TSV (.tsv)
Background & Context
-
- MIME type: text/tab-separated-values
- TSV tabular data format.
- Stores records of numerical and textual information as lines, using tab characters to separate fields.
- TSV is an acronym for Tab-Separated Values.
- Plain text format.
- Similar to CSV.
Import & Export
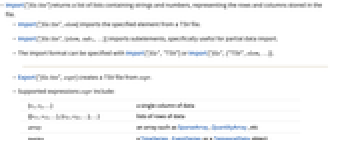
- Import["fte"] returns a list of lists containing strings and numbers, representing the rows and columns stored in the file.
- Import["fte",elem] imports the specified element from a TSV file.
- Import["fte",{elem,sub1,…}] imports subelements, specifically useful for partial data import.
- The import format can be specified with Import["fte","TSV"] or Import["fte",{"TSV",elem,…}].
- Export["fte",expr] creates a TSV file from expr.
- Supported expressions expr include:
-
{v1,v2,…} a single column of data {{v11,v12,…},{v21,v22,…},…} lists of rows of data array an array such as SparseArray, QuantityArray, etc. tseries a TimeSeries, EventSeries or a TemporalData object Dataset[…] a dataset Tabular[…] a tabular object - See the following reference pages for full general information:
-
Import, Export import from or export to a file CloudImport, CloudExport import from or export to a cloud object ImportString, ExportString import from or export to a string ImportByteArray, ExportByteArray import from or export to a byte array
Import Elements
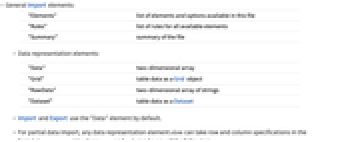


- General Import elements:
-
"Elements" list of elements and options available in this file "Rules" list of rules for all available elements "Summary" summary of the file - Data representation elements:
-
"Data" two-dimensional array "Grid" table data as a Grid object "RawData" two-dimensional array of strings "Dataset" table data as a Dataset "Tabular" table data as a Tabular object - Data descriptor elements:
-
"ColumnLabels" names of columns "ColumnTypes" association of column names and types "Schema" TabularSchema object - Import and Export use the "Data" element by default.
- Subelements for partial data import for any element elem can take row and column specifications in the form {elem,rows,cols}, where rows and cols can be any of the following:
-
n nth row or column -n counts from the end n;;m from n through m n;;m;;s from n through m with steps of s {n1,n2,…} specific rows or columns ni - Metadata elements:
-
"ColumnCount" number of columns "Dimensions" a list of number of rows and maximum number of columns "RowCount" number of rows - Import options:
-
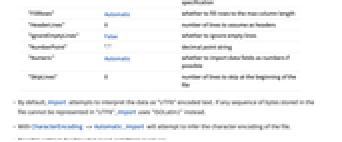
ByteOrdering Automatic ordering of bytes CharacterEncoding "UTF8ISOLatin1" raw character encoding used in the file MissingValuePattern Automatic patterns used to specify missing elements "ColumnTypeDetectionDepth" Automatic number of rows used for header detection "CurrencyTokens" None currency units to be skipped when importing numerical values "DateStringFormat" None date format, given as a DateString specification "EmptyField" "" how to represent empty fields "FieldSeparator" "," string token taken to separate columns "FillRows" Automatic whether to fill rows to the max column length "HeaderLines" Automatic number of lines to assume as headers "IgnoreEmptyLines" True whether to ignore empty lines "NumberPoint" "." decimal point character "Numeric" Automatic whether to import data fields as numbers if possible "QuotingCharacter" "\"" character used to delimit non-numeric fields "Schema" Automatic schema used to construct Tabular object "SkipInvalidLines" False whether to skip invalid lines "SkipLines" Automatic number of lines to skip at the beginning of the file - By default, Import attempts to interpret the data as "UTF8" encoded text. If any sequence of bytes stored in the file cannot be represented in "UTF8", Import uses "ISOLatin1" instead.
- With CharacterEncoding -> Automatic, Import will attempt to infer the character encoding of the file.
- Possible settings for "HeaderLines" and "SkipLines" are:
-
Automatic try to automatically determine the number of rows to skip or use as header n n rows to skip or to use as Dataset headers {rows,cols} rows and columns to skip or to use as headers - Possible settings for the "Schema" option include:
-
schema a complete TabularSchema specification propval a schema property and value (see reference page for TabularSchema) <"fte"val1,…> an association of schema properties and values - Import converts table entries formatted as specified by "DateStringFormat" to a DateObject.
- Double-quote characters delimiting text fields are not imported by default.
Export Elements


- Export options:
-
Alignment None how data is aligned within table columns CharacterEncoding "UTF8" raw character encoding used in the file "EmptyField" "" how to represent empty fields "ExpressionFormattingFunction" Automatic how expressions stored in a Tabular object are converted to strings "FillRows" False whether to fill rows to the max column length "IncludeQuotingCharacter" Automatic whether to add quotations around exported values "QuotingCharacter" "\"" character used to delimit non-numeric fields "TableHeadings" Automatic headings for table columns and rows - Possible settings for Alignment are None, Left, Center and Right.
- "IncludeQuotingCharacter" can be set to the following values:
-
None do not enclose any values in quotes Automatic only enclose values in quotes when needed All enclose all valid values in quotes - Data fields containing commas and line separators are typically wrapped in double-quote characters. By default, Export uses double-quote characters as delimiters. Specify a different character using "QuotingCharacter".
- "TableHeadings" can be set to the following values:
-
None skip column labels Automatic export column labels {"fte","fte",…} list of column labels {rhead,chead} specifies separate labels for the rows and columns - "ExpressionFormattingFunction" can be set to the following values:
-
Automatic default conversion to string form any form supported by Format, such as InputForm f arbitrary function that converts an expression to a string - Export encodes line separator characters using the convention of the computer system on which the Wolfram Language is being run.
Examples
open all close allBasic Examples (3)
Scope (8)
Import (4)
Import metadata from a CSV file:
Import a TSV file as a Tabular object with automatic header detection:
Import without headers, while skipping the first line:
Analyze a single column of a file; start by looking at column labels and their types:
Export (4)
Export a Tabular object:
Use "TableHeadings" option to remove header from a Tabular object:
Export a TimeSeries:
Export an EventSeries:
Export a QuantityArray:
Import Elements (26)
"Data" (6)
"Dataset" (3)
Import a TSV file as a Dataset:
"Dimensions" (1)
"Grid" (1)
Import TSV data as a Grid:
"RawData" (3)
"Schema" (1)
Get the TabularSchema object:
"Tabular" (6)
Import a CSV file as a Tabular object:
Use "HeaderLines" and "SkipLines" options to only import the data of interest:
Import Options (15)
CharacterEncoding (1)
The character encoding can be set to any value from $CharacterEncodings:
"ColumnTypeDetectionDepth" (1)
"CurrencyTokens" (1)
"DateStringFormat" (1)
Convert dates to a DateObject using the date format specified:
"FillRows" (1)
"HeaderLines" (1)
MissingValuePattern (1)
By default, an automatic set of values is considered missing:
Use MissingValuePatternNone to disable missing element detection:
"Numeric" (1)
Use "Numeric"->True to interpret numbers:
"NumberPoint" (1)
"QuotingCharacter" (1)
"Schema" (1)
Import automatically infers column labels and types from data stored in a TSV file:
"SkipLines" (1)
TSV files may include a comment line:
Skip the comment line and use the next line as a Tabular header:
Export Options (8)
Alignment (1)
CharacterEncoding (1)
The character encoding can be set to any value from $CharacterEncodings:
"EmptyField" (1)
"ExpressionFormattingFunction" (1)
"IncludeQuotingCharacter" (1)
"QuotingCharacter" (1)
"TableHeadings" (1)
By default, column headers are exported:
Use "TableHeadings"None to skip column headers:
Applications (1)
Possible Issues (12)
For ragged arrays, where rows have different numbers of columns, some rows may be considered as invalid:
Use "Backend""Table" to avoid skipping those rows:
Entries of the format "nnnDnnn" or "nnnEnnn" are interpreted as numbers with scientific notation:
Use the "Numeric" option to override this interpretation:
Numeric interpretation may result in a loss of precision:
Use the "Numeric" option to override this interpretation:
Starting from Version 14.2, currency tokens are not automatically skipped:
Use the "CurencyTokens" option to skip such tokens:
Starting from Version 14.2, quoting characters are added when the column of integer values contains numbers greater than Developer`$MaxMachineInteger:
Use "IncludeQuotingCharacter"->None to get the previous result:
Starting from Version 14.2, some strings are automatically considered missing:
Use MissingValuePatternNone to override this interpretation:
Starting from Version 14.2, real numbers with 0 fractional part are exported as integers:
Use "Backend"->"Table" to get the previous result:
Starting from Version 14.2, integers greater than Developer`$MaxMachineInteger are imported as real numbers:
Use "Backend"->"Table" to get the previous result:
Starting from Version 14.2, date and time columns of Tabular objects are exported using DateString:
Use "Backend"->"Table" to get the previous result:
Some TSV data generated from older versions of the Wolfram Language may have incorrectly delimited text fields and will not import as expected in Version 11.2 or higher:
Using "QuotingCharacter""" will give the previously expected result:
The top-left corner of data is lost when importing a Dataset with row and column headers:
Dataset may look different depending on the dimensions of the data: