NIntegrate Integration Strategies
Introduction
An integration strategy is an algorithm that attempts to compute integral estimates that satisfy user-specified precision or accuracy goals.
An integration strategy normally prescribes how to manage and create new elements of a set of disjoint subregions of the initial integral region. Each subregion might have its own integrand and integration rule associated with it. The integral estimate is the sum of the integral estimates of all subregions. Integration strategies use integration rules to compute the subregion integral estimates. An integration rule samples the integrand at a set of points, called sampling points (or abscissas).
To improve an integral estimate the integrand should be sampled at additional points. There are two principal approaches: (i) adaptive strategies try to identify the problematic integration areas and concentrate the computational effort (i.e. sampling points) on them; (ii) non-adaptive strategies increase the number of sampling points over the whole region in order to compute a higher-degree integration rule estimate that reuses the integrand evaluations of the former integral estimate.
Both approaches can use symbolic preprocessing and variable transformation or sequence summation acceleration to achieve faster convergence.
"Adaptive Strategies" gives a general description of the adaptive strategies. The default (main) strategy of NIntegrate is "GlobalAdaptive", which is explained in "Global Adaptive Strategy". Complementary to it is the local adaptive strategy, which is explained in "Local Adaptive Strategy". Both adaptive strategies use singularity handling mechanisms, which are explained in "Singularity Handling".
The Monte Carlo strategies are explained in "Crude Monte Carlo and Quasi Monte Carlo Strategies" and "Global Adaptive Monte Carlo and Quasi Monte Carlo Strategies".
| "GlobalAdaptive" | any integrand, adaptive sampling, rule-based |
| "LocalAdaptive" | any integrand, adaptive sampling, rule-based |
| "DoubleExponential" | any integrand, uniform sampling |
| "Trapezoidal" | any integrand, uniform sampling |
| "MultiPeriodic" | multidimensional integrand, uniform sampling |
| "MonteCarlo" | any integrand, uniform random sampling |
| "QuasiMonteCarlo" | any integrand, uniform quasi-random sampling |
| "AdaptiveMonteCarlo" | any integrand, adaptive random sampling |
| "AdaptiveQuasiMonteCarlo" | any integrand, adaptive quasi-random sampling |
| "DoubleExponentialOscillatory" | one-dimensional infinite-range oscillatory integrand |
| "ExtrapolatingOscillatory" | one-dimensional infinite-range oscillatory integrand |
NIntegrate integration strategies.
NIntegrate uses certain "preprocessor" strategies for special types of integrals (or integrands). These are explained in "Duffy's Coordinates Strategy", "Oscillatory Strategies", and "Cauchy Principal Value Integration". Preprocessor strategies also handle symbolic preprocessing of the integrand.
| "SymbolicPreprocessing" | overall preprocessor controller |
| "EvenOddSubdivision" | simplify even and odd integrands |
| "InterpolationPointsSubdivision" | subdivide integrands containing interpolating functions |
| "OscillatorySelection" | detect oscillatory integrands and select suitable methods |
| "SymbolicPiecewiseSubdivision" | subdivide integrands containing piecewise functions |
| "UnitCubeRescaling" | rescale multidimensional integrand to unit cube |
| "DuffyCoordinates" | multidimensional singularity-removing transformation |
| "PrincipalValue" | numerical integral equivalent to Cauchy principal value |
NIntegrate preprocessor strategies.
Adaptive Strategies
Adaptive strategies try to concentrate computational efforts where the integrand is discontinuous or has some other kind of singularity. Adaptive strategies differ by the way they partition the integration region into disjoint subregions. The integral estimates of each subregion contribute to the total integral estimate.
The basic assumption for the adaptive strategies is that for given integration rule ![]() and integrand
and integrand ![]() , if an integration region
, if an integration region ![]() is partitioned into, say, two disjoint subregions
is partitioned into, say, two disjoint subregions ![]() and
and ![]() ,
, ![]() ,
, ![]() , then the sum of the integral estimates of
, then the sum of the integral estimates of ![]() over
over ![]() and
and ![]() is closer to the actual integral
is closer to the actual integral ![]() . In other words,
. In other words,
and (1) will imply that the sum of the error estimates for ![]() and
and ![]() is smaller than the error estimate of
is smaller than the error estimate of ![]() .
.
Hence an adaptive strategy has these components [MalcSimp75]:
(i) an integration rule to compute the integral and error estimates over a region;
(ii) a method for deciding which elements of a set of regions ![]() to partition/subdivide;
to partition/subdivide;
(iii) stopping criteria for deciding when to terminate the adaptive strategy algorithm.
Global Adaptive Strategy
A global adaptive strategy reaches the required precision and accuracy goals of the integral estimate by recursive bisection of the subregion with the largest error estimate into two halves, and computes integral and error estimates for each half.
option name | default value | |
| Method | Automatic | integration rule used to compute integral and error estimates over each subregion |
| "SingularityDepth" | Automatic | number of recursive bisections before applying a singularity handler |
| "SingularityHandler" | Automatic | singularity handler |
| "SymbolicProcessing" | Automatic | number of seconds to do symbolic preprocessing |
"GlobalAdaptive" is the default integration strategy of NIntegrate. It is used for both one-dimensional and multidimensional integration. "GlobalAdaptive" works with both Cartesian product rules and fully symmetric multidimensional rules.
"GlobalAdaptive" uses a data structure called a "heap" to keep the set of regions partially sorted, with the largest error region being at the top of the heap. In the main loop of the algorithm the largest error region is bisected in the dimension that is estimated to be responsible for most of its error.
It can be said that the algorithm produces the leaves of a binary tree, the nodes of which are the regions. The children of a node/region are its subregions obtained after bisection.
After a bisection of a region and the subsequent integration over the new (sub)regions, new global integral and global error estimates are computed, which are sums of the integral and error estimates of all regions that are leaves of the binary tree.
Each region has a record of how many bisections are made per dimension in order to produce it. When a region has been produced through too many bisections a singularity flattening algorithm is applied to it; see "Singularity Handling".
"GlobalAdaptive" stops if the following expression is true:
where pg and ag are precision and accuracy goals.
The strategy also stops when the number of recursive bisections of a region exceeds a certain number (see "MinRecursion and MaxRecursion"), or when the global integration error oscillates too much (see "MaxErrorIncreases").
Theoretical and practical evidence show that the global adaptive strategies have, in general, better performance than the local adaptive strategies [MalcSimp75][KrUeb98].
MinRecursion and MaxRecursion
The minimal and maximal depths of the recursive bisections are given by the values of the options MinRecursion and MaxRecursion.
If for any subregion the number of bisections in any of the dimensions is greater than MaxRecursion then the integration by "GlobalAdaptive" stops.
Setting MinRecursion to a positive integer forces recursive bisection of the integration regions before the integrand is ever evaluated. This can be done to ensure that a narrow spike in the integrand is not missed. (See "Tricking the Error Estimator".)
For multidimensional integration an effort is made to bisect in each dimension for each level of recursion in MinRecursion.
"MaxErrorIncreases"
Since (2) is expected to hold in "GlobalAdaptive", the global error is expected to decrease after the bisection of the largest error region and the integration over its new parts. In other words, the global error is expected to be more or less monotonically decreasing with respect to the number of integration steps.
The global error might oscillate due to phase errors of the integration rules. Still, the global error is assumed at some point to start decreasing monotonically.
Below are listed cases in which this assumption might become false.
(i) The actual integral is zero.
(ii) The specified working precision is not dense enough for the specified precision goal.

(iii) The integration is badly conditioned [KrUeb98]. For example, the reason might be that the integrand is defined by complicated expressions or in terms of approximate solutions of mathematical problems (such as differential equations or nonlinear algebraic equations).
The strategy "GlobalAdaptive" keeps track of the number of times the total error estimate has not decreased after the bisection of the region with the largest error estimate. When that number becomes bigger than the value of the "GlobalAdaptive" option "MaxErrorIncreases", the integration stops with a message (NIntegrate::eincr).
The default value of "MaxErrorIncreases" is 400 for one-dimensional integrals and 2000 for multidimensional integrals.

Example Implementation of a Global Adaptive Strategy
Local Adaptive Strategy
In order to reach the required precision and accuracy goals of the integral estimate, a local adaptive strategy recursively partitions the subregion into smaller disjoint subregions and computes integral and error estimates for each of them.
option name | default value | |
| Method | Automatic | integration rule used to compute integral and error estimates over the subregions |
| "SingularityDepth" | Automatic | number of recursive bisections before applying a singularity handler |
| "SingularityHandler" | Automatic | singularity handler |
| "Partitioning" | Automatic | how to partition the regions in order to improve their integral estimate |
| "InitialEstimateRelaxation" | True | attempt to adjust the magnitude of the initial integral estimate in order to avoid unnecessary computation |
| "SymbolicProcessing" | Automatic | number of seconds to do symbolic preprocessing |
Like "GlobalAdaptive", "LocalAdaptive" can be used for both one-dimensional and multidimensional integration. "LocalAdaptive" works with both Cartesian product rules and fully symmetric multidimensional rules.
The "LocalAdaptive" strategy has an initialization routine and a Recursive Routine (RR). RR produces the leaves of a tree, the nodes of which are regions. The children of a node/region are subregions obtained by its partition. RR takes a region as an argument and returns an integral estimate for it.
RR uses an integration rule to compute integral and error estimates of the region argument. If the error estimate is too big, RR calls itself on the region's disjoint subregions obtained by partition. The sum of the integral estimates returned from these recursive calls becomes the region's integral estimate.
RR makes the decision to continue the recursion knowing only the integral and error estimates of the region at which it is executed. (This is why the strategy is called "local adaptive.")
The initialization routine computes an initial estimation of the integral over the initial regions. This initial integral estimate is used in the stopping criteria of RR: if the error of a region is significant compared to the initial integral estimate then that region is partitioned into disjoint regions and RR is called on them; if the error is insignificant the recursion stops.
The error estimate of a region, regionError, is considered insignificant if
The stopping criteria (3) will compute the integral to the working precision. Since you want to compute the integral estimate to user-specified precision and accuracy goals, the following stopping criteria is used:
where eps is the smallest number such that 1+eps≠1 at the working precision, and pg and ag are the user-specified precision and accuracy goals.
The recursive routine of "LocalAdaptive" stops the recursion if:
1. there are no numbers of the specified working precision between region's boundaries;
2. the maximum recursion level is reached;
3. the error of the region is insignificant, i.e. the criterion (4) is true.
MinRecursion and MaxRecursion
The options MinRecursion and MaxRecursion for "LocalAdaptive" have the same meaning and functionality as they do for "GlobalAdaptive". See "MinRecursion and MaxRecursion".
"InitialEstimateRelaxation"
After the first recursion is finished a better integral estimate, ![]() , will be available. That better estimate is compared to the two integral estimates,
, will be available. That better estimate is compared to the two integral estimates, ![]() and
and ![]() , that the integration rule has used to give the integral estimate (
, that the integration rule has used to give the integral estimate (![]() ) and the error estimate (
) and the error estimate (![]() ) for the initial step. If
) for the initial step. If
then the integral estimate integralEst in (5) can be increased—that is, the condition (6) is relaxed—with the formula
since ![]() means that the rule's integral estimate is more accurate than what the rule's error estimate predicts.
means that the rule's integral estimate is more accurate than what the rule's error estimate predicts.
"Partitioning"
"LocalAdaptive" has the option "Partitioning" to specify how to partition the regions that do not satisfy (7). For one-dimensional integrals, if "Partitioning" is set to Automatic, "LocalAdaptive" partitions a region between the sampling points of the (rescaled) integration rule. In this way, if the integration rule is of closed type, every integration value can be reused. If "Partitioning" is given a list of integers ![]() with length
with length ![]() that equals the number of integral variables, each dimension
that equals the number of integral variables, each dimension ![]() of the integration region is divided into
of the integration region is divided into ![]() equal parts. If "Partitioning" is given an integer
equal parts. If "Partitioning" is given an integer ![]() , all dimensions are divided into
, all dimensions are divided into ![]() equal parts.
equal parts.
Reuse of Integrand Values
With its default partitioning settings for one-dimensional integrals "LocalAdaptive" reuses the integrand values at the endpoints of the subintervals that have integral and error estimates that do not satisfy (8).
Example Implementation of a Local Adaptive Strategy
"GlobalAdaptive" versus "LocalAdaptive"
In general the global adaptive strategy has better performance than the local adaptive one. In some cases though, the local adaptive strategy is more robust and/or gives better performance.
There are two main differences between "GlobalAdaptive" and "LocalAdaptive":
1. "GlobalAdaptive" stops when the sum of the errors of all regions satisfies the precision goal, while "LocalAdaptive" stops when the error of each region is small enough compared to an estimate of the integral.
2. To improve the integral estimate "GlobalAdaptive" bisects the region with largest error, while "LocalAdaptive" partitions all regions for which the error is not small enough.
For multidimensional integrals "GlobalAdaptive" is much faster because "LocalAdaptive" does partitioning along each axis, so the number of regions can explode combinatorically.
Why and how global adaptive strategy is faster for one-dimensional smooth integrands is proved (and explained) in [MalcSimp75].
When "LocalAdaptive" is faster and performs better than "GlobalAdaptive", it is because the precision-goal-stopping criteria and partitioning strategy of "LocalAdaptive" are more suited for the integrand's nature. Another factor is the ability of "LocalAdaptive" to reuse the integral values of all points already sampled. "GlobalAdaptive" has the ability to reuse very few integral values (at most 3 per rule application, 0 for the default one-dimensional rule, the Gauss–Kronrod rule).
The following subsection demonstrates the performance differences between "GlobalAdaptive" and "LocalAdaptive".
"GlobalAdaptive" Is Generally Better than "LocalAdaptive"
The table that follows, with timing ratios and numbers of integrand evaluations, demonstrates that "GlobalAdaptive" is better than "LocalAdaptive" for the most common cases. All integrals considered are one dimensional over ![]() , because: (1) for multidimensional integrals the performance differences should be expected to deepen, since "LocalAdaptive" partitions the regions along each axis; and (2) one-dimensional integrals over different ranges can be rescaled to be over
, because: (1) for multidimensional integrals the performance differences should be expected to deepen, since "LocalAdaptive" partitions the regions along each axis; and (2) one-dimensional integrals over different ranges can be rescaled to be over ![]() .
.
Singularity Handling
The adaptive strategies of NIntegrate speed up their convergence through variable transformations at the integration region boundaries and user-specified singular points or manifolds. The adaptive strategies also ignore the integrand evaluation results at singular points.
Singularity specification is discussed in "User-Specified Singularities".
Multidimensional singularity handling with variable transformations should be used with caution; see "IMT Multidimensional Singularity Handling". Coordinate change for a multidimensional integral can simplify or eliminate singularities; see "Duffy's Coordinates for Multidimensional Singularity Handling".
For details about how NIntegrate ignores singularities, see "Ignoring the Singularity".
The computation of Cauchy principal value integrals is described in "Cauchy Principal Value Integration".
User-Specified Singularities
Point Singularities
If it is known where the singularities occur, they can be specified in the ranges of integration, or through the option Exclusions.
Curve, Surface, and Hypersurface Singularities
Singularities over curves, surfaces, or hypersurfaces in general can be specified through the option Exclusions with their equations. Such singularities generally cannot be specified using variable ranges.

Example Implementation of Curve, Surface, and Hypersurface Singularity Handling
If the curve, surface, or hypersurface on which the singularities occur is known in implicit form (i.e. it can be described as a single equation) the function Boole can be used to form integration regions that have the singular curves, surfaces, or hypersurfaces as boundaries.
"SingularityHandler" and "SingularityDepth"
Adaptive strategies improve the integral estimate by region bisection. If an adaptive strategy subregion is obtained by the number of bisections specified by the option "SingularityDepth", it is decided that subregion has a singularity. Then the integration over that subregion is done with the singularity handler specified by "SingularityHandler".
option name | default value | |
| "SingularityDepth" | Automatic | number of recursive bisections before applying a singularity handler |
| "SingularityHandler" | Automatic | singularity handler |
"GlobalAdaptive" and "LocalAdaptive" singularity handling options.
If there is an integrable singularity at the boundary of a given region of integration, bisection could easily recur to MaxRecursion before convergence occurs. To deal with these situations the adaptive strategies of NIntegrate use variable transformations (IMT, "DoubleExponential", SidiSin) to speed up the integration convergence, or a region transformation (Duffy's coordinates) that relaxes the order of the singularity. The theoretical background of the variable transformation singularity handlers is given by the Euler–Maclaurin formula [DavRab84].
Use of the IMT Variable Transformation
The IMT variable transformation is the variable transformation in a quadrature method proposed by Iri, Moriguti, and Takasawa, called in the literature the IMT rule [DavRab84][IriMorTak70]. The IMT rule is based upon the idea of transforming the independent variable in such a way that all derivatives of the new integrand vanish at the endpoints of the integration interval. A trapezoidal rule is then applied to the new integrand, and under proper conditions high accuracy of the result might be attained [IriMorTak70][Mori74].
option name | default value | |
| "TuningParameters" | 10 | a pair of numbers {a,p} that are the tuning parameters in the IMT transformation formula |
IMT singularity handler options.
Adaptive strategies of NIntegrate employ only the transformation of the IMT rule. With the decision that a region might have a singularity, the IMT transformation is applied to its integrand. The integration continues, though not with a trapezoidal rule, but with the same integration rule used before the transformation. (Singularity handling with "DoubleExponential" switches to a trapezoidal integration rule.)
Also, adaptive strategies of NIntegrate use a variant of the original IMT transformation, with the transformed integrand vanishing only at one of the ends.
The parameters a and p are called tuning parameters [MurIri82].
From the graph above, it follows that the transformed sampling points are much denser around 0. This means that if the integrand is singular at 0 it will be sampled more effectively, since a larger part of the integration rule sampling points will contribute large integrand values to the integration rule's integral estimate.
No other singularity handler is applied to the subregions of a region to which the IMT variable transformation has been applied.
IMT Transformation by Example
Some of the sampling points, though, become too close to the singular end, and therefore special care should be taken for sampling points that coincide with the singular point because of the IMT transformation. NIntegrate ignores evaluations at singular points; see "Ignoring the Singularity".
Use of Double Exponential Quadrature
When adaptive strategies use the IMT variable transformation they do not change the integration rule on the IMT-transformed regions. In contrast to this you can use both a variable transformation and a different integration rule on the regions considered to have singularity. (This is more in the spirit of the IMT rule [DavRab84].) This is exactly what happens when double exponential quadrature is used—double exponential quadrature uses the trapezoidal rule.
NIntegrate can use double exponential quadrature for singularity handling only for one-dimensional integration.
IMT versus "DoubleExponential" versus No Singularity Handling for One-Dimensional Integrals
Both singularity handlers (IMT and "DoubleExponential") are applied to regions that are obtained through too many bisections (as specified by "SingularityDepth").
The main difference between them is that IMT does not change the integration rule used to compute integral estimates on the region it is applied to—IMT is only a variable transformation. On the other hand, "DoubleExponential" uses both variable transformation and a different integration rule—the trapezoidal rule—to compute integral estimates on the region it is applied to. In other words, the singularity handler "DoubleExponential" delegates the integration to the double exponential quadrature as described in "Double Exponential Strategy".
As a consequence, a region to which the IMT singularity handler is applied is still going to be subject to bisection by the adaptive integration strategy. Therefore, until the precision goal is reached the integrand evaluations done before the last bisection will be thrown away. On the other hand, a region to which the "DoubleExponential" singularity handler is applied will not be bisected. The trapezoidal rule quadrature used by "DoubleExponential" will compute integral estimates over the region with an increasing number of sampling points at each step, completely reusing the integrand evaluations of the sampling points from the previous steps.
So, if the integrand is "very" analytic (i.e. no rapid or sudden changes of the integrand and its derivatives with respect to the integration variable) over the regions with endpoint singularity, the "DoubleExponential" singularity handler is going to be much faster than the IMT singularity handler. In the cases where the integrand is not analytic in the region given to the "DoubleExponential" singularity handler, or the double transformation of the integrand converges too slowly, it is better to switch to the IMT singularity handler. This is done if the option "SingularityHandler" is set to Automatic.
Following are tables that compare the IMT, "DoubleExponential", and Automatic singularity handlers applied at different depths of bisection.
IMT Multidimensional Singularity Handling
When used for multidimensional integrals, the IMT singularity handler speeds up the integration process only when the singularity is along one of the axes. When the singularity is at a corner of the integration region, using IMT is counterproductive. The function NIntegrateProfile defined earlier is used in the following examples.
Duffy's Coordinates for Multidimensional Singularity Handling
Duffy's coordinates is a technique that transforms an integrand over a square, cube, or hypercube with a singular point in one of the corners into an integrand with a singularity over a line, which might be easier to integrate.
The NIntegrate strategies "GlobalAdaptive" and "LocalAdaptive" apply the Duffy's coordinates technique only at the corners of the integration region.
When the singularity of a multidimensional integral occurs at a point, the coupling of the variables will make the singularity variable transformations used in one-dimensional integration counterproductive. A variable transformation that has a geometrical nature, proposed by Duffy in [Duffy82], makes a change of variables that replaces a point singularity at a corner of the integration region with a "softer" one on a plane.
If ![]() is the dimension of integration and
is the dimension of integration and ![]() , then Duffy's coordinates is a suitable technique for singularities of the following type (see again [Duffy82]):
, then Duffy's coordinates is a suitable technique for singularities of the following type (see again [Duffy82]):
For example, consider the integral
If the integration region ![]() is changed to
is changed to ![]() with the rule
with the rule ![]() , the Jacobian of which is
, the Jacobian of which is ![]() , the integral becomes
, the integral becomes
The last integral has no singularities at all!
which is equivalent to the sum
The first integral of that sum is transformed as in (9); for the second one, though, the change of ![]() into
into ![]() by
by ![]() has the Jacobian
has the Jacobian ![]() , which will not bring the desired cancellation of terms. Fortunately, a change of the order of integration:
, which will not bring the desired cancellation of terms. Fortunately, a change of the order of integration:
makes the second integral amenable for the transformation in (10):
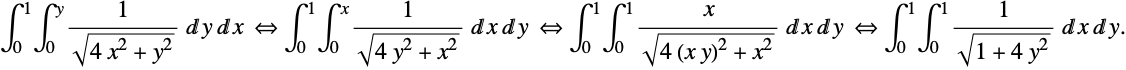
(In the second integral in equation (3) the variables were permuted, which is not necessary to prove the mathematical equivalence, but it is faster when computing the integrals.)
So the integral (11) can be rewritten as an integral with no singularities:
If the integration variables were not permuted in (12), the integral (13) is going to be rewritten as
That is a more complicated integral, as its integrand is not simple along both axes. Subsequently it is harder to compute than the former one.
NIntegrate uses a generalization to arbitrary dimension of the technique in the example above. (In [Duffy82] only the third dimension is described.) An example implementation together with the generalization description are given below.
Duffy's Coordinates Strategy
When Duffy's coordinates are applicable, a numerical integration result is obtained faster if Duffy's coordinate change is made before the actual integration begins. Making the transformation beforehand, though, requires knowing at which corner(s) of the integration region the singularities occur. The "DuffyCoordinates" strategy in NIntegrate facilitates such pre-integration transformation.
option name | default value | |
| Method | {"GlobalAdaptive","SingularityDepth"->∞} | the strategy with which the integration will be made after applying Duffy's coordinates transformation |
| "Corners" | All | a vector or a list of vectors that specifies the corner(s) to apply the Duffy's coordinates tranformation to; the elements of the vectors are either 0 or 1; each vector length equals the dimension of the integral |
The first thing "DuffyCoordinates" does is to rescale the integral into one that is over the unit hypercube (or square, or cube). If only one corner is specified, "DuffyCoordinates" applies Duffy's coordinates transformation as described earlier. If more than one corner is specified, the unit hypercube of the previous step is partitioned into disjoint cubes with side length of one-half. Consider the integrals over these disjoint cubes. Duffy's coordinates transformation is applied to the ones that have a vertex that is specified to be singular. The rest are transformed into integrals over the unit cube. Since all integrals at this point have an integration region that is the unit cube, they are summated, and that sum is given to NIntegrate with a Method option that is the same as the one given to "DuffyCoordinates".
The actual integrand used by "DuffyCoordinates" can be obtained through NIntegrate`DuffyCoordinatesIntegrand, which has the same arguments as NIntegrate.
"DuffyCoordinates" might considerably improve speed for the types of integrands described in "Duffy's Coordinates for Multidimensional Singularity Handling".
Duffy's Coordinates Generalization and Example Implementation
See "Duffy's Coordinates for Multidimensional Singularity Handling" for the theory of Duffy's coordinates.
The implementation is based on the following two theorems.
Theorem 1: A ![]() -dimensional cube can be divided into
-dimensional cube can be divided into ![]() disjoint geometrically equivalent
disjoint geometrically equivalent ![]() -dimensional pyramids (with bases
-dimensional pyramids (with bases ![]() -dimensional cubes) and with coinciding apexes.
-dimensional cubes) and with coinciding apexes.
Proof: Assume the side length of the cube is 1, the cube has a vertex at the origin, and the coordinates of all other vertexes are ![]() or
or ![]() . Consider the
. Consider the ![]() -dimensional cube walls
-dimensional cube walls ![]() , where
, where ![]() . Their number is exactly
. Their number is exactly ![]() , and the origin does not belong to them. Each of the
, and the origin does not belong to them. Each of the ![]() walls can form a pyramid with the origin. This proves the theorem.
walls can form a pyramid with the origin. This proves the theorem.
If the ![]() axes are denoted
axes are denoted ![]() the pyramid formed with the wall
the pyramid formed with the wall ![]() can be described as
can be described as ![]() . Let
. Let ![]() denote the permutation derived after rotating
denote the permutation derived after rotating ![]() cyclically
cyclically ![]() times to the left (i.e. applying
times to the left (i.e. applying ![]() times RotateLeft to
times RotateLeft to ![]() ). Then the following theorem holds:
). Then the following theorem holds:
Theorem 2: For any integral over the unit cube the following equalities hold:
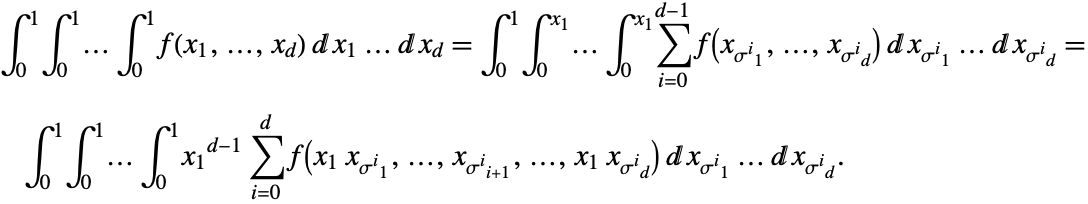
Proof: The first equality follows from Theorem 1. The second equality is just a change of variables that transforms a pyramid to a cube.
Ignoring the Singularity
Another way of handling a singularity is to ignore it. NIntegrate ignores sampling points that coincide with a singular point.
Consider the following integral that has a singular point at 1.
The integrand goes to ![]() when the integration variable is close to 1.
when the integration variable is close to 1.
With its default options NIntegrate has a sampling point at 1, as can be seen from the following.
But for NIntegrate[Log[(1-x)2],{x,0,2}] the evaluation monitor has not picked a sampling point that is 1.
In other words, the singularity at 1 is ignored. Ignoring the singularity is equivalent to having an integrand that is zero at the singular sampling point.
Note that the integral is easily integrated if the singular point is specified in the variable range. Following are the numbers of sampling points and timings for NIntegrate with the singular and nonsingular range specifications.
A more interesting example of ignoring the singularity is using Bessel functions in the denominator of the integrand.
The result can be checked using NIntegrate with singular range specification with the zeros of BesselJ[2,x] (see BesselJZero).
Needless to say, the last integration required the calculation of the BesselJ zeros. The former one "just integrates" without any integrand analysis.
Ignoring the singularity may not work with oscillating integrands.
However, if the integrand is monotonic in a neighborhood of its singularity, or more precisely, if it can be majorized by a monotonic integrable function, it can be shown that by ignoring the singularity, convergence will be reached.
For theoretical justification and practical recommendations of ignoring the singularity see [DavRab65IS] and [DavRab84].
Automatic Singularity Handling
One-Dimensional Integration
When the option "SingularityHandler" is set to Automatic for a one-dimensional integral, "DoubleExponential" is used on regions that are obtained by "SingularityDepth" number of partitionings. As explained earlier, this region will not be partitioned further as long as the "DoubleExponential" singularity handler works over it. If the error estimate computed by "DoubleExponential" does not evolve in a way predicted by the theory of the double exponential quadrature, the singularity handling for this region is switched to IMT.
As explained in "Convergence Rate", the following dependency of the error is expected with respect to the number of double exponential sampling points:
where ![]() is a positive constant. Consider the relative errors
is a positive constant. Consider the relative errors ![]() and
and ![]() of two consecutive double exponential quadrature calculations, made with
of two consecutive double exponential quadrature calculations, made with ![]() and
and ![]() number of sampling points respectively, for which
number of sampling points respectively, for which ![]() . Assuming
. Assuming ![]() ,
, ![]() , and
, and ![]() it should be expected that
it should be expected that
The switch from "DoubleExponential" to IMT happens when:
(i) the region error estimate is larger than the absolute value of the region integral estimate (hence the relative error is not smaller than 1);
(ii) the inequality (2) is not true in two different instances;
(iii) the integrand values calculated with the double exponential transformation do not decay fast enough.
Multidimensional Integration
When the option "SingularityHandler" is set to Automatic for a multidimensional integral, both "DuffyCoordinates" and IMT are used.
A region needs to meet the following conditions in order for "DuffyCoordinates" to be applied:
the region is obtained by "SingularityDepth" number of bisections (or partitionings) along each axis;
the region is a corner of one of the initial integration regions (the specified integration region can be partitioned into integration regions by piecewise handling or by user-specified singularities).
A region needs to meet the following conditions in order for IMT to be applied:
the region is obtained with "SingularityDepth" number of bisections (or partitionings) along predominantly one axis;
the region is not a corner region and it is on a side of one of the initial integration regions.
In other words, IMT is applied to regions that are derived through "SingularityDepth" number of partitionings but that do not satisfy the conditions of the "DuffyCoordinates" automatic application.
IMT is effective if the singularity is along one of the axes. Using IMT for point singularities can be counterproductive.
Cauchy Principal Value Integration
To evaluate the Cauchy principal value of an integral, NIntegrate uses the strategy PrincipalValue.
In NIntegrate, PrincipalValue uses the strategy specified by its Method option to work directly on those regions where there is no difficulty and by pairing values symmetrically about the specified singularities in order to take advantage of the cancellation of the positive and negative values.
option name | default value | |
| Method | Automatic | method specification used to compute estimates over subregions |
| SingularPointIntegrationRadius | Automatic | a number ϵ1 or a list of numbers {ϵ1,ϵ2,…,ϵn} that correspond to the singular points |
where each of the integrals is evaluated using NIntegrate with Method->methodspec. If ϵ is not given explicitly, a value is chosen based upon the differences b-a and c-b. The option SingularPointIntegrationRadius can take a list of numbers that equals the number of singular points. For the derivation of the formula see [DavRab84].
It should be noted that the singularities must be located exactly. Since the algorithm pairs together the points on both sides of the singularity, if the singularity is slightly mislocated the cancellation will not be sufficiently good near the pole and the result can be significantly in error if NIntegrate converges at all.
Sampling Points Visualization
Consider the calculation of the principal value of
The following examples show two ways of visualizing the sampling points. The first shows the sampling points used. Since the integrand is modified in order to do the principal value integration, it might be desired to see the points at which the original integrand is evaluated. This is shown on the second example.
Double Exponential Strategy
The double exponential quadrature consists of applying the trapezoidal rule after a variable transformation. The double exponential quadrature was proposed by Mori and Takahasi in 1974 and it was inspired by the so-called IMT rule and TANH rule. The transformation is given the name "double exponential" since its derivative decreases double exponentially when the integrand's variable reaches the ends of the integration region.
option name | default value | |
| "ExtraPrecision" | 50 | maximum extra precision to be used internally |
| "SymbolicProcessing" | Automatic | number of seconds to do symbolic preprocessing |
The double exponential strategy can be used for one-dimensional and multidimensional integration. When applied to multidimensional integrals it uses the Cartesian product of the trapezoidal rule.
A double exponential transformation ![]() transforms the integral
transforms the integral
where ![]() can be finite, half-infinite (
can be finite, half-infinite (![]() ), or infinite (
), or infinite (![]() ). The integrand
). The integrand ![]() must be analytic in
must be analytic in ![]() and might have singularity at one or both of the endpoints.
and might have singularity at one or both of the endpoints.
The transformed integrand decreases double exponentially, that is, ![]()
![]() as
as ![]() .
.
The function ![]() is analytic in
is analytic in ![]() . It is known that for an integral like (14) of an analytic integrand the trapezoidal rule is an optimal rule [Mori74].
. It is known that for an integral like (14) of an analytic integrand the trapezoidal rule is an optimal rule [Mori74].
The transformations used for the different types of integration regions are:
The trapezoidal rule is applied to (15):
The terms in (16) decay double exponentially for large enough ![]() . Therefore the summation in (17) is cut off at the terms that are too small to contribute to the total sum. (A criterion similar to (18) for the local adaptive strategy is used. See also the following double exponential example implementation.)
. Therefore the summation in (17) is cut off at the terms that are too small to contribute to the total sum. (A criterion similar to (18) for the local adaptive strategy is used. See also the following double exponential example implementation.)
The strategy "DoubleExponential" employs the double exponential quadrature.
The "DoubleExponential" strategy works best for analytic integrands; see "Comparison of Double Exponential and Gaussian Quadrature".
"DoubleExponential" uses the Cartesian product of double exponential quadratures for multidimensional integrals.
As with the other Cartesian product rules, if "DoubleExponential" is used for dimensions higher than three, it might be very slow due to combinatorial explosion.
Double exponential quadrature can be used for singularity handling in adaptive strategies; see "Singularity Handling".
MinRecursion and MaxRecursion
The option MinRecursion has the same meaning and functionality as it does for "GlobalAdaptive" and "LocalAdaptive" described in "MinRecursion and MaxRecursion". MaxRecursion for "DoubleExponential" restricts how many times the trapezoidal quadrature estimates are improved; see "Example Implementation of Double Exponential Quadrature".
Comparison of Double Exponential and Gaussian Quadrature
The "DoubleExponential" strategy works best for analytic integrands. For example, the following integral is done by "DoubleExponential" three times faster than the Gaussian quadrature (using a global adaptive algorithm).
Since "DoubleExponential" converges double exponentially with respect to the number of evaluation points, increasing the precision goal slightly increases the work done by "DoubleExponential". This is illustrated for two integrals, ![]() and
and ![]() . Each table entry shows the error and number of evaluations.
. Each table entry shows the error and number of evaluations.
On the other hand, for nonanalytic integrands "DoubleExponential" is quite slow, and a global adaptive algorithm using Gaussian quadrature can resolve the singularities easily.
Further, "DoubleExponential" might be slowed down by integrands that have nearly discontinuous derivatives, that is, integrands that are not "very" analytical.
Convergence Rate
This section demonstrates that the asymptotic error of the double exponential quadrature in terms of the number ![]() of evaluation points used is
of evaluation points used is
Example Implementation of Double Exponential Quadrature
Following is an example implementation of the double exponential quadrature with the finite-region variable transformation (transformation (21) earlier).
"Trapezoidal" Strategy
The "Trapezoidal" strategy gives optimal convergence for analytic periodic integrands when the integration interval is exactly one period.
option name | default value | |
| "ExtraPrecision" | 50 | maximum extra precision to be used internally |
| "SymbolicProcessing" | Automatic | number of seconds to do symbolic preprocessing |
"Trapezoidal" takes the same options as "DoubleExponential". If the integration ranges are infinite or semi-infinite, "Trapezoidal" becomes "DoubleExponential".
For theoretical background, examples, and explanations of periodic functions integration (with trapezoidal quadrature) see [Weideman2002].
Example Implementation
Oscillatory Strategies
NIntegrate includes several methods for oscillatory integration. The integration rule "LevinRule" applies to a large class of one-dimensional and multidimensional oscillatory integrals. It is used with adaptive rule-based strategies such as "GlobalAdaptive".
NIntegrate also includes several integration strategies specialized to certain types of one-dimensional oscillatory integrals. Generally these algorithms are for either finite-region integrals or infinite-region integrals only. For oscillatory integrals on a finite region, NIntegrate uses Chebyshev expansions of the integrand and the global adaptive integration strategy. For oscillatory integrals on an infinite region, NIntegrate uses either a modification of the double exponential algorithm or sequence summation acceleration over the sequence of integrals over regions between the zeros of the integrand.
NIntegrate automatically detects oscillatory (one-dimensional) integrands, and selects which strategy or rule to use according to the integrand's region and specific oscillatory form.
The integrals handled by the specialized strategies described here are of the form
where the oscillating kernel ![]() is of the form:
is of the form:
2. ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() , or
, or ![]() for
for ![]() infinite or semi-infinite.
infinite or semi-infinite.
In these oscillating kernel forms, ![]() ,
, ![]() , and
, and ![]() are real constants, and
are real constants, and ![]() is a positive integer.
is a positive integer.
See "LevinRule" for a description of the more general forms of oscillatory integrand handled by that integration rule.
Finite Region Oscillatory Integration
Modified Clenshaw–Curtis quadrature ([PiesBrand75][PiesBrand84]) is for finite-region one-dimensional integrals of the form
where ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() are finite real numbers.
are finite real numbers.
The modified Clenshaw–Curtis quadrature rule approximates ![]() with a single polynomial through Chebyshev polynomials expansion. This leads to simplified computations because of the orthogonality of the Chebyshev polynomials with sine and cosine functions. The modified Clenshaw–Curtis quadrature rule is used with the strategy "GlobalAdaptive". For smooth
with a single polynomial through Chebyshev polynomials expansion. This leads to simplified computations because of the orthogonality of the Chebyshev polynomials with sine and cosine functions. The modified Clenshaw–Curtis quadrature rule is used with the strategy "GlobalAdaptive". For smooth ![]() the modified Clenshaw–Curtis quadrature is usually superior [KrUeb98] to other approaches for oscillatory integration (as Filon's quadrature and multi-panel integration between the zeros of the integrand).
the modified Clenshaw–Curtis quadrature is usually superior [KrUeb98] to other approaches for oscillatory integration (as Filon's quadrature and multi-panel integration between the zeros of the integrand).
Modified Clenshaw–Curtis quadrature is quite good for highly oscillating integrals of the form (23). For example, modified Clenshaw–Curtis quadrature uses less than a hundred integrand evaluations for both ![]() and
and ![]() .
.
On the other hand, without symbolic preprocessing, the default NIntegrate method—"GlobalAdaptive" strategy with a Gauss–Kronrod rule—uses thousands of evaluations for ![]() , and it cannot integrate
, and it cannot integrate ![]() .
.
Extrapolating Oscillatory Strategy
The NIntegrate strategy "ExtrapolatingOscillatory" is for oscillating integrals in infinite one-dimensional regions. The strategy uses sequence convergence acceleration for the sum of the sequence that consists of each of the integrals with regions between two consecutive zeros of the integrand.
option name | default value | |
| Method | GlobalAdaptive | integration strategy used to integrate between the zeros and which will be used if ExtrapolatingOscillatory fails |
| "SymbolicProcessing" | Automatic | number of seconds to do symbolic processing |
where the function ![]() is the oscillating kernel and the function
is the oscillating kernel and the function ![]() is smooth. Let
is smooth. Let ![]() be the zeros of
be the zeros of ![]() enumerated from the lower (finite) integration bound, that is, the inequality
enumerated from the lower (finite) integration bound, that is, the inequality ![]() holds. If the integral (24) converges then the sequence
holds. If the integral (24) converges then the sequence
converges too. The elements of the sequence (25) are the partial sums of the sequence
Often a good estimate of the limit of the sequence (26) can be computed with relatively few elements of it through some convergence acceleration technique.
The "ExtrapolatingOscillatory" strategy uses NSum with Wynn's extrapolation method for the integrals in (27). Each integral in (28) is calculated by NIntegrate without oscillatory methods.
The "ExtrapolatingOscillatory" strategy applies its algorithm to oscillating kernels ![]() in (29) that are of the form
in (29) that are of the form ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() , or
, or ![]() , where
, where ![]() ,
, ![]() ,
, ![]() , and
, and ![]() are real constants.
are real constants.
Example Implementation
The following example implementation illustrates how the "ExtrapolatingOscillatory" strategy works.
Double Exponential Oscillatory Integration
The strategy "DoubleExponentialOscillatory" is for slowly decaying oscillatory integrals over one-dimensional infinite regions that have integrands of the form ![]() ,
, ![]() , or
, or ![]() , where
, where ![]() is the integration variable and
is the integration variable and ![]() ,
, ![]() ,
, ![]() are constants.
are constants.
option name | default value | |
| Method | None | integration strategy used if "DoubleExponentialOscillatory" fails |
| "TuningParameters" | Automatic | tuning parameters of the error estimation |
| "SymbolicProcessing" | Automatic | number of seconds to do symbolic processing |
"DoubleExponentialOscillatory" options.
"DoubleExponentialOscillatory" is based on the strategy "DoubleExponential", but instead of using a transformation that reaches double exponentially the ends of the integration interval, "DoubleExponentialOscillatory" uses a transformation that reaches double exponentially the zeros of ![]() and
and ![]() . The theoretical foundations and properties of the algorithm are explained in [OouraMori91], [OouraMori99], [MoriOoura93]. The implementation of "DoubleExponentialOscillatory" uses the formulas and the integrator design in [OouraMori99].
. The theoretical foundations and properties of the algorithm are explained in [OouraMori91], [OouraMori99], [MoriOoura93]. The implementation of "DoubleExponentialOscillatory" uses the formulas and the integrator design in [OouraMori99].
The algorithm of "DoubleExponentialOscillatory" will be explained using the sine integral
Consider the following transformation
where ![]() and
and ![]() are constants satisfying
are constants satisfying
The parameters ![]() and
and ![]() are chosen to satisfy
are chosen to satisfy
(taken from [OouraMori99]).
Transformation (30) is applied to (31) to obtain
Note that ![]() disappeared in the sine term. The trapezoidal formula with equal mesh size
disappeared in the sine term. The trapezoidal formula with equal mesh size ![]() applied to (32) gives
applied to (32) gives
which is approximated with the truncated series sum
The integrand decays double exponentially at large negative ![]() , as can be seen from (33). While the double exponential transformation, (34) in "Double Exponential Strategy", also makes the integrand decay double exponentially at large positive
, as can be seen from (33). While the double exponential transformation, (34) in "Double Exponential Strategy", also makes the integrand decay double exponentially at large positive ![]() , the transformation (35) does not decay the integrand at large positive
, the transformation (35) does not decay the integrand at large positive ![]() . Instead it makes the sampling points approach double exponentially to the zeros of
. Instead it makes the sampling points approach double exponentially to the zeros of ![]() at large positive
at large positive ![]() . Moreover
. Moreover
As is explained in [OouraMori99], since ![]() is linear near any of its zeros, the integrand decreases double exponentially as
is linear near any of its zeros, the integrand decreases double exponentially as ![]() approaches a zero of
approaches a zero of ![]() . This is the sense in which (36) is considered a double exponential formula.
. This is the sense in which (36) is considered a double exponential formula.
The relative error is assumed to satisfy
In [OouraMori99] the suggested value for ![]() is 5.
is 5.
Since the ![]() formulas cannot be made progressive, "DoubleExponentialOscillatory" (as proposed in [OouraMori99]) does between two and four integration estimates with different
formulas cannot be made progressive, "DoubleExponentialOscillatory" (as proposed in [OouraMori99]) does between two and four integration estimates with different ![]() . If the desired relative error is
. If the desired relative error is ![]() the integration steps are the following:
the integration steps are the following:
and compute (37) with ![]() . Let the result be
. Let the result be ![]() .
.
2. Next, set ![]() , and compute (38) with
, and compute (38) with ![]() . Let the result be
. Let the result be ![]() . The relative error of the first integration step
. The relative error of the first integration step ![]() is assumed to be
is assumed to be ![]() . From (39)
. From (39) ![]() , and therefore, if
, and therefore, if
is satisfied, where ![]() is a robustness factor (by default 10) "DoubleExponentialOscillatory" exits with result
is a robustness factor (by default 10) "DoubleExponentialOscillatory" exits with result ![]() .
.
3. If (40) does not hold, compute
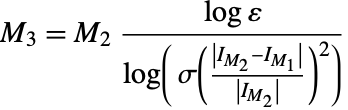
"DoubleExponentialOscillatory" exits with result ![]() .
.
4. If (42) does not hold, compute
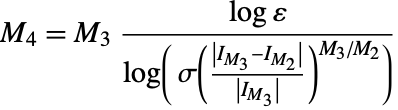
and compute (43) with ![]() . Let the result be
. Let the result be ![]() . If
. If
does not hold, "DoubleExponentialOscillatory" issues the message NIntegrate::deoncon. If the value of the "DoubleExponentialOscillatory" method option is None, then ![]() is returned. Otherwise "DoubleExponentialOscillatory" will return the result of NIntegrate called with the "DoubleExponentialOscillatory" method option.
is returned. Otherwise "DoubleExponentialOscillatory" will return the result of NIntegrate called with the "DoubleExponentialOscillatory" method option.
the transformation corresponding to (44) is
Generalized Integrals
More about the properties of "DoubleExponentialOscillatory" for divergent Fourier-type integrals can found in [MoriOoura93].
Nonalgebraic Multiplicand
Crude Monte Carlo and Quasi Monte Carlo Strategies
The crude Monte Carlo algorithm estimates a given integral by averaging integrand values over uniformly distributed random points in the integral's region. The number of points is incremented until the estimated standard deviation is small enough to satisfy the specified precision or accuracy goals. A Monte Carlo algorithm is called a quasi Monte Carlo algorithm if it uses equidistributed, deterministically generated sequences of points instead of uniformly distributed random points.
option name | default value | |
| Method | "MonteCarloRule" | Monte Carlo rule specification |
| MaxPoints | 50000 | maximum number of sampling points |
| "RandomSeed" | Automatic | a seed to reset the random generator |
| "Partitioning" | 1 | partitioning of the integration region along each axis |
| "SymbolicProcessing" | 0 | number of seconds to do symbolic preprocessing |
option name | default value | |
| MaxPoints | 50000 | maximum number of sampling points |
| "Partitioning" | 1 | partitioning of the integration region along each axis |
| "SymbolicProcessing" | 0 | number of seconds to do symbolic preprocessing |
In Monte Carlo methods [KrUeb98] the ![]() -dimensional integral
-dimensional integral ![]() is interpreted as the following expected (mean) value:
is interpreted as the following expected (mean) value:
where ![]() is the mean value (the expectation) of the function
is the mean value (the expectation) of the function ![]() interpreted as a random variable, with respect to the uniform distribution on
interpreted as a random variable, with respect to the uniform distribution on ![]() , that is, the distribution with probability density vol(V)-1Boole(x∈V). Boole(x∈V) denotes the characteristic function of the region
, that is, the distribution with probability density vol(V)-1Boole(x∈V). Boole(x∈V) denotes the characteristic function of the region ![]() , while
, while ![]() denotes the volume of
denotes the volume of ![]() .
.
The crude Monte Carlo estimate is made with the integration rule "MonteCarloRule". The formulas for the integral and error estimation are given in "MonteCarloRule" in "NIntegrate Integration Rules".
If the original integration region ![]() is partitioned into the set of disjoint subregions
is partitioned into the set of disjoint subregions ![]() ,
, ![]() , then the integral estimate is
, then the integral estimate is
The number of sampling points used on each subregion generally can be different, but in the Monte Carlo algorithms all ![]() are equal (
are equal (![]() ).
).
The partitioning ![]() is called stratification, and each
is called stratification, and each ![]() is called strata. Stratification can be used to improve crude Monte Carlo estimations. (The adaptive Monte Carlo algorithm uses recursive stratification.)
is called strata. Stratification can be used to improve crude Monte Carlo estimations. (The adaptive Monte Carlo algorithm uses recursive stratification.)
AccuracyGoal and PrecisionGoal
The default values for AccuracyGoal and PrecisionGoal are Infinity and 2, respectively, when the Monte Carlo algorithms of NIntegrate are used.
MaxPoints
The option MaxPoints specifies the maximum number of (pseudo) random sampling points to be used to compute the Monte Carlo estimate of an integral.
"RandomSeed"
The value of the option "RandomSeed" is used to seed the random generator used to make the sampling integration points. In that respect the use of "RandomSeed" in the Monte Carlo method is similar to the use of SeedRandom and RandomReal.
By using "RandomSeed" the results of a Monte Carlo integration can be reproduced. The results of the following two runs are identical.
Stratified Crude Monte Carlo Integration
In stratified sampling Monte Carlo integration you break the region into several subregions and apply the crude Monte Carlo estimate on each subregion separately.
From the expected (mean) value formula, equation (45) at the beginning of "Crude Monte Carlo and Quasi Monte Carlo Strategies", you have
Let the region ![]() be bisected into two half-regions,
be bisected into two half-regions, ![]() and
and ![]() .
. ![]() is the expectation of
is the expectation of ![]() on
on ![]() , and
, and ![]() is the variance of
is the variance of ![]() on
on ![]() . From the theorem [PrFlTeuk92]
. From the theorem [PrFlTeuk92]
you can see that the stratified sampling gives a variance that is never larger than the crude Monte Carlo sampling variance.
There are two ways to specify strata for the "MonteCarlo" strategy. One is to specify "singular" points in the variable range specifications, the other is to use the method suboption "Partitioning".
If "Partitioning" is given a list of integers, ![]() with length
with length ![]() that equals the number of integral variables, each dimension
that equals the number of integral variables, each dimension ![]() of the integration region is divided into
of the integration region is divided into ![]() equal parts. If "Partitioning" is given an integer
equal parts. If "Partitioning" is given an integer ![]() , all dimensions are divided into
, all dimensions are divided into ![]() equal parts.
equal parts.
Stratified Monte Carlo sampling can be specified if the integration variable ranges are given with intermediate singular points.
Stratified sampling improves the efficiency of the crude Monte Carlo estimation: if the number of strata is ![]() , the standard deviation of the stratified Monte Carlo estimation is
, the standard deviation of the stratified Monte Carlo estimation is ![]() times less of the standard deviation of the crude Monte Carlo estimation. (See the following example.)
times less of the standard deviation of the crude Monte Carlo estimation. (See the following example.)
Convergence Speedup of the Stratified Monte Carlo Integration
The following example confirms that if the number of strata is ![]() , the standard deviation of the stratified Monte Carlo estimation is
, the standard deviation of the stratified Monte Carlo estimation is ![]() times less than the standard deviation of the crude Monte Carlo estimation.
times less than the standard deviation of the crude Monte Carlo estimation.
Global Adaptive Monte Carlo and Quasi Monte Carlo Strategies
The global adaptive Monte Carlo and quasi Monte Carlo strategies recursively bisect the subregion with the largest variance estimate into two halves, and compute integral and variance estimates for each half.
option name | default value | |
| Method | MonteCarloRule | MonteCarloRule specification |
| "Partitioning" | Automatic | initial partitioning of the integration region along each axis |
| "BisectionDithering" | 0 | offset from the middle of the region side that is parallel to the bisection axis |
| "MaxPoints" | Automatic | maximum number of (pseudo) random sampling points to be used |
| "RandomSeed" | Automatic | random seed used to generate the (pseudo) random sampling points |
Adaptive (quasi) Monte Carlo uses crude (quasi) Monte Carlo estimation rule on each subregion.
The process of subregion bisection and subsequent bi-integration is expected to reduce the global variance, and it is referred to as recursive stratified sampling. It is motivated by a theorem that states that if a region is partitioned into disjoint subregions the random variable variance over the region is greater than or equal to the sum of the random variable variances over each subregion. (See "Stratified Monte Carlo Integration" in "Crude Monte Carlo and Quasi Monte Carlo Strategies".)
The global adaptive Monte Carlo strategy "AdaptiveMonteCarlo" is similar to "GlobalAdaptive". There are some important differences though.
1. "AdaptiveMonteCarlo" does not use singularity flattening, and does not have detectors for slow convergence and noisy integration.
2. "AdaptiveMonteCarlo" chooses randomly the bisection dimension. To avoid irregular separation of different coordinates a dimension recurs only if other dimensions have been chosen for bisection.
3. "AdaptiveMonteCarlo" can be tuned to bisect the subregions away from the middle. More at "BisectionDithering".
MinRecursion and MaxRecursion
The options MinRecursion and MaxRecursion for the adaptive Monte Carlo methods have the same meaning and functionality as they do for "GlobalAdaptive". See "MinRecursion and MaxRecursion".
"Partitioning"
The option "Partitioning" of "AdaptiveMonteCarlo" provides initial stratification of the integration. It has the same meaning and functionality as "Partitioning" of the strategy "MonteCarlo".
"BisectionDithering"
When the integrand has some special symmetry that puts significant parts of it in the middle of the region, it is better if the bisection is done slightly away from the middle. The value of the option "BisectionDithering"->dith specifies that the splitting fraction of the region's splitting dimension side should be at ![]() instead of
instead of ![]() . The sign of dith is changed in a random manner. The default value given to "BisectionDithering" is
. The sign of dith is changed in a random manner. The default value given to "BisectionDithering" is ![]() . The allowed values for dith are reals in the interval
. The allowed values for dith are reals in the interval ![]() .
.
Choice of Bisection Axis
For multidimensional integrals the adaptive Monte Carlo algorithm chooses the splitting axis of an integration region in two ways: (1) by random selection; or (2) by minimizing the variance of the integral estimates of each half. The axis selection is a responsibility of the "MonteCarloRule".
Example: Comparison with Crude Monte Carlo
Generally, the "AdaptiveMonteCarlo" strategy has greater performance than "MonteCarlo". This is demonstrated with the examples in this subsection.
It can be seen from the following profiling that "AdaptiveMonteCarlo" uses nearly three times fewer sampling points than the crude "MonteCarlo" strategy.
"MultiPeriodic"
The strategy "MultiPeriodic" transforms all integrals into integrals over the unit cube and periodizes the integrands to be one periodic with respect to each integration variable. Different periodizing functions (or none) can be applied to different variables. "MultiPeriodic" works for integrals with dimension less than or equal to 12. If "MultiPeriodic" is given for integrals with higher dimension, the "MonteCarlo" strategy is used.
option name | default value | |
| "Transformation" | SidiSin | periodizing transformation applied to the integrand |
| "MinPoints" | 0 | minimal number of sampling points |
| "MaxPoints" | 105 | maximum number of sampling points |
| "SymbolicProcessing" | Automatic | number of seconds to be used for symbolic preprocessing |
"MultiPeriodic" can be seen as a multidimensional generalization of the strategy "Trapezoidal". It can also be seen as a quasi Monte Carlo method.
"MultiPeriodic" uses lattice integration rules; see [SloanJoe94] [KrUeb98].
Here integration lattice in ![]() ,
, ![]() , is understood to be a discrete subset of
, is understood to be a discrete subset of ![]() that is closed under addition and subtraction, and that contains
that is closed under addition and subtraction, and that contains ![]() . A lattice integration rule [SloanJoe94] is a rule of the form
. A lattice integration rule [SloanJoe94] is a rule of the form
where ![]() are all the points of an integration lattice contained in
are all the points of an integration lattice contained in ![]() .
.
If "MultiPeriodic" is called on, a ![]() -dimensional integral option "Transformation" takes a list of one-argument functions
-dimensional integral option "Transformation" takes a list of one-argument functions ![]() that is used to transform the corresponding variables. If "Transformation" is given a list with length
that is used to transform the corresponding variables. If "Transformation" is given a list with length ![]() smaller than
smaller than ![]() , then the last function,
, then the last function, ![]() , is used for the last
, is used for the last ![]() integration variables. If "Transformation" is given a function, that function will be used to transform all the variables.
integration variables. If "Transformation" is given a function, that function will be used to transform all the variables.
Let ![]() be the dimension of the integral. If
be the dimension of the integral. If ![]() , "MultiPeriodic" calls "Trapezoidal" after applying the periodizing transformation. For dimensions higher than 12, "MonteCarlo" is called without applying periodizing transformations. "MultiPeriodic" uses the so-called
, "MultiPeriodic" calls "Trapezoidal" after applying the periodizing transformation. For dimensions higher than 12, "MonteCarlo" is called without applying periodizing transformations. "MultiPeriodic" uses the so-called ![]() copy rules for
copy rules for ![]() . For each
. For each ![]() , "MultiPeriodic" has a set of copy rules that are used to compute a sequence of integral estimates. The rules with a smaller number of points are used first. If the error estimate of a rule satisfies the precision goal, or if the difference of two integral estimates in the sequence satisfies the precision goal, the integration stops.
, "MultiPeriodic" has a set of copy rules that are used to compute a sequence of integral estimates. The rules with a smaller number of points are used first. If the error estimate of a rule satisfies the precision goal, or if the difference of two integral estimates in the sequence satisfies the precision goal, the integration stops.
Comparison with "MultidimensionalRule"
Generally "MultiPeriodic" is slower than "GlobalAdaptive" using "MultidimensionalRule". For computing high-dimension integrals with lower precision, "MultiPeriodic" might give results faster.
Preprocessors
The capabilities of all strategies are extended through symbolic preprocessing of the integrals. The preprocessors can be seen as strategies that delegate integration to other strategies (preprocessors included).
"SymbolicPiecewiseSubdivision"
"SymbolicPiecewiseSubdivision" is a preprocessor that divides an integral with a piecewise integrand into integrals with disjoint integration regions on each of which the integrand is not piecewise.
option name | default value | |
| Method | Automatic | integration strategy or preprocessor to which the integration will be passed |
| "ExpandSpecialPiecewise" | True | which piecewise functions should be expanded |
| TimeConstraint | 5 | the maximum number of seconds for which the piecewise subdivision will be attempted |
| "MaxPiecewiseCases" | 100 | the maximum number of subregions the piecewise preprocessor can return |
| "SymbolicProcessing" | Automatic | number of seconds to do symbolic preprocessing |
Options of "SymbolicPiecewiseSubdivision".
As was mentioned at the beginning of the tutorial, NIntegrate is able to integrate simultaneously integrals with disjoint domains, each having a different integrand. Hence, after the preprocessing with "SymbolicPiecewiseSubdivision" the integration continues in the same way as if, say, NIntegrate were given ranges with singularity specifications (which can be seen as specifying integrals with disjoint domains with the same integrand). For example, the strategy "GlobalAdaptive" tries to improve the integral estimate of the region with the largest error through bisection, and will choose that largest error region regardless of which integrand it corresponds to.
"ExpandSpecialPiecewise"
In some cases it is preferable to do piecewise expansion only over certain piecewise functions. In these cases the option "ExpandSpecialPiecewise" can be given a list of functions with which to do the piecewise expansion.
"EvenOddSubdivision"
"EvenOddSubdivision" is a preprocessor that reduces the integration region if the region is symmetric around the origin and the integrand is determined to be even or odd. The convergence of odd integrals is verified by default.
option name | default value | |
| Method | Automatic | integration strategy or preprocessor to which the integration will be passed |
| VerifyConvergence | Automatic | whether the convergence should be verified if an odd integral is detected |
| "SymbolicProcessing" | Automatic | number of seconds to do symbolic preprocessing |
Options of "EvenOddSubdivision".
When the integrand is an even function and the integration region is symmetric around the origin, the integral can be computed by integrating only on some part of the integration region and multiplying with a corresponding factor.
Transformation Theorem
The preprocessor "EvenOddSubdivision" is based on the following theorem.
Theorem: Given the ![]() -dimensional integral
-dimensional integral
assume that for some ![]() these equalities hold:
these equalities hold:
In other words the range of ![]() is symmetric around the origin, and the boundaries of the variables
is symmetric around the origin, and the boundaries of the variables ![]() are even functions with respect to
are even functions with respect to ![]() .
.
a) the integral is equivalent to
if the integrand is even with respect to ![]() , that is,
, that is,
b) the integral is equivalent to 0 if the integrand is odd with respect to ![]() , that is,
, that is,
Note that the theorem above can be applied several times over an integral.
To illustrate the theorem consider the integral ![]() . It is symmetric along
. It is symmetric along ![]() , and the integrand and the bounds of
, and the integrand and the bounds of ![]() are even functions with respect to
are even functions with respect to ![]() .
.
If the bounds of ![]() are not even functions with respect to
are not even functions with respect to ![]() then the symmetry along
then the symmetry along ![]() is broken. For example, the integral
is broken. For example, the integral ![]() has no symmetry NIntegrate can exploit.
has no symmetry NIntegrate can exploit.
"VerifyConvergence"
"OscillatorySelection"
"OscillatorySelection" is a preprocessor that selects specialized algorithms for efficient evaluation of oscillatory integrals.
On each integration region, "OscillatorySelection" detects whether the integrand is of Fourier finite-range type, Fourier infinite-range type (see "DoubleExponentialOscillatory"), Bessel infinite-range type (see "ExtrapolatingOscillatory"), Levin type (see "LevinRule"), or no special oscillatory type. Options control which method is selected for each type of integrand.
option name | default value | |
| "BesselInfiniteRangeMethod" | Automatic | method for infinite-range Bessel integrals |
| "FourierFiniteRangeMethod" | Automatic | method for finite-range Fourier integrals |
| "FourierInfiniteRangeMethod" | Automatic | method for infinite-range Fourier integrals |
| "LevinMethod" | Automatic | method for Levin-type oscillatory integrals |
| Method | "GlobalAdaptive" | method for non-oscillatory integrals |
| "TermwiseOscillatory" | False | whether to separately process terms in a sum |
| "SymbolicProcessing" | 5 | number of seconds to do symbolic processing |
"OscillatorySelection" method options.

The preprocessor "OscillatorySelection" is designed to work with the internal output of the "SymbolicPiecewiseSubdivision" preprocessor. "OscillatorySelection" itself partitions oscillatory integrals that include the origin or have oscillatory kernels that need to be expanded or transformed into forms for which the oscillatory algorithms are designed.
| x∈(-∞,0] | "BesselInfiniteRangeMethod" |
| x∈[0,20] | "FourierFiniteRangeMethod" |
| x∈[30,∞) | "FourierInfiniteRangeMethod" |
| x∈[20,30] | Method |
The value Automatic for the option "FourierFiniteRangeMethod" means that if the integration strategy specified with the option Method is one of "GlobalAdaptive" or "LocalAdaptive" then that strategy will be used for the finite-range Fourier integration, otherwise "GlobalAdaptive" will be used.
If the application of a particular oscillatory method is desired for a particular type of oscillatory integrals, either the corresponding options of "OscillatorySelection" should be changed, or the Method option in NIntegrate should be used without the preprocessor "OscillatorySelection".
"UnitCubeRescaling"
"UnitCubeRescaling" is a preprocessor that transforms the integration region into a unit cube or hypercube. The variables of the original integrand are replaced and the result is multiplied by the Jacobian of the transformation.
option name | default value | |
| "FunctionalRangesOnly" | True | what ranges should be transformed to the unit cube |
| Method | "GlobalAdaptive" | integration strategy or preprocessor to which the integration will be passed |
| "SymbolicProcessing" | Automatic | number of seconds to do symbolic processing |
Options of "UnitCubeRescaling".
"UnitCubeRescaling" transforms the integral
into an integral over the hypercube ![]() . Assuming that
. Assuming that ![]() and
and ![]() are finite and
are finite and ![]() are piecewise continuous functions, the transformation used by "UnitCubeRescaling" is
are piecewise continuous functions, the transformation used by "UnitCubeRescaling" is
The Jacobian of this transformation is
If for the ![]() th axis one or both of
th axis one or both of ![]() and
and ![]() are infinite, then the formula for
are infinite, then the formula for ![]() in (47) is a non-affine transformation that maps
in (47) is a non-affine transformation that maps ![]() into
into ![]() . NIntegrate uses the following transformations:
. NIntegrate uses the following transformations:
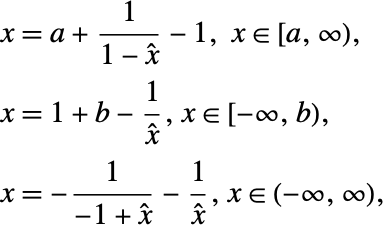
Applying "UnitCubeRescaling" makes the integrand more complicated if the integration region boundaries are constants (finite or infinite). Since NIntegrate has efficient affine and infinite internal variable transformations the integration process would become slower. If some of the integration region boundaries are functions, applying "UnitCubeRescaling" would make the integration faster since the computations that involve the integration variables are done only when the integrand is evaluated. Because of these performance considerations, "UnitCubeRescaling" has the option "FunctionalRangesOnly". If "FunctionalRangesOnly" is set to True the rescaling is applied only to multidimensional functional ranges.
Example Implementation
The transformation process used by "UnitCubeRescaling" is the same as the following one implemented by the function FRangesToCube (also defined in "Duffy's Coordinates Generalization and Example Implementation").
Each transformation of the transformation (50) can be done with Rescale.
Note that for given axis ![]() the transformation rules already derived for axes
the transformation rules already derived for axes ![]() need to be applied to the original boundaries before the rescaling of boundaries along the
need to be applied to the original boundaries before the rescaling of boundaries along the ![]() th axis.
th axis.
"SymbolicPreprocessing"
"SymbolicPreprocessing" is a composite preprocessor made to simplify the switching on and off of the other preprocessors.
option name | default value | |
| Method | Automatic | integration strategy or preprocessor to which the integration will be passed |
| "SymbolicPiecewiseSubdivision" | True | piecewise subdivision |
| "EvenOddSubdivision" | True | even-odd subdivision |
| "OscillatorySelection" | True | detection of products with an oscillatory function |
| "UnitCubeRescaling" | Automatic | rescaling to the unit hypercube |
| "SymbolicProcessing" | Automatic | number of seconds to do symbolic processing |
"SymbolicPreprocessing" options.
When "UnitCubeRescaling" is set to Automatic it is applied only to multidimensional functional ranges.