

NetPortGradient
NetPortGradient["port"]
represents the gradient of the output of a net with respect to the value of the specified input port.
NetPortGradient["param"]
represents the gradient of the output with respect to a learned parameter named param.
NetPortGradient[{layer1,layer2,…,"param"}]
represents the gradient with respect to a parameter at a specific position in a net.
represents the gradients with respect to all inputs and parameters.
Details
- NetPortGradient is typically used to calculate gradients with respect to both learned parameters of a network and inputs to the network.
- net[data,NetPortGradient[iport]] can be used to obtain the gradient with respect to the input port iport for a net applied to the specified data.
- net[<…,NetPortGradient[oport]ograd>,NetPortGradient[iport]] can be used to impose a gradient at an output port oport that will be backpropogated to calculate the gradient at iport.
- For a net with a single scalar output port, the gradient returned when using NetPortGradient is the gradient in the ordinary mathematical sense: for a net computing
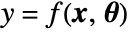 , where
, where 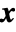 is the array whose gradient is being calculated and
is the array whose gradient is being calculated and 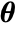 represents all other arrays, the gradient is an array of the same rank as
represents all other arrays, the gradient is an array of the same rank as 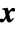 , whose components are given by
, whose components are given by 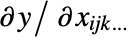 . Intuitively, the gradient at a specific value of
. Intuitively, the gradient at a specific value of 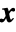 is the "best direction" in which to perturb
is the "best direction" in which to perturb 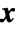 if the goal is to increase
if the goal is to increase 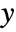 , where the magnitude of the gradient is proportional to the sensitivity of
, where the magnitude of the gradient is proportional to the sensitivity of 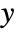 to changes in
to changes in 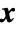 .
. - For a net with vector or array outputs, the gradient returned when using NetPortGradient is the ordinary gradient of the scalar sum of all outputs. Imposing a gradient at the output using the syntax <…,NetPortGradient[oport]ograd> is equivalent to replacing this scalar sum with a dot product between the output and ograd.
- Using NetPortGradient to calculate the gradient with respect to the learned parameters of the net will return the sum of the gradient over the input batch.
Examples
open all close allBasic Examples (1)
Create an elementwise layer and return the derivative of the input with respect to the output:
layer = ElementwiseLayer[Ramp]The Ramp function is equal to the identity function for positive inputs, so in this case the derivative is 1:
layer[1, NetPortGradient["Input"]]The Ramp function constant for negative inputs, so in this case the derivative is 0:
layer[-1, NetPortGradient["Input"]]Scope (4)
Randomly initialize a LinearLayer and return the derivative of the output with respect to the input for a specific input value:
layer = NetInitialize@LinearLayer["Input" -> 3, "Output" -> "Real"]layer[{4, 5, -2}, NetPortGradient["Input"]]Compare with a naive numeric calculation:
nd[f_, x_, dx_] := (f[x + dx] - f[x]) / Norm[dx];
Table[nd[layer, {4, 5, -2}, UnitVector[3, i] / 1000], {i, 3}]Create a binary cross-entropy loss layer:
loss = CrossEntropyLossLayer["Binary"]Evaluate the loss for an input and target:
loss[<|"Input" -> 0.6, "Target" -> 0.8|>]The derivative of the input is negative because the input is below the target (increasing the input would lower the loss):
loss[<|"Input" -> 0.6, "Target" -> 0.8|>, NetPortGradient["Input"]]The derivative of the input is positive when the input is above the target:
loss[<|"Input" -> 0.9, "Target" -> 0.8|>, NetPortGradient["Input"]]The derivative is zero when the input and target are equal:
loss[<|"Input" -> 0.6, "Target" -> 0.6|>, NetPortGradient["Input"]]Randomly initialize a chain of linear layers:
net = NetInitialize@NetChain[{3, Tanh, 5}, "Input" -> 2]Return the derivative of the output with respect to the weights and biases of the first layer, for a specific input value:
net[{2, -1}, NetPortGradient[{1, "Weights"}]]net[{2, -1}, NetPortGradient[{1, "Biases"}]]Calculate the gradient at the input:
net[{2, -1}, NetPortGradient["Input"]]Impose a gradient at the output:
net[<|"Input" -> {2, -1}, NetPortGradient["Output"] -> {1, 0, 0, 0, 0}|>, NetPortGradient["Input"]]Compute all the gradients in one call:
net[{2, -1}, NetPortGradient[All]]Chain a PoolingLayer to a PartLayer that extracts the red color channel:
pool = NetChain[{PoolingLayer[10, "Input" -> "Image"], PartLayer[1]}]Calculate the input gradient on a test image:
grad = pool[[image], NetPortGradient["Input"]];Visualize the gradient, which shows that the total output of this net would only be increased if pixels are reddened that are far from the existing red or white areas:
grad//NetDecoder["Image"]Properties & Relations (1)
The default gradient assumed at an output array is an array consisting of 1s.
Randomly initialize a chain of linear layers:
layer = ElementwiseLayer[LogisticSigmoid, "Input" -> 3]Calculate the gradient at the input:
layer[{-2, 0, 2}, NetPortGradient["Input"]]This is equivalent to imposing a gradient at the output that consists of all 1s:
layer[<|"Input" -> {-2, 0, 2}, NetPortGradient["Output"] -> {1, 1, 1}|>, NetPortGradient["Input"]]Impose a different gradient at the output:
layer[<|"Input" -> {-2, 0, 2}, NetPortGradient["Output"] -> {0, 1, 2}|>, NetPortGradient["Input"]]Possible Issues (1)
The gradient for any learned parameters in the net will be totaled over a batch of input examples:
layers = NetInitialize@NetChain[{3, Tanh, 5}, "Input" -> 2]layers[{2, -1}, NetPortGradient[{1, "Weights"}]]layers[{{2, -1}, {2, -1}}, NetPortGradient[{1, "Weights"}]]Text
Wolfram Research (2017), NetPortGradient, Wolfram Language function, https://reference.wolfram.com/language/ref/NetPortGradient.html (updated 2022).
CMS
Wolfram Language. 2017. "NetPortGradient." Wolfram Language & System Documentation Center. Wolfram Research. Last Modified 2022. https://reference.wolfram.com/language/ref/NetPortGradient.html.
APA
Wolfram Language. (2017). NetPortGradient. Wolfram Language & System Documentation Center. Retrieved from https://reference.wolfram.com/language/ref/NetPortGradient.html