieved from https://reference.wolfram.com/language/ref/TextRecognize.html