FASTA (.fasta, .fa, .fna, .fsa, .mpfa)
FASTA (.fasta, .fa, .fna, .fsa, .mpfa)
背景

-
- MIME 类型:chemical/seq-aa-fasta, chemical/seq-na-fasta
- FASTA 分子生物学格式.
- 用于存储和交换 DNA 和蛋白序列的标准格式.
- 纯文本格式.
- 把核酸或蛋白序列存储为字符串.
- 使用各种常规代表元信息.
- 由 William Pearson 和 David Lipman 于1988年开发,作为 FASTA 序列排比软件的一部分.
Import 与 Export
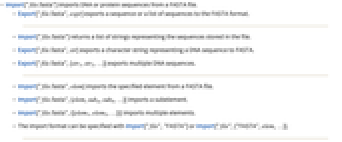
- Import["file.fasta"] 从一个 FASTA 文件中导入 DNA 或蛋白质序列.
- Export["file.fasta",expr] 把一个序列或序列列表导出至 FASTA 格式.
- Import["file.fasta"] 返回一个代表存储在文件中的序列的字符串列表.
- Export["file.fasta",str] 把一个代表 DNA 序列的字符字符串导出至 FASTA.
- Export["file.fasta",{str1,str2,…}] 导出多个 DNA 序列.
- Import["file.fasta",elem] 从一个 FASTA 文件中导入指定的参数.
- Import["file.fasta",{elem,suba,subb,…}] 导入一个子参数.
- Import["file.fasta",{{elem1,elem2,…}}] 导入多个参数.
- 导入格式可以用 Import["file","FASTA"] 或 Import["file",{"FASTA",elem,…}] 指定.
- Export["file.fasta",expr,elem] 通过把 expr 作为指定参数 elem 创建一个 FASTA 文件.
- Export["file.fasta",{expr1,expr2,…},{{elem1,elem2,…}}] 把每一个 expri 指定为相应的 elemi.
- Export["file.fasta",expr,opt1->val1,…] 导出具有指定值的指定选项参数的 expr.
- Export["file.fasta",{elem1->expr1,elem2->expr2,…},"Rules"] 使用规则指定要导出的参数.
- 请到以下参考页面了解完整的基本信息:
-
Import, Export 从文件导入或导出到文件 CloudImport, CloudExport 从云对象导入或导出到云对象 ImportString, ExportString 从字符串导入或导出到字符串 ImportByteArray, ExportByteArray 从字节数组导入或导出到字节数组
导入参数



- Import 的通用参数:
-
"Elements" 该文件可用的参数和选项列表 "Summary" 文件摘要 "Rules" 所有可用参数的规则列表 - 表示数据的参数:
-
"Header" 原始标头行 "Sequence" 字符串列表形式的 DNA 或蛋白序列 "Plaintext" 作为格式化文本的序列 - 对于 FASTA 格式,默认情况下,Import 使用"Sequence"参数.
- 其他数据参数:
-
"Data" "Header"与"Sequence"参数组成的列表 "LabeledData" 用于每个存储在文件中的序列的规则列表 - 标头行元信息:
-
"Accession" 每个序列的 NCBI 登录号 "Description" 每个序列基因座描述文本 "GenBankID" GenBank 数据库标识符 "Length" 整数列表,表示每个序列的长度 - Wolfram 语言对核酸使用标准的 IUB/IUPAC 缩写:
-
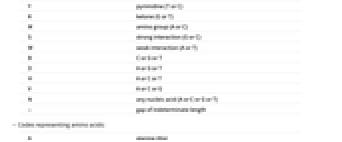
A 腺苷(adenosine) C 胞苷(cytidine) G 鸟嘌呤(guanine) T 胸苷(thymidine) U 尿嘧啶(uracil) R 嘌呤(purine)(G 或 A) Y 嘧啶(pyrimidine)(T 或 C) K 酮(ketone)(G 或 T) M 氨基酸组(amino group)(A 或 C) S 强相互作用(strong interaction)(G 或 C) W 弱相互作用(weak interaction)(A 或 T) B C 或 G 或 T D A 或 G 或 T H A 或 C 或 T V A 或 C 或 G N 任何核酸(nucleic acid)(A 或 C 或 G 或 T) - 不定长度的间距 - 表示氨基酸的代码:
-
A 丙氨酸(alanine)(Ala) B 天门冬氨酸(aspartic acid)或天冬酰胺( asparagine) C 半胱氨酸(cysteine)(Cys) D 天门冬氨酸(aspartic acid)(Asp) E 谷氨酸(glutamic acid)(Glu) F 苯丙氨酸(phenylalanine)(Phe) G 甘氨酸(glycine)(Gly) H 组氨酸(histidine)(His) I 异亮氨酸(isoleucine)(Ile) K 赖氨酸(lysine)(Lys) L 亮氨酸(leucine)(Leu) M 蛋氨酸(methionine)(Met) N 天门冬酰胺(asparagine)(Asn) P 脯氨酸(proline)(Pro) Q 谷氨酰胺(glutamine)(Gln) R 精氨酸(arginine)(Arg) S 丝氨酸(serine)(Ser) T 苏氨酸(threonine)(Thr) U 硒代半胱氨酸(selenocysteine) V 缬氨酸(valine)(Val) W 色氨酸(tryptophan)(Trp) Y 酪氨酸(tyrosine)(Tyr) Z 谷氨酸(glutamic acid)或谷氨酰胺(glutamine) X 任何氨基酸(amino acid) * 翻译(translation)停止 - 不定长度的间距
选项

- Import 选项:
-
"HeaderFormat" Automatic 指定标头的格式 "ToUpperCase" True 是否使序列为大写 - Import 使用 FASTA 格式的常见变体中标头格式规范中的大型内置库.
- 通过把"HeaderFormat"设置为文字字符串列表和元信息参数名称,任何标头行格式可以在 Import 中指定.
- "HeaderFormat"->{"gi","DatabaseIndex","gb","Accession","","Description"} 是 NCBI FASTA 文件的典型设置.
- 高级的 Export 选项:
-
"LineWidth" 70 一行中的最大字符数 "ToUpperCase" True 是否使序列为大写