Numerical Solution of Differential-Algebraic Equations
| Introduction | Index Reduction for DAEs |
| Index of a DAE | Consistent Initialization of DAEs |
| Treatment of Differential Equations | DAE Examples |
| DAE Solution Methods |
Introduction
In general, a system of ordinary differential equations (ODEs) can be expressed in the normal form,
The derivatives of the dependent variables ![]() are expressed explicitly in terms of the independent transient variable
are expressed explicitly in terms of the independent transient variable ![]() and the dependent variables
and the dependent variables ![]() . As long as the function
. As long as the function ![]() has sufficient continuity, a unique solution can always be found for an initial value problem where the values of the dependent variables are given at a specific value of the independent variable.
has sufficient continuity, a unique solution can always be found for an initial value problem where the values of the dependent variables are given at a specific value of the independent variable.
With differential-algebraic equations (DAEs), the derivatives are not, in general, expressed explicitly. In fact, derivatives of some of the dependent variables typically do not appear in the equations. For example, the following equation
does not explicitly contain any derivatives of ![]() . Such variables are often referred to as algebraic variables.
. Such variables are often referred to as algebraic variables.
The general form of a system of DAEs is
Solving systems of DAEs often involves many steps. The flow chart shown below indicates the general process associated with solving DAEs in NDSolve.

Flow chart of steps involved in solving DAE systems in NDSolve.
Generally, a system of DAEs can be converted to a system of ODEs by differentiating it with respect to the independent variable ![]() . The index of a DAE is the number of times needed to differentiate the DAEs to get a system of ODEs.
. The index of a DAE is the number of times needed to differentiate the DAEs to get a system of ODEs.
The DAE solver methods built into NDSolve work with index-1 systems, so for higher-index systems an index reduction may be necessary to get a solution. NDSolve can be instructed to perform that index reduction. When a system is found to have an index greater than 1, NDSolve generates a message and number of steps need to be taken in order to solve the DAE.
As a first step for high-index DAEs, the index of the system needs to be reduced. The process of differentiating to reduce the index, referred to as index reduction, can be done in NDSolve with a symbolic process.
The process of index reduction leads to a new equivalent system. In one approach, this new system is restructured by substituting new (dummy) variables in place of the differentiated variables. This leads to an expanded system that then can be uniquely solved. Another approach for restructuring the system involves differentiating the original system ![]() number of times until the differentials for all the variables are accounted for. The preceding
number of times until the differentials for all the variables are accounted for. The preceding ![]() differentiated systems are treated as invariants.
differentiated systems are treated as invariants.
In order to solve the new index-reduced system, a consistent set of initial conditions must be found. A system of ODEs in normal form, ![]() , can always be initialized by giving values for
, can always be initialized by giving values for ![]() at the starting time. However, for DAEs it may be difficult to find initial conditions that satisfy the residual equation
at the starting time. However, for DAEs it may be difficult to find initial conditions that satisfy the residual equation ![]() ; this amounts to solving a nonlinear algebraic system where only some variables may be independently specified. This will be discussed in further detail in a a later section. Furthermore, the initialization needs to be consistent. This means that the derivatives of the residual equations
; this amounts to solving a nonlinear algebraic system where only some variables may be independently specified. This will be discussed in further detail in a a later section. Furthermore, the initialization needs to be consistent. This means that the derivatives of the residual equations ![]() also need to be satisfied. Commonly, higher-index systems are harder to initialize. In this case NDSolve cannot, in general, see how the components of
also need to be satisfied. Commonly, higher-index systems are harder to initialize. In this case NDSolve cannot, in general, see how the components of ![]() interact and is thus not able do an automatic index reduction. NDSolve, however, has a number of different methods, accessible via options, to perform index reduction and find a consistent initialization of DAEs.
interact and is thus not able do an automatic index reduction. NDSolve, however, has a number of different methods, accessible via options, to perform index reduction and find a consistent initialization of DAEs.
The remainder of this document is structured in the following manner: first, some terminology around indices of DAEs is introduced. Following that, the next section treats solving of index-1 DAEs. Next, methods for index reduction of higher-order index DAEs are presented. Consistent initialization of DAEs is treated subsequently. In addition to the examples in the sections mentioned so far, an entire last section with additional examples is given.
Needs["DifferentialEquations`InterpolatingFunctionAnatomy`"];
Needs["DifferentialEquations`NDSolveUtilities`"];Index of a DAE
For a general DAE system ![]() , the index of the system refers to the minimum number of differentiations of part or all the equations in the system that would be required to solve for
, the index of the system refers to the minimum number of differentiations of part or all the equations in the system that would be required to solve for ![]() uniquely in terms of
uniquely in terms of ![]() and
and ![]() . Note that there are many slightly different concepts of index in the literature; for the purpose of this document the preceding concept will be used.
. Note that there are many slightly different concepts of index in the literature; for the purpose of this document the preceding concept will be used.
In order to get a differential equation for ![]() , the first equation must be differentiated once. This leads to the new system
, the first equation must be differentiated once. This leads to the new system
The differentiated system now contains ![]() , which must be accounted for. To get an equation for
, which must be accounted for. To get an equation for ![]() , the second equation must now be differentiated three times. This leads to
, the second equation must now be differentiated three times. This leads to
Since part of the system had to be differentiated three times to get a derivative equation for ![]() , the index of the DAE is 3. The final differentiated system is said to be an index-0 system. To see ODEs that are obtained by the differentiations, you can perform appropriate substitutions, in this case subtracting the second equation from the first. The resulting equation can be written as
, the index of the DAE is 3. The final differentiated system is said to be an index-0 system. To see ODEs that are obtained by the differentiations, you can perform appropriate substitutions, in this case subtracting the second equation from the first. The resulting equation can be written as
Similarly, the index-1 system can be found by differentiating the second equation twice, resulting in the following system
It is typical to reduce the index of the system to 1, since the underlying integration routines can handle them efficiently.
The index of a DAE may not always be obvious. Consider a system that may exhibit index-1 or index-2 behavior, depending on what the initial conditions are.
DAE = (| |
| ----------------------------------- |
| Derivative[1][x1][t] == x3[t] |
| x2[t] (1 - x2[t]) == 0 |
| x1[t] x2[t] + x3[t] (1 - x2[t]) == t |);For this DAE, the initial conditions are not free; the second equation requires that ![]() be either 0 or 1.
be either 0 or 1.
If ![]() , then the two remaining equations make an index-1 system, since differentiation of the third equation gives a system of two ODEs
, then the two remaining equations make an index-1 system, since differentiation of the third equation gives a system of two ODEs
While the initial condition for ![]() , the initial condition for
, the initial condition for ![]() can be varied.
can be varied.
sol = NDSolve[{DAE, Subscript[x, 1][0] == -1, Subscript[x, 2][0] == 0}, {Subscript[x, 1], Subscript[x, 2], Subscript[x, 3]}, {t, 0, 1}]Plot[Evaluate[{Subscript[x, 1][t], Subscript[x, 2][t], Subscript[x, 3][t]} /. First[sol]], {t, 0, 1}]On the other hand, if ![]() , then the two remaining equations make an index-2 system. Differentiating the third equation gives
, then the two remaining equations make an index-2 system. Differentiating the third equation gives ![]() , and substituting into the first equation gives
, and substituting into the first equation gives ![]() , which needs to be differentiated to get an ODE
, which needs to be differentiated to get an ODE
There are also no additional degrees of freedom in the initial conditions, since ![]() and
and ![]() .
.
sol = NDSolve[{DAE, Subscript[x, 2][0] == 1}, {Subscript[x, 1], Subscript[x, 2], Subscript[x, 3]}, {t, 0, 1}]Plot[Evaluate[{Subscript[x, 1][t], Subscript[x, 2][t], Subscript[x, 3][t]} /. First[sol]], {t, 0, 1}]Both the number of initial conditions needed and the index of a DAE may influence the actual solution being found.
Treatment of Differential Equations
In order to solve a differential equation, NDSolve converts the user-specified system into one of three forms. This step is quite important because depending on how the system is constructed, different integration methods are chosen.
You may specify in which form to represent the equations by using the option Method->{"EquationSimplification"->simplification}. The following simplification methods can be specified for the "EquationSimplification" option.
| Automatic | try to solve the system symbolically in the form |
| "Solve" | solve the system symbolically in the form |
| "MassMatrix" | reduce the system to the form |
| "Residual" | subtract right-hand sides of equations from left-hand sides to form a residual function |
Equation simplification methods.
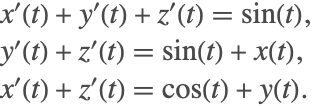
By default, an attempt is made to solve for the derivatives ![]() explicitly in terms of the independent and dependent variables
explicitly in terms of the independent and dependent variables ![]() and
and ![]() . For efficiency purposes, NDSolve first attempts to try to find the explicit system by using LinearSolve. If that fails, however, then the system is solved symbolically using Solve.
. For efficiency purposes, NDSolve first attempts to try to find the explicit system by using LinearSolve. If that fails, however, then the system is solved symbolically using Solve.
state = First@NDSolve`ProcessEquations[{{x'[t] + y'[t] == Sin[t] - z'[t], y'[t] + z'[t] == Sin[t] + x[t], x'[t] + z'[t] == y[t] + Cos[t]}, {x[0] == 1, y[0] == 1, z[0] == 1}}, {x, y, z}, {t}];
state["NumericalFunction"]["FunctionExpression"]Using the "Solve" method is the same as the default when a symbolic solution is found.
state = First@NDSolve`ProcessEquations[{{x'[t] + y'[t] == Sin[t] - z'[t], y'[t] + z'[t] == Sin[t] + x[t], x'[t] + z'[t] == y[t] + Cos[t]}, {x[0] == 1, y[0] == 1, z[0] == 1}}, {x, y, z}, {t}, Method -> {"EquationSimplification" -> "MassMatrix"}];
state["NumericalFunction"]["FunctionExpression"]state["MassMatrix"] // MatrixFormstate = First@NDSolve`ProcessEquations[{{x'[t] + y'[t] == Sin[t] - z'[t], y'[t] + z'[t] == Sin[t] + x[t], x'[t] + z'[t] == y[t] + Cos[t]}, {x[0] == 1, y[0] == 1, z[0] == 1}}, {x, y, z}, {t}, Method -> {"EquationSimplification" -> "Residual"}];
state["NumericalFunction"]["FunctionExpression"]When the system is put in a residual form, the derivatives are represented by a new set of variables that are generated to be unique symbols. You can get the correspondence between these working variables and the specified variables using the "Variables" and "WorkingVariables" properties of NDSolveStateData.
Flatten[MapThread[Thread[Rule[##]]& , {state["Variables"], state["WorkingVariables"]}]]The process of generating an explicit system of ODEs may sometimes become expensive due to the symbolic treatment of the system. For this reason, there is a time constraint of one second put on obtaining the equations. If that time is exceeded, then NDSolve generates a message and attempts to solve the system as a DAE.
vars = {x, y, z};
eqns = { x'[t] + y'[t] ^ 2 + z'[t] ^ 2 == Sin[t], x'[t] y'[t] + z'[t] == Sin[t] + x[t], x'[t] + z'[t] == y[t] + Cos[t]};
ics = {x[0] == 1, y[0] == -1, z[0] == 1};NDSolve[{eqns, ics}, vars, {t, 0, 1}]The following method options can be specified to the simplification methods to better control the behavior of "EquationSimplification".
option name | default value | |
| "TimeConstraint" | 1 | maximum time in seconds allowed for Solve to explicitly solve for the derivatives |
| "SimplifySystem" | False | whether to simplify by obtaining analytic solutions for as many dependent variables as possible |
As indicated by the message, NDSolve did not solve explicitly for the derivatives because Solve had exceeded the default time constraint of one second. The amount of time that NDSolve spends on obtaining an explicit expression can be controlled using the option "TimeConstraint".
NDSolve[{eqns, ics}, vars, {t, 0, 1}, "Method" -> {"EquationSimplification" -> {Automatic, "TimeConstraint" -> 10}}]In the preceding example, due to the square terms in the first equation, four possible solutions are encountered. When solving as a DAE, the numerical solution will only follow one of these solution branches, depending on how it is initialized.
To demonstrate the usage of the method option "SimplifySystem", consider the following example:
An analytic solution for the above system can be obtained by substituting ![]() into the first equation to get a solution for
into the first equation to get a solution for ![]() , which in turn is substituted into the second equation to give a solution for
, which in turn is substituted into the second equation to give a solution for ![]() . The final solution for the system is
. The final solution for the system is
NDSolve cannot solve this system without first performing index reduction of the system and forming a new equivalent system of ODEs. This could prove to be expensive. When the suboption "SimplifySystem" is turned on, NDSolve detects any variable for which an analytic expression/solution can be found and performs repeated substitutions back into the original system. This results in the original system being either simplified or in some cases (like the above) getting back analytic solutions.
NDSolve[{x'[t] + y[t] == Sin[t], y'[t] + z[t] == Sin[t], x[t] == Cos[t]}, {x, y, z}, {t, 0, 1}, Method -> {"EquationSimplification" -> {Automatic, "SimplifySystem" -> True}}]If an analytic solution does not exist for certain variables, then NDSolve will return an interpolating function as the solution.
NDSolve[{x'[t] + y[t] == Sin[t], y'[t] + z[t] == Sin[t], y[t] == Cos[t], x[0] == 1}, {x, y, z}, {t, 0, 1}, Method -> {"EquationSimplification" -> {Automatic, "SimplifySystem" -> True}}]With the suboption turned on, constant parameters can also be directly substituted into the system.
NDSolve[{y''[x] + Sin[a * y[x]]y[x] == b, y[0] == b,
y'[0] == a, a + b == 1, 2a - b == 3}, {y, a, b}, {x, 0, 30}, Method -> {"EquationSimplification" -> {Automatic,
"SimplifySystem" -> True}}]DAE Solution Methods
There are a variety of solution methods built into NDSolve for solving DAEs.
Two methods work with the general residual form of index-1 DAEs, ![]() .
.
- IDA—(Implicit Differential-Algebraic solver from the SUNDIALS package) based on backward differentiation formulas (BDF)
- StateSpace—implicitly solves
 for derivatives
for derivatives 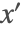 to use an underlying ODE solver
to use an underlying ODE solver
If the system has index higher than 1, both of these solvers typically fail. To accurately solve such systems, index reduction is needed. Note that index-1 systems can be reduced to ODEs, but it is often more efficient to use one of the solvers above.
NDSolve also has some solvers that work with DAEs that can be reduced to special forms.
- Projection—for ODEs
 with invariants
with invariants 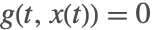
The following subsections describe some aspects of using these methods for DAEs.
ODEs with Invariants
It is common to encounter DAEs of the form
where ![]() is an invariant that is consistent with the differential equations.
is an invariant that is consistent with the differential equations.
When a system of DAEs is converted to ODEs via index reduction, the equations that were differentiated to get the ODE form are consistent with the ODEs, and it is typically important to make sure those equations are well satisfied as the solution is integrated.
Such systems have more equations than unknowns and are overdetermined unless the constraints are consistent with the ODEs. NDSolve does not handle such DAEs directly because it expects a system with the same number of equations and dependent variables. In order to solve such systems, the "Projection" method built into NDSolve handles the invariants by projecting the computed solution onto ![]() after each time step. This ensures that the algebraic equations are satisfied as the solution evolves.
after each time step. This ensures that the algebraic equations are satisfied as the solution evolves.
An example of such a constrained system is a nonlinear oscillator modeling the motion of a pendulum.
equation = x''[t] + Sin[x[t]] == 0;
invariant = x'[t]^2 - 2 Cos[x[t]];
start = {x[0] == 0, x'[0] == 1};Note that the differential equation is effectively the derivative of the invariant, so one way to solve the equation is to use the invariant.
NDSolveValue[{equation, invariant == -1, start}, x, {t, 0, 1000}]psol = NDSolveValue[{equation, start}, x, {t, 0, 1000}, Method -> {"TimeIntegration" -> {"Projection", "Invariants" -> invariant}}]tsteps = First[InterpolatingFunctionCoordinates[psol]];ListPlot[Transpose[{t, invariant + 1 /. x -> psol} /. t -> tsteps]]Solving Systems with a Mass Matrix
When the derivatives appear linearly, a differential system can be written in a form
where ![]() is a matrix often referred to as a mass matrix. Sometimes
is a matrix often referred to as a mass matrix. Sometimes ![]() is also referred to as a damping matrix. If the matrix is nonsingular, then it can be inverted and the system can be solved as an ODE. However, in the presence of a singular matrix, the system can be solved as a DAE. In either case, it may be advantageous to take advantage of the special form.
is also referred to as a damping matrix. If the matrix is nonsingular, then it can be inverted and the system can be solved as an ODE. However, in the presence of a singular matrix, the system can be solved as a DAE. In either case, it may be advantageous to take advantage of the special form.
The system describing the motion of a particle on a cylinder
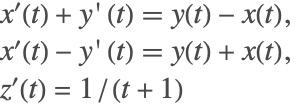
can be expressed in mass matrix form with
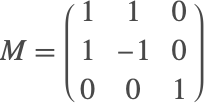
vars = {x[t], y[t], z[t]};
eqns = {x'[t] + y'[t] == y[t] - x[t], x'[t] - y'[t] == x[t] + y[t], z'[t] == 1 / (1 + t)};
init = {x[0] == 1, y[0] == 0, z[0] == 0};sol = NDSolveValue[{eqns, init}, vars, {t, 0, 50}, Method -> {"EquationSimplification" -> "MassMatrix"}];ParametricPlot3D[Evaluate[sol], {t, 0, 50}, BoxRatios -> 1, PlotStyle -> Thick]Index Reduction for DAEs
The built-in solvers for DAEs in NDSolve currently handle index-1 systems of DAEs fully automatically. For higher-index systems, an index reduction is necessary to get to a solution. This index reduction can be performed by giving appropriate options to NDSolve.
NDSolve uses symbolic techniques to do index reduction. This means that if your DAE system is expressed in the form ![]() , where NDSolve cannot see how the components of
, where NDSolve cannot see how the components of ![]() interact and compute symbolic derivatives, the index reduction cannot be done, and for this reason NDSolve does not do index reduction, by default.
interact and compute symbolic derivatives, the index reduction cannot be done, and for this reason NDSolve does not do index reduction, by default.
For an example, consider the classic DAE describing the motion of a pendulum:
where there is a mass ![]() at the point
at the point ![]() constrained by a string of length
constrained by a string of length ![]() .
. ![]() is a Lagrange multiplier that is effectively the tension in the string. For simplicity in the description of index reduction, take
is a Lagrange multiplier that is effectively the tension in the string. For simplicity in the description of index reduction, take ![]() . The figure shows the schematic of the pendulum system.
. The figure shows the schematic of the pendulum system.

Sketch of the forces acting on a pendulum.
If the index of the system is not obvious from the equations, one thing to do is try it in NDSolve, and if the solver is not able to solve it, in many cases it is able to generate a message indicating what the index appears to be for the initial conditions specified.
cpdae = {x''[t] + λ[t] x[t] == 0, y''[t] + λ[t] y[t] == -1, x[t] ^ 2 + y[t] ^ 2 == 1};
cpinit = {x[0] == 1, x'[0] == 0, x''[0] == 0, y[0] == 0, y'[0] == 0, y''[0] == -1, λ[0] == 0};NDSolve[{cpdae, cpinit}, {x, y, λ}, {t, 0, 100}]The message indicates that the index is 3, indicating that index reduction is necessary to solve the system. Note that a complete consistent initialization is used here to avoid possible issues with initialization. This aspect of the solution procedure is treated in "Consistent Initialization of DAEs" with more detail.
The option setting Method->{"IndexReduction"->{irmeth,iropts}} is used to specify that NDSolve uses index reduction method irmeth with general index reduction options iropts.
| None | no index reduction (default) |
| Automatic | choose the method automatically |
| "Pantelides" | graph-based Pantelides algorithm |
| "StructuralMatrix" | structural matrix-based algorithm |
The following options can be given for all index reduction methods.
| "ConstraintMethod" | Automatic | how to handle constraints from specified system |
| "IndexGoal" | Automatic | index to reduce to (1 or 0) |
sol = First[NDSolve[{cpdae, cpinit}, {x, y, λ}, {t, 0, 100}, Method -> {"IndexReduction" -> Automatic}, MaxSteps -> ∞]]Plot[Evaluate[{x[t], y[t]} /. %], {t, 0, 100}]Index reduction is done by differentiating equations in the DAE system. Suppose that an equation eqn is differentiated during the process of index reduction so that deqn=![]() eqn is included in the system in place of eqn. Once the differentiation has been done, the differentiated equations comprise a fully determined system and can be solved on their own. However, it is typically important to incorporate the original equations in the system as constraints. How this is done is controlled by the "ConstraintMethod" index reduction option.
eqn is included in the system in place of eqn. Once the differentiation has been done, the differentiated equations comprise a fully determined system and can be solved on their own. However, it is typically important to incorporate the original equations in the system as constraints. How this is done is controlled by the "ConstraintMethod" index reduction option.
| None | do not keep the original equations as constraints and just solve with the differentiation equations |
| "DummyDerivatives" | use the method of Mattson and Soderlind [MS93] to replace some derivatives with algebraic variables (dummy derivatives) |
| "Projection" | reduce the index to 0 to get an ODE and use the "Projection" time integration method with the original equations that were differentiated as invariants |
ucsol = First[NDSolve[{cpdae, cpinit}, {x, y, λ}, {t, 0, 100}, Method -> {"IndexReduction" -> {Automatic, "ConstraintMethod" -> None}}, MaxSteps -> ∞]];LogPlot[Evaluate[Abs[x[t] ^ 2 + y[t] ^ 2 - 1] /. {sol, ucsol}], {t, 0, 100}]In the numerical solution with just the differentiated equations, the length of the pendulum is drifting away from 1. Incorporating the original equations into the solution as constraints is an important aspect of index reduction.
The next two sections will describe index reduction algorithms, followed by an explanation of constraint methods that can be used in NDSolve.
Index Reduction Algorithms
NDSolve has two algorithms for doing index reduction, the Pantelides and the structural matrix methods. Both of these methods use the symbolic form of the equations to determine which equations to differentiate and then use symbolic differentiation to get the differentiated system.
Both methods make use of the concept of structural incidence in the equations; in particular, if variable ![]() appears explicitly in equation
appears explicitly in equation ![]() , then
, then ![]() is termed incident in
is termed incident in ![]() . The structural incidence matrix is the matrix with elements
. The structural incidence matrix is the matrix with elements ![]() if
if ![]() is incident in
is incident in ![]() and otherwise
and otherwise ![]() . A DAE system has structural index 1 if the structural incidence matrix can be reordered so that there are 1s along the diagonal. The existence of such a reordering means that there is a matching between equations and variables such that there is one equation for every variable.
. A DAE system has structural index 1 if the structural incidence matrix can be reordered so that there are 1s along the diagonal. The existence of such a reordering means that there is a matching between equations and variables such that there is one equation for every variable.
The Pantelides algorithm works with a graph based on the incidence that can be very efficient even for extremely large systems.
Note that the structural index may be smaller than the actual index of the system. In the real system, terms that are structurally present may vanish along some solutions or the Jacobian matrix may be singular. The structural matrix method tries to take into account the possibility of singularities in the Jacobian and will do a better job of index reduction for some systems, but at the cost of greater computational expense.
The next section introduces a command for getting the structural incidence matrix that is useful for the descriptions of the Pantelides and structural matrix algorithms that follow in the subsequent sections.
Structural Incidence
| NDSolve`StructuralIncidenceArray[eqns,vars] | return a SparseArray that has the pattern of the structural incidence matrix for the variables vars in the equations eqns |
Getting the structural incidence.
S = NDSolve`StructuralIncidenceArray[{x'[t] == y[t], y[t] == 2 x[t]}, {x'[t], y[t]}]MatrixForm[S]Note that the SparseArray contains just the nonzero pattern that uses less memory and indicates it represents the pattern of incidence. It can be converted to a SparseArray with 1s using ArrayRules.
convertPatternArray[S_SparseArray] := SparseArray[Drop[ArrayRules[S], -1] /. Verbatim[_] -> 1, Dimensions[S]]ArrayRules[S]S1 = convertPatternArray[S]MatrixForm[S1]The system has structural index 1, since no reordering is needed to avoid zeros along the diagonal.
If the structural incidence with respect to the derivative variables can be arranged to avoid zeros on the diagonal, then the system is index 0.
MatrixForm[NDSolve`StructuralIncidenceArray[{x'[t] == y[t], y[t] == 2 x[t]}, {x'[t], y'[t]}]]There is no reordering that will avoid zeros on the diagonal. However, if the second equation is differentiated it is possible.
MatrixForm[NDSolve`StructuralIncidenceArray[{x'[t] == y[t], D[y[t] == 2 x[t], t]}, {x'[t], y'[t]}]]The differentiated system has structural index 0, verifying that the original system was index 1.
Consider the constrained pendulum (2) as another example.
MatrixForm[NDSolve`StructuralIncidenceArray[cpdae, {x''[t], y''[t], λ[t]}]]The matrix cannot be reordered to avoid zeros on the diagonal, so the index is greater than 1.
Note that the function NDSolve`StructuralIncidenceArray just does a literal matching on the FullForm of the expression to check for the incidence. It does not do any checking to see if your equations or variables are properly formed.
MatrixForm[NDSolve`StructuralIncidenceArray[{x'[t] == y[t], y[t] == 2 x[t]}, {x, y}]]This is a full matrix because the FullForm of x'[t] is Derivative[1][x][t] that contains x.
Pantelides Method
The method proposed by Pantelides [P88] is a graph theoretical method that was originally proposed for finding consistent initialization of DAEs. It works with a bipartite graph of dependent variables and equations, and when the algorithm can find a traversal of the graph, then the system has been reduced to index at most 1. A traversal in this sense effectively means an ordering of variables and equations so that the graph's incidence matrix has no zeros on the diagonal.
When the bipartite graph does not have a complete traversal, the algorithm effectively augments the path by differentiating equations, introducing new variables (derivatives of previous variables) in the process. Unless the original system is structurally singular, the algorithm will terminate with a traversal. Generally, the algorithm does only the differentiations needed to get the traversal, but since it is a greedy algorithm, it is not always the minimal number.
It is beyond the scope of this documentation to describe the algorithm in detail. The implementation built into the Wolfram Language follows the algorithm outlined in [P88] fairly closely. It uses Graph to efficiently implement the graph computations and symbolically differentiates the equations with D when differentiation is called for.
When there is a traversal of the system, it is then possible to find an ordering for the variables and equations such that the incidence matrix is in block lower triangular (BLT) form. The BLT form is used in setting up the dummy derivative method for maintaining constraints and also in the "StateSpace" time integration method. A description of the BLT ordering is included in "State Space Method for DAEs".
To begin index reduction on the constrained pendulum system (2), consider the variables ![]() . Generally, start with the highest-order derivative that appears in the equations. As a reminder, the pendulum equations are
. Generally, start with the highest-order derivative that appears in the equations. As a reminder, the pendulum equations are
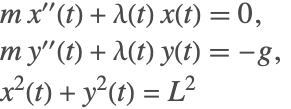
and the graph incidence matrix with respect to the highest-order derivative is

The incidence matrix is constructed by checking the presence of a variable in an equation. If the variable exists in the equation, a weight of 1 is given; if not then 0 is specified. So checking for the variables ![]() in the first equation gives
in the first equation gives ![]() (as seen in the first row of the incidence matrix).
(as seen in the first row of the incidence matrix).
From the first incidence matrix, it is found that there is no traversal. The last equation is differentiated twice
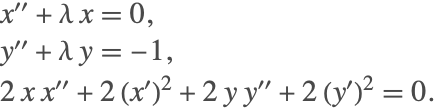

This can be reordered so that there is no zero on the diagonal by swapping the first and last equations, resulting in the incidence matrix

The resulting system has index 1 since ![]() still appears as an algebraic variable and does not contain a derivative in the differentiated system. Differentiating the system one more time will provide a differential system for
still appears as an algebraic variable and does not contain a derivative in the differentiated system. Differentiating the system one more time will provide a differential system for ![]() . Therefore, the index of the original system is indeed 3.
. Therefore, the index of the original system is indeed 3.
As a first approach, the system with the twice-differentiated equation can be solved directly.
d2sol = NDSolve[{x''[t] + λ[t] x[t] == 0, y''[t] + λ[t] y[t] == -1, D[x[t] ^ 2 + y[t] ^ 2 == 1, {t, 2}], cpinit}, {x, y, λ}, {t, 0, 100}, MaxSteps -> ∞]Row[Table[Plot[Evaluate[D[x[t] ^ 2 + y[t] ^ 2 - 1, {t, i}] /. d2sol], {t, 0, 100}, ImageSize -> Small], {i, 0, 1}]]The original pendulum length constraint is not being satisfied well; in fact, it stretches! The constraints are not satisfied well because the new system does not identically represent the original system. This can be seen by the fact that the new system does not contain the original constraint of ![]() , but rather its differentiated equations.
, but rather its differentiated equations.
To model the original dynamics of the system with the new system, additional equations must be satisfied. However, including additional equations leads to more equations than unknowns. To address this issue, the method of dummy derivatives is used, so that the index-reduced system becomes balanced.
The Pantelides algorithm is efficient because it can use graph algorithms with well-controlled complexity even for very large problems. However, since it is based solely on incidence, there can be issues with systems that lead to Jacobians that are singular. The structural matrix method may be able to resolve such cases, but may have larger computational complexity for large systems.
Structural Matrix Method
The structural matrix algorithm is an alternative to the Pantelides algorithm. The structural matrix method follows from the work of Unger [UKM95] and Chowdhary et al. [CKL04]. The graph-based algorithms such as the Pantelides algorithm rely on traversals to perform index reduction. However, they do not account for the fact that sometimes there may be variable cancellations in a particular system. This leads to the algorithm underestimating the index of the system. If a DAE has not been correctly reduced to an index-0 or index-1 system, then the numerical integration may fail or may produce an incorrect result.
As an example of variable cancellation that is not taken into account by Pantelides's method, consider the following DAE
To perform index reduction, as a first step the second equation is differentiated once, giving
The Pantelides algorithm stops after the first differentiation because it finds derivatives for the variables ![]() and finds a traversal. Since all the derivatives are found from the first differentiation, the Pantelides algorithm estimates the index of the system to be 0. An index-0 system is equivalent to a system of ODEs. The Jacobian of the derivatives for the differentiated system is found to be
and finds a traversal. Since all the derivatives are found from the first differentiation, the Pantelides algorithm estimates the index of the system to be 0. An index-0 system is equivalent to a system of ODEs. The Jacobian of the derivatives for the differentiated system is found to be
and is clearly singular. By simple substitutions, it is possible to see that the differentiated system is equivalent to
This implies that in order to get a system of ODEs, a second differentiation must be done for the second equation. This results in the final system
The above system has a nonsingular Jacobian for the derivatives. The above system is now correctly index 0 and a system of ODEs can be formed from it. Since two differentiations were required, the actual index of the system is 2 (instead of 1).
Unlike the Pantelides algorithm, the structural matrix method accounts for all cancellations associated with the linear terms. The steps of the method are demonstrated using the pendulum example (2) described as a first-order system

As a first step, two matrices ![]() and
and ![]() are constructed. The matrices are incidence matrices associated with the derivatives
are constructed. The matrices are incidence matrices associated with the derivatives ![]() and the variables
and the variables ![]() , respectively. For the above system, the matrix
, respectively. For the above system, the matrix ![]() is given as
is given as

The matrix above contains a ![]() as some of its entries. The
as some of its entries. The ![]() is used as a placeholder, indicating that the variables in that equation (row) are present in the equation in a nonlinear fashion. Notice that for the second equation, the terms
is used as a placeholder, indicating that the variables in that equation (row) are present in the equation in a nonlinear fashion. Notice that for the second equation, the terms ![]() and
and ![]() appear as products. Therefore, the first and last columns in the second row are marked with a
appear as products. Therefore, the first and last columns in the second row are marked with a ![]() .
.
Once the matrices are constructed, the objective is to try and convert the system of DAEs into a system of ODEs. In order to do that, the rank of the matrix ![]() must be full. To achieve this, equations that need to be differentiated are first identified. In this case, it is the last equation. After differentiation, the structural matrices are
must be full. To achieve this, equations that need to be differentiated are first identified. In this case, it is the last equation. After differentiation, the structural matrices are

The last column of the matrix ![]() has changed due to the differentiations. To see this more clearly, consider the last equation in (3). Differentiating the equation gives
has changed due to the differentiations. To see this more clearly, consider the last equation in (3). Differentiating the equation gives ![]() . Notice now that the terms
. Notice now that the terms ![]() are present in the equation and appear in a nonlinear manner. Therefore the incidence row associated with the derivatives is
are present in the equation and appear in a nonlinear manner. Therefore the incidence row associated with the derivatives is ![]() , and the incidence row associated with the variables is
, and the incidence row associated with the variables is ![]() .
.
The next step involves matrix factorization in the form of Gaussian elimination for the matrix ![]() . The elements in the last row of
. The elements in the last row of ![]() can be eliminated by making use of rows 1 and 3. This elimination also affects the rows of the matrix
can be eliminated by making use of rows 1 and 3. This elimination also affects the rows of the matrix ![]() . Multiplying the first row of
. Multiplying the first row of ![]() with
with ![]() and subtracting it from the last row leads to
and subtracting it from the last row leads to

Multiplying the third row with ![]() and subtracting it from the last row gives
and subtracting it from the last row gives

The matrix ![]() is still rank deficient and therefore the above steps must be repeated. A second iteration leads to the system
is still rank deficient and therefore the above steps must be repeated. A second iteration leads to the system

A third iteration leads to the system

The matrix ![]() is now a full-rank matrix. Therefore the iterations are stopped. Since three iterations were needed to get a full-rank matrix for
is now a full-rank matrix. Therefore the iterations are stopped. Since three iterations were needed to get a full-rank matrix for ![]() , the index of the system is 3. Note that unlike the Pantelides method, the structural matrix algorithm explicitly operates on the incidence matrices.
, the index of the system is 3. Note that unlike the Pantelides method, the structural matrix algorithm explicitly operates on the incidence matrices.
The next examples demonstrate the advantage and differences of the structured matrix method over the Pantelides algorithm. Consider the linear system
eqns = {x'[t] + y'[t]== y[t] -Sin[t] + 2 Cos[t], x[t]+y[t]==-Sin[t]};
ic = {y[0]==-3};NDSolve[{eqns, ic}, {x, y}, {t, 0, 1}, Method -> {"IndexReduction" -> "Pantelides", "EquationSimplification" -> "Residual"}]This fails because there is a singular Jacobian matrix. Very commonly the messages NDSolve::nderr or NDSolve::ndcf are issued by the solver when the DAE's index is greater than 1.
sol = NDSolve[{eqns, ic}, {x, y}, {t, 0, 2 Pi}, Method -> {"IndexReduction" -> "StructuralMatrix"}]The exact solutions are ![]() and
and ![]() . Comparing the exact and numerical results, it is found that the computed solution is quite accurate.
. Comparing the exact and numerical results, it is found that the computed solution is quite accurate.
GraphicsRow[Plot[Evaluate[# /. sol], {t, 0, 2 Pi}]& /@ {Norm[x[t] - (3 Cos[t] - 2 Sin[t])], Norm[y[t] - (Sin[t] - 3 Cos[t])]}, ImageSize -> 500]Next, consider the effect of under- or overestimating the index of a system. Consider the linear system
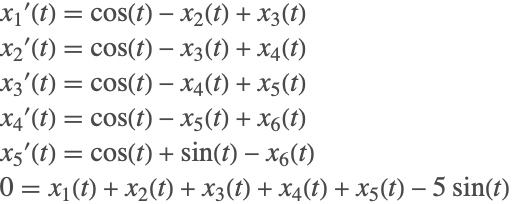
Clear[x1,x2,x3,x4,x5,x6,ics,vars];
eqns = (| |
| ------------------------------------------------------ |
| x1'[t] == Cos[t] - x2[t] + x3[t] |
| x2'[t] == Cos[t] - x3[t] + x4[t] |
| x3'[t] == Cos[t] - x4[t] + x5[t] |
| x4'[t] == Cos[t] - x5[t] + x6[t] |
| x5'[t] == Cos[t] + Sin[t] - x6[t] |
| 0 == x1[t] + x2[t] + x3[t] + x4[t] + x5[t] - 5 * Sin[t] |);
ics = {x1[0]==x2[0]==x3[0]==x4[0]==x5[0]==x6[0]==0};
vars = {x1,x2,x3,x4,x5,x6};The exact solution for all the variables is ![]() . This is an index-4 system. The Pantelides algorithm estimates the index to be 2.
. This is an index-4 system. The Pantelides algorithm estimates the index to be 2.
NDSolve[{eqns, ics}, vars, {t, 0, 4 Pi}, Method -> {"IndexReduction" -> "Pantelides"}] ;The solver encounters a convergence failure because the Jacobian is singular.
solS1 = NDSolve[{eqns, ics}, vars, {t, 0, 4 Pi}, Method -> {"IndexReduction" -> "StructuralMatrix"}]There are certain tests that NDSolve performs to determine which index reduction method to use. For this case, using the option Automatic, NDSolve picks the structural matrix algorithm.
solS2 = NDSolve[{eqns, ics}, vars, {t, 0, 4 Pi}, Method -> {"IndexReduction" -> Automatic}]If the system is forced to be treated as index 0, integration can be performed. However, in the absence of incorrect estimation of the index, the results can be wildly off because the solution is being computed for a completely different manifold.
solP0 = NDSolve[{eqns, ics}, vars, {t, 0, 4 Pi}, Method -> {"IndexReduction" -> {"Pantelides", "IndexGoal" -> 0}, "EquationSimplification" -> "Residual"}]Since the exact solution is known for this problem, it is desirable to see the difference between the numerical solution and the exact result.
Row[Plot[Evaluate[(#[t] - Sin[t]) /. solP0], {t, 0, 4 Pi}, PlotLabel -> #, PlotRange -> All, ImageSize -> Small]& /@ vars]Due to the underestimation of the index of the system, the necessary differentiations are not carried out, leading to the solution's being approximated on an incorrect manifold. The structural matrix method, on the other hand, is able to correctly identify the index of the system.
Row[Plot[Evaluate[(#[t] - Sin[t]) /. solS1], {t, 0, 4 Pi}, PlotLabel -> #, PlotRange -> All, ImageSize -> Small]& /@ vars]solSM0 = NDSolve[{eqns, ics}, vars, {t, 0, 4 Pi}, Method -> {"IndexReduction" -> {"StructuralMatrix", "IndexGoal" -> 0}}];Row[Plot[Evaluate[(#[t] - Sin[t]) /. solSM0], {t, 0, 4 Pi}, PlotLabel -> #, PlotRange -> All, ImageSize -> Small]& /@ vars]The structural matrix method does handle such systems much better. It is, however, important to note that there is a price to be paid for the rigor of accounting for cancellations. The structural matrix method relies on generating, maintaining, and operating on matrices, which has a significant computational overhead compared to the Pantelides algorithm. The algorithm is therefore only suited for small-to-medium-scale problems.
Constraint Methods
Dummy Derivatives
The purpose of the dummy derivative method is to introduce algebraic variables so that the combined system of original equations and equations that have been differentiated for index reduction is not overdetermined.
Consider the pendulum system (2) again.
ddsol = First[NDSolve[{cpdae, cpinit}, {x, y, λ}, {t, 0, 100}, MaxSteps -> ∞, Method -> {"IndexReduction" -> {Automatic, "ConstraintMethod" -> "DummyDerivatives"}}]]Note that for this example the "ConstraintMethod"->"DummyDerivatives" was included for emphasis and is not needed, since trying to use dummy derivatives is the default.
GraphicsRow[Table[Plot[Evaluate[D[x[t] ^ 2 + y[t] ^ 2 - 1, {t, i}] /. ddsol], {t, 0, 100}, PlotRange -> All], {i, 0, 1}], ImageSize -> 500]Now the constraints are very well satisfied.
The main idea behind the dummy derivative method of Mattson and Söderlind [MS93] is to introduce new variables that represent derivatives, thus making it possible to reintroduce constraint equations without getting an overdetermined system.
Recall the index-reduced equations for the system (2) were
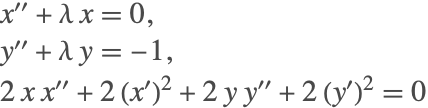
with the two constraints from the third equation and its first derivative
Let ![]() and
and ![]() be algebraic variables that replace
be algebraic variables that replace ![]() and
and ![]() , respectively. Then, with the constraints included, the entire system in these variables is given by
, respectively. Then, with the constraints included, the entire system in these variables is given by
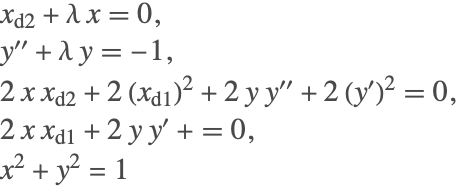
and the incidence matrix with variables ![]() is
is

that can be reordered to have a nonzero diagonal.
incidenceMatrix = {{1, 0, 1, 0, 1}, {0, 0, 0, 1, 1}, {1, 1, 1, 1, 0}, {1, 1, 0, 0, 0}, {1, 0, 0, 0, 0}};
{row, col} = Flatten /@ SparseArray`BlockTriangularOrdering[incidenceMatrix];
incidenceMatrix[[row]][[col]] // MatrixFormIn general, the algorithm can be applied to any index-reduced DAE; however, while integrating the system, the solver may encounter singularities.
ddxsol = First[NDSolve[{xd2[t] + x[t] λ[t] == 0, y''[t] + y[t] λ[t] == -1, 2 xd1[t]^2 + 2 xd2[t] x[t] + 2 Derivative[1][y][t]^2 + 2 y[t] Derivative[2][y][t] == 0, 2 xd1[t] x[t] + 2 y[t] Derivative[1][y][t] == 0, x[t]^2 + y[t]^2 == 1, cpinit /. {x' -> xd1, x'' -> xd2}} , {x, xd1, xd2, y, λ}, {t, 0, 100}, MaxSteps -> Infinity]]The above system cannot complete integration because the system becomes singular when ![]() .
.
Plot[Evaluate[{x[t], y[t]} /. ddxsol], {t, 0, 1.85}]From the plot it can be seen that NDSolve is getting stuck when ![]() is becoming 0. When
is becoming 0. When ![]() is 0, several terms drop out, the incidence matrix becomes singular, and a nonzero diagonal can no longer be found, so the dummy derivative system effectively has index
is 0, several terms drop out, the incidence matrix becomes singular, and a nonzero diagonal can no longer be found, so the dummy derivative system effectively has index ![]() along solutions that go through
along solutions that go through ![]() .
.
Consider an alternative dummy derivative replacement, i.e. ![]() and
and ![]() to replace
to replace ![]() and
and ![]() . Unfortunately, the system with this replacement becomes singular at
. Unfortunately, the system with this replacement becomes singular at ![]() .
.
The remedy is to use dynamic state selection such that ![]() and
and ![]() replace
replace ![]() and
and ![]() when
when ![]() is away from 0 and switch dynamically to the system using
is away from 0 and switch dynamically to the system using ![]() and
and ![]() to replace
to replace ![]() and
and ![]() when
when ![]() becomes too small. NDSolve automatically uses WhenEvent with state replacement rules to handle dynamic state selection with dummy derivatives if necessary. The exact details of the dynamic state selection are beyond the scope of this tutorial. A detailed explanation can be found in Mattson and Söderlind [MS93].
becomes too small. NDSolve automatically uses WhenEvent with state replacement rules to handle dynamic state selection with dummy derivatives if necessary. The exact details of the dynamic state selection are beyond the scope of this tutorial. A detailed explanation can be found in Mattson and Söderlind [MS93].
Projection
The alternative to using dummy derivatives is to reduce the index to 0 so there is a system of ODEs and use projection to ensure that the original constraints are satisfied.
For the pendulum system (2), the index of the system is 3. This means that in order to get an ordinary differential equation for all the variables, the first and second equations must be differentiated once, while the third equation must be differentiated three times. This results in
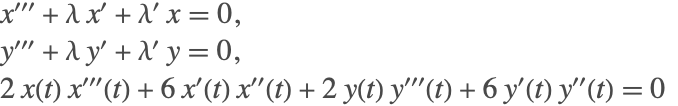
that can be solved for the derivatives ![]() ,
, ![]() , and
, and ![]() . (NDSolve will also reduce the system to first order automatically.)
. (NDSolve will also reduce the system to first order automatically.)
In order to correctly represent the dynamics of the system, the first ![]() differentiated equation must also be taken into account. These equations are
differentiated equation must also be taken into account. These equations are
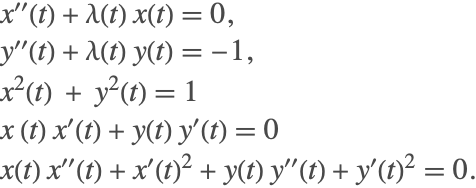
The above equations are treated as invariant equations that must be satisfied at each time step. Since the ODE system was derived from differentiating these equations, the constraints are guaranteed to be consistent with the ODEs, so the system can be solved using the "Projection" time integration method with the constraints as invariants.
NDSolve[{λ[t] Derivative[1][x][t] + x[t] Derivative[1][λ][t] + Derivative[3][x][t] == 0, λ[t] Derivative[1][y][t] + y[t] Derivative[1][λ][t] + Derivative[3][y][t] == 0, 6 Derivative[1][x][t] Derivative[2][x][t] + 6 Derivative[1][y][t] Derivative[2][y][t] + 2 x[t] Derivative[3][x][t] + 2 y[t] Derivative[3][y][t] == 0, cpinit}, {x, y, λ}, {t, 0, 100}, Method -> {"TimeIntegration" -> {"Projection", "Invariants" -> Apply[Subtract, Flatten[{x''[t] + λ[t] x[t] == 0, y''[t] + λ[t] y[t] == -1, Table[D[x[t] ^ 2 + y[t] ^ 2 == 1, {t, i}], {i, 0, 2}]}], {1}]}}]This can be done automatically using the built-in index reduction method in NDSolve directly.
psol = First[NDSolve[{cpdae, cpinit}, {x, y, λ}, {t, 0, 100}, MaxSteps -> ∞, Method -> {"IndexReduction" -> {True, "ConstraintMethod" -> "Projection"}}]];With this method, the original constraints are typically satisfied up to the local tolerances for NDSolve specified by the PrecisionGoal and AccuracyGoal options.
The system has additional invariants that should also be satisfied. One of these is the conservation of energy that can be expressed by ![]() . Because the projection method only projects at the ends of the time steps, this is the most appropriate place to do the comparison.
. Because the projection method only projects at the ends of the time steps, this is the most appropriate place to do the comparison.
ddsol = First[NDSolve[{cpdae, cpinit}, {x, y, λ}, {t, 0, 100}, MaxSteps -> ∞, Method -> {"IndexReduction" -> {True, "ConstraintMethod" -> "DummyDerivatives"}}]];energy[sol_] := Module[{times = Part[x /. sol, 3, 1], es},
es[t_] = 1 + y[t] + (1/2) (-y[t] Derivative[1][x][t] + x[t] Derivative[1][y][t])^2 /. sol;Transpose[{times, es[times] - es[0]}]];ListPlot[{energy[ddsol], energy[psol]}]Index Reduction of Partial Differential Algebraic Equations (PDAE):
Consider the following system of partial differential equations:
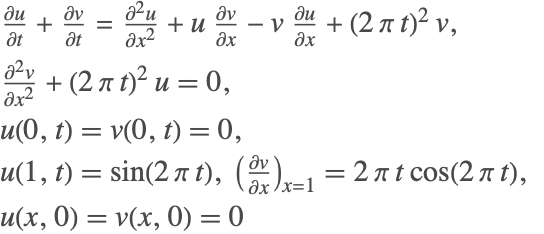
In the above system, the second PDE does not contain a time derivative component for any of the variables. Therefore, NDSolve cannot solve this system using method of lines because the resulting mass-matrix will be singular and the system has an index of 1. To reduce the index of the system, the above system is represented in a matrix-vector form as
The terms ![]() represent the matrices obtained by discretizing the spatial derivatives and the terms
represent the matrices obtained by discretizing the spatial derivatives and the terms ![]() represent the vectors obtained by discretizing the variables
represent the vectors obtained by discretizing the variables ![]() at discrete spatial intervals
at discrete spatial intervals ![]() . Index reduction is performed on the new system using the index-reduction methods described above. The resulting index-reduced system is
. Index reduction is performed on the new system using the index-reduction methods described above. The resulting index-reduced system is
The spatial derivatives are now reintroduced back into the system to give
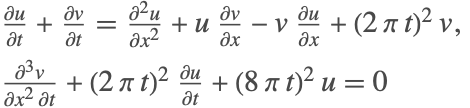
The resulting system can then be solved using traditional methods available in NDSolve.
eqns = {D[u[x, t], t] - D[v[x, t], t] == D[u[x, t], x, x] + u[x, t] D[v[x, t], x] - v[x, t] D[u[x, t], x] + (2 Pi t) ^ 2 v[x, t], D[v[x, t], x, x] + (2 Pi t) ^ 2 u[x, t] == 0};
bcs = {u[0, t] == v[0, t] == 0, u[1, t] == Sin[2 Pi t], Derivative[1, 0][v][1, t] == 2 Pi t Cos[2 Pi t]};
ics = {u[x, 0] == v[x, 0] == 0};sol = NDSolveValue[{eqns, bcs, ics}, {u, v}, {x, 0, 1}, {t, 0, 3}, Method -> {"IndexReduction" -> Automatic, "EquationSimplification" -> "Residual", "PDEDiscretization" -> {"MethodOfLines", "SpatialDiscretization" -> {"TensorProductGrid", "MinPoints" -> 200, "MaxPoints" -> 200}}}]Note that 200 points were used for the spatial discretization because the default spatial grid spacing based on the constant initial condition is insufficient to handle the variation the solution develops over time.
Plot3D[Evaluate[#[x, t]], {x, 0, 1}, {t, 0, 3}]& /@ solIt is important to note that the index reduction is performed in the time derivative, so no new boundary conditions are needed or added to the system. However, if the PDAE is found to be of high index, then additional initial conditions may be needed.
Consistent Initialization of DAEs
A system of differential algebraic equations (DAEs) can be represented in the most general form as
which may include differential equations and algebraic constraints. In order to obtain a solution for ![]() , a set of consistent initial conditions for
, a set of consistent initial conditions for ![]() and
and ![]() is needed to start the integration. A necessary condition for consistency is that the initial conditions satisfy
is needed to start the integration. A necessary condition for consistency is that the initial conditions satisfy ![]() However, this condition alone may not be sufficient, since differentiating the original equations produces new equations that also need to be satisfied by the initial conditions. The task therefore is to try and find initial conditions that satisfy all necessary consistency conditions. The problem of finding consistent initial conditions can be one of the most difficult parts of solving a DAE system.
However, this condition alone may not be sufficient, since differentiating the original equations produces new equations that also need to be satisfied by the initial conditions. The task therefore is to try and find initial conditions that satisfy all necessary consistency conditions. The problem of finding consistent initial conditions can be one of the most difficult parts of solving a DAE system.
Consider the following linear DAE problem:
The DAE has derivatives for ![]() . This would suggest that in order to uniquely solve this problem, initial conditions for
. This would suggest that in order to uniquely solve this problem, initial conditions for ![]() need to be specified. However, you cannot specify any arbitrary initial conditions to the variables, since there is a unique set of consistent initial conditions. Differentiating the algebraic equation once leads to
need to be specified. However, you cannot specify any arbitrary initial conditions to the variables, since there is a unique set of consistent initial conditions. Differentiating the algebraic equation once leads to ![]() Substituting in the second equation gives the solution for
Substituting in the second equation gives the solution for ![]() . Differentiating
. Differentiating ![]() and substituting into the first equation gives the solution for
and substituting into the first equation gives the solution for ![]() This shows that the solution for the DAE system is fixed, and therefore the initial conditions are also fixed, and the only consistent set of initial conditions for
This shows that the solution for the DAE system is fixed, and therefore the initial conditions are also fixed, and the only consistent set of initial conditions for ![]() is
is ![]() It is important to note that the constraints on the initial conditions are not obvious, in general making the problem of finding consistent initial conditions quite challenging.
It is important to note that the constraints on the initial conditions are not obvious, in general making the problem of finding consistent initial conditions quite challenging.
In some cases, you may just want to get a consistent initialization for a DAE problem and not compute the solution further. This can be done with NDSolve by specifying the endpoint of the time integration to be the same as the time where the initial condition is specified. Such a step is generally helpful when you need to examine just the starting conditions without having to perform the complete integration.
init = NDSolve[{Derivative[1][Subscript[x, 1]][t] == Subscript[x, 3][t], Subscript[x, 2][t] (1 - Subscript[x, 2][t]) == 0, Subscript[x, 1][t] Subscript[x, 2][t] + Subscript[x, 3][t] (1 - Subscript[x, 2][t]) == t, Subscript[x, 2][2] == 1}, {Subscript[x, 1], Subscript[x, 2], Subscript[x, 3]}, {t, 2}]First[{Subscript[x, 1][t], Subscript[x, 2][t], Subscript[x, 3][t]} /. init /. t -> 2]NDSolve provides several methods for DAE initialization. The method m can be specified using Method->{"DAEInitialization"->m}.
| Automatic | determine the method to use automatically |
| "Collocation" | use a collocation method; this algorithm can be used for initialization of high-index systems |
| "QR" | use a QR decomposition-based algorithm for index-1 systems |
| "BLT" | use a Block Lower Triangular ordering (BLT) approach for index-1 systems |
Methods for DAE initialization.
The collocation method is designed to handle the DAE system as a residual black box and tries to achieve the objective of satisfying the residual over a small interval near the point of initialization. This feature allows the method to be used to handle initialization of high-index systems. However, since the algorithm does not analyze the DAE system, the structure of the system cannot be exploited for computational efficiency. This makes the algorithm slower than the other methods.
The QR and BLT methods are designed specifically to be used for index-1 and index-0 systems. The QR method relies on decomposing the Jacobian of the derivative to generate two decoupled subsystems such that the initial conditions for the variables and their derivatives are computed iteratively. This makes the method quite efficient and robust.
The BLT method relies on examining the structure of the DAE system and splits the original system into a number of smaller subsystems such that each of these subsystems can be solved efficiently. This method results in dealing with much smaller Jacobian matrices (compared to the entire system) and thus is computationally efficient for large systems.
The following sections give details about how NDSolve obtains consistent initial conditions for DAEs using different algorithms.
Collocation Method
The basic collocation algorithm makes use of expanding the dependent variables ![]() in terms of basis functions
in terms of basis functions ![]() as
as
In order to obtain ![]() and
and ![]() , one tries to enforce the condition that
, one tries to enforce the condition that ![]() is satisfied at
is satisfied at ![]() collocation points,
collocation points, ![]() , in time. To achieve this, the implicit DAE is linearized as
, in time. To achieve this, the implicit DAE is linearized as
where ![]() and
and ![]() denote the Jacobian of
denote the Jacobian of ![]() with respect to
with respect to ![]() and
and ![]() , respectively:
, respectively:
Applying this linearization to ![]() collocation points in time, a system of linear equations is obtained for the coefficients
collocation points in time, a system of linear equations is obtained for the coefficients ![]() , which is solved iteratively using Newton's method.
, which is solved iteratively using Newton's method.
where ![]() is obtained using a line search method. If there are
is obtained using a line search method. If there are ![]() coefficients and
coefficients and ![]() collocation points, then you are dealing with an
collocation points, then you are dealing with an ![]() ×
×![]() system of linear equations in (5).
system of linear equations in (5).
For high-index systems that have not been index reduced, NDSolve automatically tries to initialize the system using the collocation algorithm. Consider the pendulum system (2)
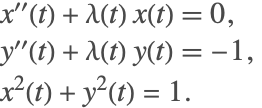
In order to start integration of the system, the initial conditions for ![]() must be known. For such systems,
must be known. For such systems, ![]() would represent some physical property and could be assigned reasonable values. However, the value of
would represent some physical property and could be assigned reasonable values. However, the value of ![]() might not be easy to find. NDSolve can be used here to determine the appropriate values.
might not be easy to find. NDSolve can be used here to determine the appropriate values.
sol = First@NDSolve[{x''[t] + λ[t] x[t] == 0, y''[t] + λ[t] y[t] == -1, x[t] ^ 2 + y[t] ^ 2 == 1, x[0] == 1, y'[0] == 1}, {x, y, λ}, {t, 0, 0}]{x[0], y[0], λ[0]} /. sol{x'[0], y'[0], λ'[0]} /. solNotice that only partial initial conditions were given and the algorithm correctly computes all the required initial conditions.
The default settings for the collocation method have been chosen to handle initialization for a wide variety of systems; however, in some cases it is necessary to change the settings to find a consistent Initialization. The following options may be used to tune the algorithm.
collocation method option name | default value | |
| "CollocationDirection" | Automatic | chooses the direction in which the collocation points are placed; possible options include "Forward", "Backward", "Centered", "Automatic" |
| "CollocationPoints" | Automatic | number of collocation points to be used; using suboption "ExtraCollocationPoints", more grid points are added while keeping the approximation order fixed |
| "CollocationRange" | Automatic | range over which the collocation points are distributed |
| "DefaultStartingValue" | Automatic | starting value used for unspecified components in the nonlinear iterations; option can be a one-element value ig/{ig} or a list of two numbers {ig1,ig2}, where ig1,ig2 are the starting values for the variable and its derivative, respectively |
| "MaxIterations" | 100 | maximum number of iterations to be performed |
The next sections discuss these options in more detail and show in what circumstances they may help to find consistent initial conditions.
Collocation Direction
In order to perform the initialization, a set of collocation points is selected. The points can be placed on both sides, front, or back of the point of interest, using the options "Centered", "Forward", or "Backward", respectively. The following table describes the effect of choosing one of these options.
| "Forward" | collocation performed over the range |
| "Backward" | collocation performed over the range |
| "Centered" | collocation performed over the range |
"CollocationDirection" suboptions.
The term ![]() above refers to the time at which the initial condition is computed. The term
above refers to the time at which the initial condition is computed. The term ![]() is the offset value. By default, NDSolve automatically chooses the direction in which the collocation is performed.
is the offset value. By default, NDSolve automatically chooses the direction in which the collocation is performed.
The collocation direction becomes important when dealing with discontinuities.
DAE2 = (| |
| --------------------- |
| x'[t] == Abs[u[t]] |
| u'[t] == y[t] + Sin[t] |
| u[t] == t |);In this case, at time ![]() ,
, ![]() is discontinuous.
is discontinuous.
NDSolve automatically sets the option for "CollocationDirection".
sol2 = First@NDSolve[{DAE2, x[0] == 1}, {x, y, u}, {t, 0, 10}, Method -> {"DAEInitialization" -> {"Collocation", "CollocationDirection" -> Automatic}}]GraphicsRow[Plot[Evaluate[#[t] /. sol2], {t, 0, 10}, PlotLabel -> #]& /@ {x, y, u}, ImageSize -> 500]Applying a "CollocationDirection" of "Centered" will cause the solution to diverge.
NDSolve[{DAE2, x[0] == 1}, {x, y, u}, {t, 0, 1}, Method -> {"DAEInitialization" -> {"Collocation", "CollocationDirection" -> "Centered"}}]However, using the "Forward" or "Backward" direction, you can get correct convergence by avoiding the discontinuous derivative.
sol2 = First@NDSolve[{DAE2, x[0] == 1}, {x, y, u}, {t, 0, 10}, Method -> {"DAEInitialization" -> {"Collocation", "CollocationDirection" -> "Forward"}}]In most cases, NDSolve automatically determines what the direction should be. However, if it is known that there could be discontinuities in a specific direction, then it can be avoided by using this setting. This in turn helps in reducing the computational time for NDSolve.
Collocation Points
The option "CollocationPoints" refers to the number of collocation points ![]() as indicated in (5) that will be used in the series approximation (4). Depending on the collocation points, the order
as indicated in (5) that will be used in the series approximation (4). Depending on the collocation points, the order ![]() of the series in (4) is determined. The order of the series is
of the series in (4) is determined. The order of the series is ![]() . The collocation points are essentially the Chebyshev points distributed over the collocation range.
. The collocation points are essentially the Chebyshev points distributed over the collocation range.
To illustrate the effect of "CollocationPoints", consider the following index-3 example.
Clear[x1, x2, x3, vars, DAE3];
DAE3 = (| |
| ----------------------- |
| x2'[t] + x1[t] == Sin[t] |
| x3'[t] + x2[t] == Sin[t] |
| x3[t] == Cos[t] |);
vars = {x1, x2, x3};The solution to the preceding DAE can be found analytically. The exact consistent initial conditions are as follows.
TableForm[{{-2, 1}, {0, 2}, {1, 0}}, TableHeadings -> {Through[vars[0]], {"Value", "Derivative"}}, TableAlignments -> "Center"]sol3 = First@NDSolve[DAE3, vars, {t, 0, 0}, Method -> {"DAEInitialization" -> "Collocation" }];TableForm[Transpose[{Through[vars[0]], D[Through[vars[t]], t] /. t -> 0}] /. sol3, TableHeadings -> {Through[vars[0]], {"Value", "Derivative"}}, TableAlignments -> "Center"]A manual setting of collocation points is possible. Setting "CollocationPoints"->2 is equivalent to setting ![]() in (4). This means that the solution is approximated using constant and linear basis functions.
in (4). This means that the solution is approximated using constant and linear basis functions.
sol3 = First@NDSolve[DAE3, vars, {t, 0, 0}, Method -> {"DAEInitialization" -> {"Collocation" , "CollocationPoints" -> 2}}];TableForm[Transpose[{Through[vars[0]], D[Through[vars[t]], t] /. t -> 0}] /. sol3, TableHeadings -> {Through[vars[0]], {"Value", "Derivative"}}, TableAlignments -> "Center"]Even though the iterations converged, the results are not the correct consistent initial conditions. No message is issued because they satisfy the specified equations sufficiently well.
Apply[Subtract, Flatten[DAE3], {1}] /. sol3 /. t -> 0Recall that for higher-index equations, consistent initial conditions should also work with the differentiated system.
Increasing the number of collocation points and thus allowing higher-order basis functions allows the algorithm to converge to the expected result.
initialConditions = Table[
sol3 = First@NDSolve[DAE3, vars, {t, 0, 0}, Method -> {"DAEInitialization" -> {"Collocation" , "CollocationPoints" -> m}}];
{Through[vars[0]], D[Through[vars[t]], t] /. t -> 0} /. sol3, {m, 2, 10}
];valuePlot = ListLinePlot[Transpose[initialConditions[[All, 1]]], PlotMarkers -> Automatic, PlotStyle -> {StandardRed, StandardGreen, StandardBlue}, Frame -> True, FrameLabel -> {Style["Collocation Points (m)", 18], Style["Values", 18]}, DataRange -> {2, 10}];
derivativePlot = ListLinePlot[Transpose[initialConditions[[All, 2]]], PlotMarkers -> Automatic, PlotStyle -> {StandardRed, StandardGreen, StandardBlue}, Frame -> True, FrameLabel -> {Style["Collocation Points (m)", 18], Style["Derivatives", 18]}, DataRange -> {2, 10}];
GraphicsRow[{valuePlot, derivativePlot}, ImageSize -> 500]Since the order of the approximation ![]() is determined by the collocation points
is determined by the collocation points ![]() , the resulting linearized system obtained in (4) will result in a square matrix, and the resulting system of linear equations can be solved efficiently using LinearSolve. However, it is quite possible that the resulting linear system may be ill conditioned or singular. Such systems are known to be sensitive and therefore can result in an unstable iteration. To resolve this issue, it is often desirable to solve an overdetermined system of equation using LeastSquares.
, the resulting linearized system obtained in (4) will result in a square matrix, and the resulting system of linear equations can be solved efficiently using LinearSolve. However, it is quite possible that the resulting linear system may be ill conditioned or singular. Such systems are known to be sensitive and therefore can result in an unstable iteration. To resolve this issue, it is often desirable to solve an overdetermined system of equation using LeastSquares.
Using the suboption "ExtraCollocationPoints", the order of the series approximation is kept equal to ![]() in (4), but the value of
in (4), but the value of ![]() in (5) is modified to
in (5) is modified to ![]() , where
, where ![]() is the extra collocation points. This, therefore, leads to an overdetermined system of equations in (5), which is solved using the least-squares method.
is the extra collocation points. This, therefore, leads to an overdetermined system of equations in (5), which is solved using the least-squares method.
First@NDSolve[DAE3, vars, {t, 0, 0}, Method -> {"DAEInitialization" -> {"Collocation", "CollocationPoints" -> {Automatic, "ExtraCollocationPoints" -> 3}}}];
TableForm[Transpose[{Through[vars[0]], D[Through[vars[t]], t] /. t -> 0}] /. sol3, TableHeadings -> {Through[vars[0]], {"Value", "Derivative"}}, TableAlignments -> "Center"]Collocation Range
For very high-index systems that have not undergone index reduction, the use of a much higher collocation order might be required, along with a specification of the range in which the collocation should take place. By default, the collocation range is computed based on the working precision and the number of basis functions used in expansion.
For an example, an index-6 system for which an exact solution can be found will be used.
Clear[x1, x2, x3, x4, x5, x6];
DAE4 = (| |
| ----------------------- |
| x6'[t] + x5[t] == Sin[t] |
| x5'[t] + x4[t] == Sin[t] |
| x4'[t] + x3[t] == Sin[t] |
| x3'[t] + x2[t] == Sin[t] |
| x2'[t] + x1[t] == Sin[t] |
| x6[t] == Cos[t] |);
vars = {x1, x2, x3, x4, x5, x6};exactSol = First@DSolve[DAE4, Through[vars[t]], t]TableForm[Transpose[{exactSol, D[exactSol, t]}] /. t -> 0]sol3 = First@NDSolve[DAE4, vars, {t, 0, 0}, Method -> {"DAEInitialization" -> {"Collocation"}}];
TableForm[Transpose[{Through[vars[0]], D[Through[vars[t]], t] /. t -> 0}] /. sol3, TableHeadings -> {Through[vars[0]], {"Value", "Derivative"}}, TableAlignments -> "Center"]Typically it is necessary to use an approximation with an order higher than the index of the system. Since this is an index-6 system, you must rely on a higher-order approximation in (4). As mentioned in the previous subsection, this can be done using the option "CollocationPoints".
sol3 = First@NDSolve[DAE4, vars, {t, 0, 0}, Method -> {"DAEInitialization" -> {"Collocation", "CollocationPoints" -> 15}}];
TableForm[Transpose[{Through[vars[0]], D[Through[vars[t]], t] /. t -> 0}] /. sol3, TableHeadings -> {Through[vars[0]], {"Value", "Derivative"}}, TableAlignments -> "Center"]A solution is found, but there are significant errors from the exact consistent initial conditions. The reason for the large error is that for this example the default points are too close together and so there is noticeable numerical round-off error.
sol3 = First@NDSolve[DAE4, vars, {t, 0, 0}, Method -> {"DAEInitialization" -> {"Collocation", "CollocationPoints" -> 15, "CollocationRange" -> 1}}];
TableForm[Transpose[{Through[vars[0]], D[Through[vars[t]], t] /. t -> 0}] /. sol3, TableHeadings -> {Through[vars[0]], {"Value", "Derivative"}}, TableAlignments -> "Center"]There is a close relationship between "CollocationPoints" and "CollocationRange". The collocation range is computed based on the number of collocation points so as to avoid excessive round-off errors and to accommodate higher-precision computations. Unless explicitly specified, the "CollocationRange" is computed as ![]() , where
, where ![]() is the setting of the WorkingPrecision option and
is the setting of the WorkingPrecision option and ![]() is the setting of the "CollocationPoints" method option.
is the setting of the "CollocationPoints" method option.
Specifying Initial Conditions
One of the main differences between ODEs and DAEs is that in order to integrate a system of ODEs, initial conditions for all the variables must be provided. On the other hand, for a DAE, some of these initial conditions may be fixed and must be computed directly from the system. To elaborate, consider the ODE
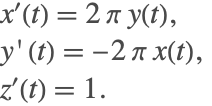
The initial conditions can be arbitrarily specified for the preceding system. Now consider a modification of the same system given as
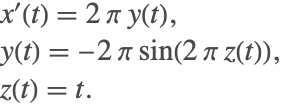
This system is a DAE, but the dynamics are identical to the ODE system. The major difference now is that the initial conditions ![]() and
and ![]() are not fixed, but rather are determined by the algebraic equation.
are not fixed, but rather are determined by the algebraic equation.
The preceding example is simple enough that some determination can be made as to which variables are fixed and perhaps the initial conditions manually computed. However, as the system gets more complicated and large, you must rely on additional tools.
In certain cases, the initial conditions are completely determined by the system of equations. To illustrate this case, consider the following linear DAE system
Though the system contains two derivatives, the solution and the initial conditions are completely determined by the system. No additional information is needed.
eqns = {Subscript[x, 2]'[t] + Subscript[x, 1][t] == Sin[t], Subscript[x, 3]'[t] + Subscript[x, 2][t] == Sin[t], Subscript[x, 3][t] == Cos[t]} ;
vars = {Subscript[x, 1], Subscript[x, 2], Subscript[x, 3]};sol = First@NDSolve[eqns, vars, {t, 0}]vt = Through[vars[t]];
xic = Thread[vt -> (vt /. sol) ] /. t -> 0Thread[D[vt, t] -> ((D[vt, t] /. t -> 0) /. sol) ] /. t -> 0It is important to note that it is often not possible to know which conditions are fixed and which ones are free. One approach that could be taken to gain some insight into the correct initial conditions and the order of magnitude of the initial conditions is to put the DAE equations directly into NDSolve without initial conditions and manipulate the options for the method "DAEInitialization".
Consider the pendulum system (2) represented as a first-order system. In order to uniquely define the state of the system, only two initial conditions are needed.
Clear[x, xp, y, yp, λ, vars, DAEPendulum];
DAEPendulum = (| |
| ---------------------- |
| x'[t] == xp[t] |
| xp'[t] == λ[t] x[t] |
| y'[t] == yp[t] |
| yp'[t] == λ[t] y[t] - 1 |
| x[t]^2 + y[t]^2 == 1 |) ;
vars = {x, xp, y, yp, λ};First, consider the case when no initial conditions are given for this DAE system. By default, the starting guess is taken to be 1 for all variables that have not been specified. Since no index reduction is performed, NDSolve automatically chooses the collocation algorithm.
sol1 = First@NDSolve[DAEPendulum, vars, {t, 0, 0}]TableForm[Transpose[{Through[vars[0]], D[Through[vars[t]], t] /. t -> 0}] /. sol1, TableHeadings -> {Through[vars[0]], {"Value", "Derivative"}}, TableAlignments -> "Center"]It is observed that the algorithm was able to find one possible set of initial conditions out of the infinitely many possible sets. At this point, it is of course very sensitive to the starting guesses. It is also important to note that convergence of the iterations is not guaranteed.
The initial starting guess can be changed using the option "DefaultStartingValue" for the collocation method. If an initial starting guess of -1 is used, then a different set of valid solutions will be found.
sol1 = First@NDSolve[DAEPendulum, vars, {t, 0, 0}, Method -> {"DAEInitialization" -> {"Collocation", "DefaultStartingValue" -> -1}}];
TableForm[Transpose[{Through[vars[0]], D[Through[vars[t]], t] /. t -> 0}] /. sol1, TableHeadings -> {Through[vars[0]], {"Value", "Derivative"}}, TableAlignments -> "Center"]As mentioned earlier, two initial conditions are sufficient to fix the state of the system. For the pendulum case, the value of ![]() and
and ![]() fixes the system.
fixes the system.
sol1 = First@NDSolve[{DAEPendulum, x[0] == 1, yp[0] == 1}, vars, {t, 0, 0}];
TableForm[Transpose[{Through[vars[0]], D[Through[vars[t]], t] /. t -> 0}] /. sol1, TableHeadings -> {Through[vars[0]], {"Value", "Derivative"}}, TableAlignments -> "Center"]If the state is truly fixed, then the system should theoretically be insensitive to the starting initial guess.
Table[
sol1 = First@NDSolve[{DAEPendulum, x[0] == 1, yp[0] == 1}, vars, {t, 0, 0}, Method -> {"DAEInitialization" -> {"Collocation", "DefaultStartingValue" -> dsv}}];
TableForm[Transpose[{Through[vars[0]], D[Through[vars[t]], t] /. t -> 0}] /. sol1, TableHeadings -> {Through[vars[0]], {"Value", "Derivative"}}, TableAlignments -> "Center"]
, {dsv, {1, -1}}]For certain systems, the computation of initial conditions is sensitive to the starting guess. To demonstrate, consider the following system.
DAE = (| |
| ----------------------------------- |
| Derivative[1][x1][t] == x3[t] |
| x2[t] (1 - x2[t]) == 0 |
| x1[t] x2[t] + x3[t] (1 - x2[t]) == t |);For this problem with x2[t]0, the general solution is {x1[t]x1[0]+t2/2,x2[t]0,x3[t]t}, so it is necessary to give x1[0] to determine the solution. By using a default value of 1 as the starting guess, the algorithm is forced to change the specified initial condition.
vars = {Subscript[x, 1], Subscript[x, 2], Subscript[x, 3]};
sol3 = NDSolve[{DAE, Subscript[x, 1][0] == 1}, vars, {t, 0, 0}, Method -> {"DAEInitialization" -> "Collocation"}]The code essentially switches to a different solution branch.
Through[vars[0]] /. sol3This happens because the default starting guess for the state ![]() is 1. During the Newton iterations, the system becomes singular because the second equation is identically satisfied, and as a result the iterations diverge. To avoid complete failure, the algorithm is forced to modify the specified condition of
is 1. During the Newton iterations, the system becomes singular because the second equation is identically satisfied, and as a result the iterations diverge. To avoid complete failure, the algorithm is forced to modify the specified condition of ![]() .
.
To avoid this behavior, a "better" starting guess can be given. Using a starting guess of -1, the iterations converge to the expected consistent initial condition.
sol3 = NDSolve[{DAE, Subscript[x, 1][0] == 1}, vars, {t, 0, 1}, Method -> {"DAEInitialization" -> {"Collocation", "DefaultStartingValue" -> -1}}] ;
Through[vars[0]] /. sol3Plot[Evaluate[{Subscript[x, 1][t], Subscript[x, 3][t]} /. First[sol3]], {t, 0, 1},
PlotStyle -> {StandardRed, StandardBlue}]QR Method
The QR decomposition method is based on the work of Shampine [S02]. This algorithm is intended for index-1 or index-0 systems. The algorithm makes use of the efficient QR decomposition technique to decouple the system variables and their derivatives. In doing so, at each iteration step the solution of one system is broken down into two smaller systems of equations. For an ![]() -variable DAE system, the QR algorithm needs to handle at most a matrix of size
-variable DAE system, the QR algorithm needs to handle at most a matrix of size ![]() as opposed to a matrix of size
as opposed to a matrix of size ![]() if the collocation method is used. In most cases, the algorithm only needs to handle matrices much smaller than
if the collocation method is used. In most cases, the algorithm only needs to handle matrices much smaller than ![]() . This makes the method quite efficient in handling very large systems. A brief description of the underlying algorithm is provided in this section.
. This makes the method quite efficient in handling very large systems. A brief description of the underlying algorithm is provided in this section.
Given an index-reduced system of the form ![]() , the system can first be linearized about an initial guess
, the system can first be linearized about an initial guess ![]() and
and ![]() as
as
A QR decomposition is performed on the Jacobian matrix ![]() such that
such that ![]() , where
, where ![]() is an orthogonal matrix,
is an orthogonal matrix, ![]() is an upper triangular matrix and
is an upper triangular matrix and ![]() is a permutation matrix. For DAEs, the matrix
is a permutation matrix. For DAEs, the matrix ![]() will not have a full row-rank. Depending on the rank of the matrix
will not have a full row-rank. Depending on the rank of the matrix ![]() , the linearized system is then written as
, the linearized system is then written as
The transformed system is solved in two steps:
Once the components are found, the transformed variables are converted back into the original form, using the permutation matrix, and the process is repeated until convergence.
The QR method can be called from the method "DAEInitialization", using Method->{"DAEInitialization"->{"QR",qropts}}, where qropts are options for the QR method.
| "DefaultStartingValue" | Automatic | starting value for unspecified components in the nonlinear iterations; option can be a one-element value ig/{ig}, or a list of two numbers {ig1,ig2}, where ig1,ig2 are the starting values for the variable and its derivative, respectively |
| "MaxIterations" | 100 | maximum iterations |
Options for QR initialization.
Consider the pendulum example.
Clear[x, y, λ, t, pendulumDAE];
pendulumDAE = (| |
| ---------------------- |
| x''[t] == x[t] λ[t] |
| y''[t] == y[t] λ[t] - 1 |
| x[t]^2 + y[t]^2 == 1 |) ;Given that this is a high-index DAE, an index reduction must be performed on the system. Once the system has been reduced to index 1/0, all the variables and their derivatives must be initialized.
sol = NDSolve[{pendulumDAE, x[0] == 1, y'[0] == 1}, {x, y, λ}, {t, 0, 10}, Method -> {"IndexReduction" -> Automatic, "DAEInitialization" -> "QR"}]GraphicsRow[Plot[Evaluate[#[t] /. sol], {t, 0, 10}, PlotLabel -> #]& /@ {x, y, λ}]In the preceding example, the initial conditions are given such that they lead to a consistent set of starting values. In the event that the initial conditions are not consistent, the algorithm attempts to find consistent starting values.
solQR1 = NDSolve[{pendulumDAE, x[0] == 2, y'[0] == 1}, {x, y, λ}, {t, 0, 10}, Method -> {"IndexReduction" -> Automatic, "DAEInitialization" -> "QR"}]GraphicsRow[Plot[Evaluate[#[t] /. solQR1], {t, 0, 10}, PlotLabel -> #]& /@ {x, y, λ}, ImageSize -> 500]{x[0], y[0], λ[0]} /. solQR1{x'[0], y'[0], λ'[0]} /. solQR1By specifying the option "DefaultStartingValue", the initial guess used for the iteration is changed. For inconsistent initial conditions, this may lead to a different consistent set.
solQR2 = NDSolve[{pendulumDAE, x[0] == 2, y'[0] == 1}, {x, y, λ}, {t, 0, 1}, Method -> {"IndexReduction" -> Automatic, "DAEInitialization" -> {"QR", "DefaultStartingValue" -> -1}}];GraphicsRow[Plot[Evaluate[#[t] /. solQR1], {t, 0, 10}, PlotLabel -> #]& /@ {x, y, λ}, ImageSize -> 500]{x[0], y[0], λ[0]} /. solQR2{x'[0], y'[0], λ'[0]} /. solQR2BLT Method
The BLT method is based on transforming an index-reduced system into a block lower triangular form and then solving subsets of the system iteratively. The subsets themselves are solved using a Gauss–Newton method. This is sometimes advantageous because the index reduction algorithm that generates the index-reduced system tends to already have a block lower triangular form and it reduces the computational complexity by working with smaller subsystems with correspondingly smaller matrix computations. The algorithm also checks for inconsistent initial conditions and attempts to correct them.
The BLT method can be called from the method "DAEInitialization", using Method->{"DAEInitialization"->{"BLT",bltopts}}, where bltopts are options for the BLT method.
| "DefaultStartingValue" | Automatic | starting value for unspecified components in the nonlinear iterations; option can be a one-element value ig/{ig}, or a list of two numbers {ig1,ig2}, where ig1,ig2 are the starting values for the variable and its derivative, respectively |
| "MaxIterations" | 100 | maximum iterations |
To see the advantage of using the BLT method, it is important to recognize that the index reduction algorithm leads to an expanded system of equations that are index 1 or index 0. Consider the following chemical systems example that describes an exothermic reaction.
eqns = (| |
| -------------------------------------------- |
| c'[t] + c[t] + r[t] == 4 + t + t ^ 2 |
| T'[t] + 2 T[t] + r[t] + Tc[t] == 1 + Exp[-t] |
| 1 + T[t]Log[r[t] / c[t]] == 0 |
| c[t] == Cosh[t - 1] |) ;
vars = {c, r, T, Tc};state = First@NDSolve`ProcessEquations[eqns, vars, t, Method -> {"IndexReduction" -> True}];
residual = state["NumericalFunction"]["FunctionExpression"];The original DAE consists of four equations, while the index-reduced system consists of eight equations. The index-reduced equations are as follows.
MatrixForm[residual[[2]]]Note that the expanded system now contains dummy derivatives. The expanded system can be analyzed further to see the structure of the system.
neq = residual[[2]];
nvars = residual[[1, 2 ;; 9]];
incidenceMatrix = NDSolve`StructuralIncidenceArray[neq, nvars];
MatrixForm[incidenceMatrix]{bltrow, bltcol} = SparseArray`BlockTriangularOrdering[incidenceMatrix];
TableForm[Table[{nvars[[bltcol[[indx]]]], neq[[bltrow[[indx]]]]}, {indx, 1, Length[bltrow]}], TableHeadings -> {None, {"solve for", "using Equation"}}, TableAlignments -> "Center"]This indicates that the expanded system can actually be solved sequentially. Therefore, rather than having one system of nine equations, a single equation can be solved sequentially. From an initialization perspective, setting t->0 would allow for the initialization of the variables.
{bltrow, bltcol} = SparseArray`BlockTriangularOrdering[incidenceMatrix];
TableForm[Table[{nvars[[bltcol[[indx]]]], neq[[bltrow[[indx]]]] /. t -> 0.}, {indx, 1, Length[bltrow]}], TableHeadings -> {None, {"solve for", "using Equation"}}, TableAlignments -> "Center"]This is the main principle behind the initialization using the BLT method. The BLT method is found to be especially useful and computationally efficient when dealing with large systems having a lower triangular form.
sol = NDSolve[eqns, vars, {t, 0, 3.5}, Method -> {"IndexReduction" -> True, "DAEInitialization" -> "BLT"}] ;Row[Plot[Evaluate[#[t] /. sol], {t, 0, 3.5}, PlotLabel -> #, ImageSize -> Small]& /@ vars]For cases with inconsistent initial conditions, the BLT method can suitably modify the initial conditions. It is, however, important to note that the results that obtained from the BLT method and the QR method may be different. Consider the pendulum example with inconsistent initial conditions.
Clear[x, y, λ, t];
PendulumDAE = (| |
| ---------------------- |
| x''[t] == x[t] λ[t] |
| y''[t] == y[t] λ[t] - 1 |
| x[t]^2 + y[t]^2 == 1 |) ;solQR = NDSolveValue[{PendulumDAE, x[0] == 2, y'[0] == 1}, {x, y, λ}, {t, 0, 1}, Method -> {"IndexReduction" -> True, "DAEInitialization" -> "QR"}];{Through[solQR[0]], D[Through[solQR[t]], t] /. t -> 0}solBLT = NDSolveValue[{PendulumDAE, x[0] == 2, y'[0] == 1}, {x, y, λ}, {t, 0, 1}, Method -> {"IndexReduction" -> True, "DAEInitialization" -> "BLT"}];{Through[solBLT[0]], D[Through[solBLT[t]], t] /. t -> 0}Inconsistent Initial Conditions
One of the main challenges in DAE system formulations and their solution is the fact that the starting initial conditions must be consistent. At the outset, this might seem straightforward, but for high-index DAE systems, you can easily encounter hidden conditions/equations that the initial conditions must also satisfy. If NDSolve encounters initial conditions that it finds to be inconsistent, it will attempt to correct them.
To illustrate the points about hidden constraints and inconsistent initial conditions, consider the pendulum system (2).
As a first case, consider when the initial conditions violate the algebraic constraint for the system. This is done by intentionally setting the initial condition for ![]() , so that it always violates the constraint
, so that it always violates the constraint ![]() .
.
ics = {x[0] == 2, yp[0] == 1};If this system is given to NDSolve, an NDSolve::ivres message is generated, indicating that the initial conditions were found to be inconsistent. It then attempts to find a consistent initial condition using the inconsistent value as a starting guess for its iterations.
sol3 = First@NDSolve[{x'[t] == xp[t], xp'[t] == λ[t] x[t], y'[t] == yp[t], yp'[t] == λ[t] y[t] - 1, x[t] ^ 2 + y[t] ^ 2 == 1, ics}, {x, xp, y, yp, λ}, {t, 0, 0}, Method -> {"DAEInitialization" -> {"Collocation"}}];
vars = {x, xp, y, yp, λ};
TableForm[Transpose[{Through[vars[0]], D[Through[vars[t]], t] /. t -> 0}] /. sol3, TableHeadings -> {Through[vars[0]], {"Value", "Derivative"}}, TableAlignments -> "Center"]Sometimes, it may not be clear if the specified conditions might be consistent or not. It may seem that the initial conditions satisfy the constraints, but may not satisfy the hidden constraint.
ics = {x[0] == 1, y[0] == 0, yp[0] == 1, xp[0] == 0.1};These initial conditions satisfy the equation ![]() but fail to satisfy the implicit constraint
but fail to satisfy the implicit constraint ![]() . This constraint is not obvious because it is hidden and is only found by index reduction. The collocation algorithm does not perform index reduction and operates on the original equations. Even in the absence of an index-reduced system, the collocation algorithm is able to detect an inconsistency in the initial conditions and attempts to rectify it.
. This constraint is not obvious because it is hidden and is only found by index reduction. The collocation algorithm does not perform index reduction and operates on the original equations. Even in the absence of an index-reduced system, the collocation algorithm is able to detect an inconsistency in the initial conditions and attempts to rectify it.
sol3 = First@NDSolve[{x'[t] == xp[t], xp'[t] == λ[t] x[t], y'[t] == yp[t], yp'[t] == λ[t] y[t] - 1, x[t] ^ 2 + y[t] ^ 2 == 1, ics}, {x, xp, y, yp, λ}, {t, 0, 0}, Method -> {"DAEInitialization" -> {"Collocation"}}];
vars = {x, xp, y, yp, λ};
TableForm[Transpose[{Through[vars[0]], D[Through[vars[t]], t] /. t -> 0}] /. sol3, TableHeadings -> {Through[vars[0]], {"Value", "Derivative"}}, TableAlignments -> "Center"]DAE Reinitialization with Events
Consider a system of two equations with a discrete variable where a state change is made at ![]() .
.
Clear[x, y, s, t];
vars = {x[t], y[t], s[t]};
eqns = {x'[t] == y[t], y[t] == s[t] x[t], y[0] == 1, x[0] == 1};sol = NDSolveValue[{eqns, WhenEvent[t == 1, s[t] -> 2]}, vars, {t, 0, 2}, DiscreteVariables -> s] ;
Plot[sol, {t, 0, 2}, PlotStyle -> {StandardRed, StandardBlue, StandardGreen}]In the preceding example, initial conditions for ![]() and
and ![]() are given. The initialization code automatically computes the consistent initial condition
are given. The initialization code automatically computes the consistent initial condition ![]() . At time
. At time ![]() , an event is triggered that says that the discrete variable should be changed from 1 to 2. At time
, an event is triggered that says that the discrete variable should be changed from 1 to 2. At time ![]() , a reinitialization of the variables needs to take place. The variable
, a reinitialization of the variables needs to take place. The variable ![]() is called a modified variable. The following strategy is adopted during reinitialization:
is called a modified variable. The following strategy is adopted during reinitialization:
1. Keep all the state, discrete, and modified variables fixed. If a state variable has a derivative fixed (or specified to be changed), then that variable can be changed.
2. If strategy 1 fails to reinitialize, then keep the state variables and modified variables fixed and allow other variables and their derivatives to change.
3. If strategy 2 fails, then the modified variables and the state variables with derivatives in the DAE are kept fixed. All other variables and their derivatives can be changed.
4. If strategy 3 fails, then only the modified variables are kept fixed and all the state variables and their derivatives are allowed to change.
Just before the reinitialization, the values of ![]() ,
, ![]() , and
, and ![]() are as follows.
are as follows.
sol /. t -> 0.999999999Based on the outlined strategy, at time ![]() , using strategies 1 and 2, it is required that
, using strategies 1 and 2, it is required that ![]() ,
, ![]() , and
, and ![]() do not change. Given that
do not change. Given that ![]() , this clearly violates the algebraic equation
, this clearly violates the algebraic equation ![]() . Strategies 1 and 2 therefore fail.
. Strategies 1 and 2 therefore fail.
Strategy 3 requires that variables with derivatives should not change. Therefore ![]() is kept fixed (along with
is kept fixed (along with ![]() ) and
) and ![]() is allowed to change. This modifies the value of
is allowed to change. This modifies the value of ![]() as shown in the plot (the blue line).
as shown in the plot (the blue line).
sol /. t -> 1.000000001WhenEvent allows for simultaneous and sequential evaluation of event actions, including state changes.
After each state change, even for the same event, the DAE is reinitialized using the preceding strategy, so if possible, it is more efficient to just give one rule for the state changes needed. The final state when there are multiple state changes done at the same event time may be different because the new values are used in each subsequent evaluation and setting and for DAEs these values may depend on the reinitialization. Consider the previous problem with additional events.
sol = NDSolveValue[{eqns, WhenEvent[t == 1, {s[t] -> 2, x[t] -> y[t], y[t] -> x[t]}]}, vars, {t, 0, 2}, DiscreteVariables -> s] ;
Plot[sol, {t, 0, 2}, PlotStyle -> {StandardRed, StandardBlue, StandardGreen}]To see why the solution is different from the one preceding, it is necessary to follow the sequence of settings. First ![]() is set to 2 and the DAE is reinitialized before evaluating the other settings. This reinitialization changes the value of
is set to 2 and the DAE is reinitialized before evaluating the other settings. This reinitialization changes the value of ![]() to 2 since that is how the strategy finds a solution consistent with the residual. Execution of the second action sets
to 2 since that is how the strategy finds a solution consistent with the residual. Execution of the second action sets ![]() to 2 (the current value of
to 2 (the current value of ![]() ), but this is inconsistent with the residual, so since
), but this is inconsistent with the residual, so since ![]() is an algebraic variable its value is set to 4 (
is an algebraic variable its value is set to 4 (![]() ). Finally, setting
). Finally, setting ![]() to
to ![]() resets
resets ![]() to 2, and to avoid modifying the newly set algebraic variable, the value of
to 2, and to avoid modifying the newly set algebraic variable, the value of ![]() is reset to 1.
is reset to 1.
One way to see the sequence of changes is to put in Print commands between the settings.
sol = NDSolveValue[{eqns, WhenEvent[t == 1, {Print["Before ", vars], s[t] -> 2, Print["After s[t]->2 ", vars], x[t] -> y[t], Print["After x[t]-> y[t] ", vars], y[t] -> x[t], Print["After y[t]-> x[t] ", vars]}]}, vars, {t, 0, 2}, DiscreteVariables -> s] ;
Plot[sol, {t, 0, 2}, PlotStyle -> {StandardRed, StandardBlue, StandardGreen}]sol = NDSolveValue[{eqns, WhenEvent[t == 1, {Print["Before ", vars], s[t] -> 2, Print["After s[t]->2 ", vars], y[t] -> x[t], Print["After y[t]-> x[t] ", vars], x[t] -> y[t], Print["After x[t]-> y[t] ", vars]}]}, vars, {t, 0, 2}, DiscreteVariables -> s] ;
Plot[sol, {t, 0, 2}, PlotStyle -> {StandardRed, StandardBlue, StandardGreen}]So a different sequence of settings leads to a different solution.
With a single rule there is only one initialization, so if all of the variables are set, the values given should be consistent, or reinitialization strategy may fail or not give the expected values.
sol = NDSolveValue[{x'[t] == y[t], y[t] == s[t] x[t], y[0] == 1, x[0] == 1, WhenEvent[t == 1, {s[t], x[t], y[t]} -> {2, y[t], x[t]}]}, {x[t], y[t], s[t]}, {t, 0, 2}, DiscreteVariables -> s]Here ![]() ,
, ![]() , and
, and ![]() are fixed. This is a very restrictive constraint, and all the strategies fail.
are fixed. This is a very restrictive constraint, and all the strategies fail.
Setting a variable to its current value within a single rule in effect forces it to stay the same.
sol = NDSolveValue[{x'[t] == y[t], y[t] == s[t] x[t], y[0] == 1, x[0] == 1, WhenEvent[t == 1, {s[t], y[t]} -> {2, y[t]}]}, {x[t], y[t], s[t]}, {t, 0, 2}, DiscreteVariables -> s] ;
Plot[sol, {t, 0, 2}, PlotStyle -> {StandardRed, StandardBlue, StandardGreen}]Since ![]() stays the same,
stays the same, ![]() is forced to change.
is forced to change.
DAE Examples
Torus Problem
This is a test problem taken from Campbell and Moore [CM95]. The DAE describes the motion of a particle in 3D. This is an index-3 DAE with three position variables, three velocity variables, and one constraint. The solution manifold is four dimensional, and the exact solution is given by
Clear[x, y, z, r, ρ, c1, x1, x2, x3, u1, u2, u3, λ, eqns, vars, exactTorusSol, torusSol, ics];
r = 10;
ρ = 5;
c1 = (1 - (r/Sqrt[x1[t]^2 + x2[t]^2]));eqns = (| |
| ------------------------------------------------------------------------- |
| x1'[t] == u1[t] |
| x2'[t] == u2[t] |
| x3'[t] == u3[t] |
| u1'[t] == u3[t] Cos[t] - x3[t] Sin[t] - u2[t] + 2 c1 x1[t] λ[t] |
| u2'[t] == u3[t] Sin[t] + x3[t] Cos[t] + u1[t] + 2 c1 x2[t] λ[t] |
| u3'[t] == -x3[t] + 2 x3[t] λ[t] |
| x1[t]^2 + x2[t]^2 + x3[t]^2 - 2 r Sqrt[x1[t]^2 + x2[t]^2] + r^2 - ρ^2 == 0 |);
vars = {x1, x2, x3, u1, u2, u3, λ};exactTorusSol = {(ρ * Cos[2 Pi - t] + r) * Cos[t], (ρ Cos[2 Pi - t] + r) Sin[t], (ρ Sin[2 Pi - t])};
ics = Thread[Through[vars[[1 ;; -2]][0]] == Flatten[{exactTorusSol, D[exactTorusSol, t]}] /. t -> 0]torusSol = NDSolve[{eqns, ics}, vars, {t, 0, 10 Pi}, Method -> {"IndexReduction" -> {Automatic, "IndexGoal" -> 0}, "EquationSimplification" -> "Residual"}]ParametricPlot3D[Evaluate[{x1[t], x2[t], x3[t]} /. torusSol], {t, 0, 10 Pi}]errors = Transpose[{({x1[t], x2[t], x3[t]} /. First@torusSol), exactTorusSol}];Plot[Evaluate[#], {t, 0, 10 Pi}]& /@ errorsDischarge of Pressure from a Tank
This is a simplified model of a dynamic process in petrochemical engineering. The details of this model can be found in Hairer et. al. [HLR89]. This is an index-2 system.
Clear[m, M, μ, P, p, c, k, eqns, vars, sol];
α = 3.35; β = 0.075; γ = 0.0001; a = 49.58;b = 1.2;eqns = (| |
| ------------------------------------------------------------------------ |
| (1/20) (-c[t] + k[t]) + Derivative[1][k][t] == 0 |
| (1/75) (-99 + p[t]) + Derivative[1][c][t] + (Derivative[1][p][t]/15) == 0 |
| m[t] - μ[t] + Derivative[1][M][t] == 0 |
| -α - β m[t] - γ m[t]^2 + (p[t]/P[t]) == 0 |
| -a^2 + P[t]^2 - (μ[t]^2/b^2 k[t]^2) == 0 |
| M[t] - 20 P[t] == 0 |
| -15 + 5 Tanh[10 - t] + μ[t] == 0 |);
vars = {μ, P, M, m, c, k, p};sol = First@Quiet@NDSolve[{eqns, k[0] == 0.25, p[0] == 99.1}, vars, {t, 0, 40}, Method -> {"IndexReduction" -> {Automatic, "IndexGoal" -> 0}}]Row[Plot[Evaluate[#[t] /. sol], {t, 0, 40}, PlotRange -> All, PlotLabel -> #[t], ImageSize -> 125]& /@ vars]Non-Flexible Slider Crank
This example is a simple constrained multibody system. The system consists of a crank of mass m1, which is hinged on a fixed surface, a slider of mass m3, and a connecting rod of mass m2. The slider is constrained to move only in the horizontal plane. Due to the masses of the individual components, the moments of inertia would have to be considered during the construction of the system. A schematic of the problem is shown following. The system can be completely defined using the two angles.

Clear[J1, J2, m1, m2, m3, L1, L2, LM, g, Fs, s1, LHS, RHS, eqns, contraints, vars, SliderCrankSol];The state of the slider-crank mechanism can be described completely by two angles ![]() and the distance
and the distance ![]() of the slider from the origin.
of the slider from the origin.
vars = {α1, α2, z, λ1, λ2};Fs[t] := -1;The equations of motion are derived by resolving the forces and applying Newton's law ![]() and
and ![]() . The crank and connecting rod have mass and therefore inertia.
. The crank and connecting rod have mass and therefore inertia.
s1 = Sin[α1[t] - α2[t]];
c1 = Cos[α1[t] - α2[t]];
LM = (L1 L2 m2) / 2;
eqns = {(J1 + m2 L1^2) α1''[t] + LM c1 α2''[t] == -LM s1 α2'[t]^2
- (L1 Cos[α1[t]] λ1[t] + L1 Sin[α1[t]] λ2[t]),
LM c1 α1''[t] + J2 α2''[t] == LM s1 α1'[t]^2
- (L2 Cos[α2[t]] λ1[t] + L2 Sin[α2[t]] λ2[t]),
m3 z''[t] == -Fs[t] - λ2[t]};constraints = (| |
| ---------------------------------------- |
| L1 Sin[α1[t]] + L2 Sin[α2[t]] == 0 |
| z[t] - L1 Cos[α1[t]] - L2 Cos[α2[t]] == 0 |);paramsFSC = {J1 -> 4.5, J2 -> 5.5, m1 -> 1, m2 -> 1, m3 -> 1, L1 -> 1, L2 -> 2, g -> 9.81};{sliderCrank} = NDSolve[{eqns, constraints, α1[0] == Pi / 4, α1'[0] == -1} /. paramsFSC, vars, {t, 0, 20}, Method -> {"IndexReduction" -> Automatic}];Row[Plot[Evaluate[#[t] /. sliderCrank], {t, 0, 20}, PlotRange -> All, PlotLabel -> #, ImageSize -> Small]& /@ vars]bar[loc_ : {0, 0}, rotate_ : 0, scale_ : 1, length_ : 1, width_ : .1, color_ : Hue[.6, .2, .9]] :=
Module[{},
GraphicsGroup[{
Rotate[{
color, EdgeForm[Directive[LightDarkSwitched[Black, White], AbsoluteThickness[.5]]],
(* polygon instead of rounded rectangle in case texture is needed *)
Polygon[ Flatten[{Table[loc + scale{width Sin[ a Pi], width Cos[a Pi]}, {a, 1, 2, 1 / 16}],
Table[{length, 0} + loc + scale{width Sin[ a Pi], width Cos[a Pi]}, {a, 0, 1, 1 / 16}]}, 1]],
AbsolutePointSize[5], LightDarkSwitched[Black, White], Point[loc], Point[loc + scale{length, 0}]
}, rotate Degree, loc]
}]
]
barFlange[loc_ : {0, 0}, rotate_ : 0, scale_ : 1, length_ : 1, width_ : .1, size1_ : 1, size2_ : 1, color_ : Hue[.6, .2, .9]] :=
Module[{},
GraphicsGroup[{
Rotate[{
color, EdgeForm[Directive[LightDarkSwitched[Black, White], AbsoluteThickness[.5]]],
Polygon[ {loc + scale{0, -width size1 }, loc + scale{0, width size1 }, loc + scale{length, width size2 }, loc + scale{length, -width size2 }}],
Lighter[color, .5], Disk[loc, scale width size1], Disk[loc + scale{length, 0}, scale width size2],
(* pins *)
StandardGray, Disk[loc, .4scale width size1], Disk[loc + scale{length, 0}, .4scale width size2]
}, rotate Degree, loc]
}]
]
dimensionLine[loc_ : {0, 0}, rotate_ : 0, scale_ : 1, text_ : "1", length_ : 1, offset_ : {0, 0}] :=
Module[{},
GraphicsGroup[{
Rotate[{
LightDarkSwitched[Black, White], AbsoluteThickness[.5], Line[{offset + loc + scale{0, 0}, offset + loc + scale{0, .1}}],
Arrowheads[{-Small, Small}], Arrow[{offset + loc + scale{0, .05}, offset + loc + scale{length, .05}}],
Line[{offset + loc + scale{length, 0}, offset + loc + scale{length, .1}}],
Text[text, offset + loc + scale{length / 2, .05}, Background -> LightDarkSwitched[White, Black]]
}, rotate Degree, loc]
}]
]
fixedHinge[loc_ : {0, 0}, rotate_ : 0, scale_ : 1] :=
Module[{},
GraphicsGroup[{
Rotate[{
GrayLevel[.85], EdgeForm[Directive[LightDarkSwitched[Black, White], AbsoluteThickness[.5]]], Polygon[ Flatten[{{loc + scale{-.25, -.5}}, Table[loc + scale{.15Sin[ a Pi], .15Cos[a Pi]}, {a, 1.55, 2.45, .9 / 16}], {loc + scale{.25, -.5}}}, 1]],
GrayLevel[.7], EdgeForm[], Rectangle[loc + scale{-.5, -.75}, loc + scale{.5, -.5}],
LightDarkSwitched[Black, White], AbsoluteThickness[.5], Line[{loc + scale{-.5, -.5}, loc + scale{.5, -.5}}],
AbsolutePointSize[5], LightDarkSwitched[Black, White], Point[{0, 0}]
}, rotate Degree, loc]
}]
]
slider[loc_ : {0, 0}, rotate_ : 0, scale_ : 1, length_ : 1, width_ : .1, fixedLength_ : 2, pos_ : {0, 0}, color_ : Hue[0, .2, .9]] :=
Module[{},
GraphicsGroup[{
Rotate[{
color, EdgeForm[{LightDarkSwitched[Black, White], AbsoluteThickness[.5]}],
Rectangle[loc + pos + scale{-length, -width}, loc + pos + scale{length, width}],
GrayLevel[.7], EdgeForm[], Rectangle[loc + scale{-fixedLength length, -width - .25}, loc + scale{fixedLength length, -width}],
LightDarkSwitched[Black, White], AbsoluteThickness[.5], Line[{loc + scale{-fixedLength length, -width}, loc + scale{fixedLength length, -width}}],
GrayLevel[.7], EdgeForm[], Rectangle[loc + scale{-fixedLength length, width + .25}, loc + scale{fixedLength length, width}],
LightDarkSwitched[Black, White], AbsoluteThickness[.5], Line[{loc + scale{-fixedLength length, width}, loc + scale{fixedLength length, width}}]
}, rotate Degree, loc]
}]
]Animate[
rotate = (α1[t] /. sliderCrank) * (180 / Pi);
f1 = Graphics[{Red, Line[Map[Function[Evaluate[{#, λ1[#]} /. sliderCrank]], Range[0, t, 0.025]]]}];
f2 = Graphics[{Blue, Line[Map[Function[Evaluate[{#, λ2[#]} /. sliderCrank]], Range[0, t, 0.025]]]}];
{bLength, bfLength} = ({L1, L2} /. paramsFSC) * 0.3;
Column[{
Graphics[{
(* parts *)
bfAngle = ArcSin[bLength Cos[(90 - rotate) °] / bfLength] * 180 / Pi;
sliderLoc = {bLength Cos[rotate Pi / 180] + bfLength Cos[bfAngle °], 0};
slider[{.7, 0}, 0, .2, .7, .3, 3.5, sliderLoc - {.7, 0}, Hue[.05, .3, .9]],
bar[{0, 0}, rotate, 1, bLength, .04, Hue[.6, .2, .7]],
fixedHinge[{0, 0}, 0, .2],
bfLoc = {bLength Sin[(90 - rotate) °], bLength Cos[(90 - rotate) °]};
barFlange[bfLoc, -bfAngle, 1, bfLength, .04, 2, 1.2, Hue[.6, .2, .9]],
(* axis *)
LightDarkSwitched[Black, White], AbsoluteThickness[.5], Arrowheads[Medium],
Arrow[{{-.25, 0}, {.5, 0}}], (* x *)
Arrow[{{0, -.05}, {0, .5}}](* y *)
(* dimensions *)
,
(* force arrow *)
Opacity[1], Hue[0, 1, .8], AbsoluteThickness[2], Arrowheads[Medium], Arrow[{sliderLoc + {.35, 0}, sliderLoc + {.15, 0}}],
LightDarkSwitched[Black, White], Text[Style["F(t)", 12, Italic], sliderLoc + {.37, 0}, {-1, 0}]
}, PlotRange -> {{-.5, 1.5}, {-.5, .5}}, ImageSize -> 400]
,
Show[f1, f2, Frame -> True, PlotRange -> {{0, 10}, {-2, 4}}, PlotLabel -> Row[{Style["Tension in slider (λ1)", 14, StandardRed], " ", Style["Tension in rod (λ2)", 14, Blue]}], ImageSize -> 300]}, Alignment -> Center]
, {t, 0, 10}, SaveDefinitions -> True, AnimationRunning -> False]Slider Crank with Spring Damper Attaching the Links.
This is an extension of the simple slider crank mechanism. A spring and damper system is attached between the crank and the connecting rod. This spring constrains the range of motion of the crank, while the damper slowly brings the system to a steady state. The schematic of the system is given following.

Clear[c, L0, Lp, a, J1, J2, m1, m2, k, L, Lp, f, F, LHS, RHS1, RHS2, y1, y2, y3, λ1, λ2, eqns, constraints, vars, SliderCrankSol2, sol];The state of the slider-crank mechanism can be described completely by two angles ![]() and the distance
and the distance ![]() of the slider from the origin.
of the slider from the origin.
vars = {y1, y2, y3, λ1, λ2};F[t_] := 2;The equations of motion are derived by resolving the forces and applying Newton's law ![]() and
and ![]() . The crank and connecting rod have mass and therefore inertia.
. The crank and connecting rod have mass and therefore inertia.
L = Sqrt[y2[t]^2 - y2[t](Cos[y3[t]] + a Cos[y1[t]]) + ((1 + a^2)/4) + a (Cos[y3[t] - y1[t]]/2)] ;
Lp = (1/2 L)(2 y2[t] y2'[t] - y2'[t] (Cos[y3[t]] + a Cos[y1[t]]) + y2[t] (Sin[y3[t]] y3'[t] + a Sin[y1[t]] y1'[t]) - a Sin[y3[t] - y1[t]] ((y3'[t] - y1'[t])/2));
f = k * (L - L0) + c Lp;
eqns = {J1 y1''[t] == -(a f (Sin[(1/2) (-y1[t] + y3[t])] + Sin[y1[t]] y2[t])/2 L) - (1/2) Sin[y1[t]] λ1[t] - (1/2) Cos[y1[t]] λ2[t], m2 y2''[t] == F[t] + (f ((1/2) a Cos[y1[t]] + (1/2) Cos[y3[t]] - y2[t])/L) - λ1[t], J2 y3''[t] == -F[t] Sin[y3[t]] - (f ((1/2) a Sin[y1[t] - y3[t]] + Sin[y3[t]] y2[t])/2 L) - (1/2) Sin[y3[t]] λ1[t] - Cos[y3[t]] λ2[t]};constraints = (| |
| ---------------------------------------- |
| y2[t] - a Cos[y1[t]] - a Cos[y3[t]] == 0 |
| a Sin[y1[t]] + Sin[y3[t]] == 0 |);paramsFlexSC = {a -> 1 / 2, J1 -> 1, J2 -> 2, m1 -> 1, m2 -> 1, L0 -> 1, k -> 1, c -> 4};SliderCrankSol2 = First@NDSolve[{eqns, constraints, y1[0] == Pi / 4, y1'[0] == -1} /. paramsFlexSC, vars, {t, 0, 40}, Method -> "IndexReduction" -> Automatic];
Row[Plot[Evaluate[#[t] /. SliderCrankSol2], {t, 0, 40}, PlotRange -> All, PlotLabel -> #, ImageSize -> Small]& /@ vars]bar[loc_ : {0, 0}, rotate_ : 0, scale_ : 1, length_ : 1, width_ : .1, color_ : Hue[.6, .2, .9]] :=
Module[{},
GraphicsGroup[{
Rotate[{
color, EdgeForm[Directive[LightDarkSwitched[Black, White], AbsoluteThickness[.5]]],
(* polygon instead of rounded rectangle in case texture is needed *)
Polygon[ Flatten[{Table[loc + scale{width Sin[ a Pi], width Cos[a Pi]}, {a, 1, 2, 1 / 16}],
Table[{length, 0} + loc + scale{width Sin[ a Pi], width Cos[a Pi]}, {a, 0, 1, 1 / 16}]}, 1]],
AbsolutePointSize[5], LightDarkSwitched[Black, White], Point[loc], Point[loc + scale{length, 0}]
}, rotate Degree, loc]
}]
]
barFlange[loc_ : {0, 0}, rotate_ : 0, scale_ : 1, length_ : 1, width_ : .1, size1_ : 1, size2_ : 1, color_ : Hue[.6, .2, .9]] :=
Module[{},
GraphicsGroup[{
Rotate[{
color, EdgeForm[Directive[LightDarkSwitched[Black, White], AbsoluteThickness[.5]]],
Polygon[ {loc + scale{0, -width size1 }, loc + scale{0, width size1 }, loc + scale{length, width size2 }, loc + scale{length, -width size2 }}],
Lighter[color, .5], Disk[loc, scale width size1], Disk[loc + scale{length, 0}, scale width size2],
(* pins *)
Gray, Disk[loc, .4scale width size1], Disk[loc + scale{length, 0}, .4scale width size2]
}, rotate Degree, loc]
}]
]
barMidFlange[loc_ : {0, 0}, rotate_ : 0, scale_ : 1, length_ : 2, width_ : .1, size1_ : 1, size2_ : 1, mid_ : 1, color_ : Hue[.6, .2, .9]] :=
Module[{},
GraphicsGroup[{
Rotate[{
color, EdgeForm[Directive[LightDarkSwitched[Black, White], AbsoluteThickness[.5]]],
Polygon[ Flatten[{{loc + scale{0, -width size1 }, loc + scale{0, width size1 }}, Table[{length, 0} + loc + scale{width Sin[ a Pi], width Cos[a Pi]}, {a, 0, 1, 1 / 16}]}, 1]],
Lighter[color, .5], Disk[loc, scale width size1], Disk[loc + scale{mid length, 0}, scale width size2],
(* pins *)
Gray, Disk[loc, .4scale width size1], Disk[loc + scale{mid length, 0}, .4scale width size2]
}, rotate Degree, loc]
}]
]
coilSpring[loc_ : {0, 0}, force_ : 0, segments_ : 4, height_ : .1, endLength_ : .1, thickness_ : .015, ghost_ : None] :=
Module[{f, s, e},
{
f = force + 1;
s = (f - 2endLength) / (segments + .5);
e = endLength + s / 4;
GraphicsGroup[{
LightDarkSwitched[Black, White], Flatten@{
Thickness[thickness], JoinForm["Round"], CapForm["Butt"],
If[ghost === "Ghost", GrayLevel[0, .2], LightDarkSwitched[Black, White]], Line[Flatten[{{loc + {0, 0}, loc + { endLength, 0}},
Flatten[Table[{loc + { e + a s, -height}, loc + {e + a s + .5s, height}}, {a, 0, segments - 1}], 1],
{loc + {f - e, -height}, loc + {f - endLength, 0}, loc + {f - endLength, 0}, loc + {f, 0}}}, 1]],
If[ghost =!= "Ghost", {White, CapForm["Round"], Thickness[.5thickness], Line[{loc + {0, 0}, loc + { endLength, 0}}],
Table[Line[{loc + { e + a s, -height}, loc + {e + a s + .5s, height}}], {a, 0, segments - 1}],
Line[{loc + {f - e, -height}, loc + {f - endLength, 0}}], Line[{loc + {f - endLength, 0}, loc + {f, 0}}]}]}
}]
}]
dimensionLine[loc_ : {0, 0}, rotate_ : 0, scale_ : 1, text_ : "1", length_ : 1, offset_ : {0, 0}] :=
Module[{},
GraphicsGroup[{
Rotate[{
LightDarkSwitched[Black, White], AbsoluteThickness[.5], Line[{offset + loc + scale{0, 0}, offset + loc + scale{0, .1}}],
Arrowheads[{-Small, Small}], Arrow[{offset + loc + scale{0, .05}, offset + loc + scale{length, .05}}],
Line[{offset + loc + scale{length, 0}, offset + loc + scale{length, .1}}],
Text[text, offset + loc + scale{length / 2, .05}, Background -> White]
}, rotate Degree, loc]
}]
]
fixedHinge[loc_ : {0, 0}, rotate_ : 0, scale_ : 1] :=
Module[{},
GraphicsGroup[{
Rotate[{
GrayLevel[.85], EdgeForm[Directive[LightDarkSwitched[Black, White], AbsoluteThickness[.5]]], Polygon[ Flatten[{{loc + scale{-.25, -.5}}, Table[loc + scale{.15Sin[ a Pi], .15Cos[a Pi]}, {a, 1.55, 2.45, .9 / 16}], {loc + scale{.25, -.5}}}, 1]],
GrayLevel[.7], EdgeForm[], Rectangle[loc + scale{-.5, -.75}, loc + scale{.5, -.5}],
LightDarkSwitched[Black, White], AbsoluteThickness[.5], Line[{loc + scale{-.5, -.5}, loc + scale{.5, -.5}}],
AbsolutePointSize[5], LightDarkSwitched[Black, White], Point[{0, 0}]
}, rotate Degree, loc]
}]
]
slider[loc_ : {0, 0}, rotate_ : 0, scale_ : 1, length_ : 1, width_ : .1, fixedLength_ : 2, pos_ : {0, 0}, color_ : Hue[0, .2, .9]] :=
Module[{},
GraphicsGroup[{
Rotate[{
color, EdgeForm[{LightDarkSwitched[Black, White], AbsoluteThickness[.5]}],
Rectangle[loc + pos + scale{-length, -width}, loc + pos + scale{length, width}],
GrayLevel[.7], EdgeForm[], Rectangle[loc + scale{-fixedLength length, -width - .25}, loc + scale{fixedLength length, -width}],
LightDarkSwitched[Black, White], AbsoluteThickness[.5], Line[{loc + scale{-fixedLength length, -width}, loc + scale{fixedLength length, -width}}],
GrayLevel[.7], EdgeForm[], Rectangle[loc + scale{-fixedLength length, width + .25}, loc + scale{fixedLength length, width}],
LightDarkSwitched[Black, White], AbsoluteThickness[.5], Line[{loc + scale{-fixedLength length, width}, loc + scale{fixedLength length, width}}]
}, rotate Degree, loc]
}]
]
springDamper[loc2_ : {0, 0}, scale_ : 1, force2_ : 0, height2_ : .1, endLength2_ : 1, thickness_ : 2] :=
Module[{f, s, e, loc = {endLength2, .5}, force = 1, segments = 4, height = .4, endLength = .5},
{
loc = scale loc + loc2;
f = Dynamic@force2 + force + 1;
s = (f - 2endLength) / (segments + .5);
e = endLength + s / 4;
GraphicsGroup[{
LightDarkSwitched[Black, White], Flatten@{
(* spring *)
AbsoluteThickness[thickness], JoinForm["Round"], CapForm["Butt"],
LightDarkSwitched[Black, White], Line[Flatten[{{loc, loc + scale{ endLength, 0}},
Flatten[Table[{loc + scale{ e + a s, -height}, loc + scale{e + a s + .5s, height}}, {a, 0, segments - 1}], 1],
{loc + scale{f - e, -height}, loc + scale{f - endLength, 0}, loc + scale{f - endLength, 0}, loc + scale{f, 0}}}, 1]],
White, CapForm["Round"], AbsoluteThickness[.5thickness], Line[{loc, loc + scale{ endLength, 0}}],
Table[Line[{loc + scale{ e + a s, -height}, loc + scale{e + a s + .5s, height}}], {a, 0, segments - 1}],
Line[{loc + scale{f - e, -height}, loc + scale{f - endLength, 0}}], Line[{loc + scale{f - endLength, 0}, loc + scale{f, 0}}],
(* cylinder *)
Gray, Rectangle[loc + scale{.5f + .5, -1.3}, loc + scale{f - .25, -.7}],
Table[{If[t == thickness, LightDarkSwitched[Black, White], White], AbsoluteThickness[t],
Line[{loc + scale{f - 1.75, -.7}, loc + scale{f - .25, -.7}, loc + scale{f - .25, -1.3}, loc + scale{f - 1.75, -1.3}}], Line[{loc + scale{.5f + .5, -.7}, loc + scale{.5f + .5, -1.3}}],
Line[{loc + scale{0, -1}, loc + scale{.5f + .5, -1}}],
Line[{loc + scale{f, -1}, loc + scale{f - .25, -1}}]},
{t, {thickness, .5thickness}}],
(* frame *)
LightDarkSwitched[Black, White], AbsoluteThickness[thickness], Line[{loc, loc + scale{0, -1}}],
Line[{loc + scale{f, 0}, loc + scale{f, -1}}],
Line[{loc + scale{-endLength2, -.5}, loc + scale{0, -.5}}], Line[{loc + scale{f, -.5}, loc + scale{f + endLength2, -.5}}],
AbsolutePointSize[5], Point[loc + scale{-endLength2, -.5}], Point[loc + scale{f + endLength2, -.5}]}
}]
}]Animate[
rotate = (y1[t] /. SliderCrankSol2) * (180 / Pi);
scale = 0.7;
Module[{bLength = scale * 0.5, bfMidLength = scale * 0.5, bfLength = scale, bfAngle, bfLoc, sliderLoc},
Graphics[{
(* parts *)
bfAngle = ArcSin[bLength Cos[(90 - rotate) °] / bfMidLength] * 180 / Pi;
sliderLoc = {bLength Cos[rotate °] + bfMidLength Cos[bfAngle °], 0};
slider[{.6, 0}, 0, .15, .4, .2, 3, sliderLoc - {.6, 0}, Hue[.05, .3, .9]],
bar[{0, 0}, rotate, 1, bLength, .03, Hue[.6, .2, .7]],
fixedHinge[{0, 0}, 0, .2],
bfLoc = {bLength Sin[(90 - rotate) °], bLength Cos[(90 - rotate) °]};
barMidFlange[bfLoc, -bfAngle, 1, bfLength, .03, 1, 1, bfMidLength, Hue[.6, .2, .9]],
(* damper *)
springDamper[bfLoc / 4, .08, 9sliderLoc[[1]] - 4.5, .1, 1.35, 2.5],
(* axis *)
LightDarkSwitched[Black, White], AbsoluteThickness[.5], Arrowheads[Medium],
Arrow[{{-.25, 0}, {1.1, 0}}], (* x *)
Arrow[{{0, -.05}, {0, .5}}](* y *)
}, PlotRange -> {{-.15, 1.2}, {-.3, .5}}, ImageSize -> Medium]
],
{t, 0, 20}, SaveDefinitions -> True, AnimationRunning -> False]Two-Link Planar Robotic Arm
The two-link planar robotic arm is a frictionless, constrained mechanical system. The system consists of two links attached to each other through a joint, such that one end of the first link is held fixed, while the trajectory at the end of the second link is specified. The following figure shows a schematic of the system.

Clear[m1, m2, g, constraints, vars, θ1, θ2, λ, vt];The system can be completely defined using the angles between the links. Additional details of this system can be found in Ascher et al. [ACPR94].
vars = {θ1, θ2, λ};constraints = {x2 + y2 ^ 2 == 1.5};The equations of motion are derived by resolving the forces and applying Newton's law. The differential equations are derived for the angles. The Cartesian coordinates ![]() and
and ![]() are therefore represented in terms of the angle.
are therefore represented in terms of the angle.
x1 = L1 Cos[θ1[t]]; y1 = L1 Sin[θ1[t]];
x2 = x1 + L2 Cos[θ1[t] + θ2[t]]; y2 = y1 + L2 Sin[θ1[t] + θ2[t]];
eqns = {
((L1^2 m1/3) + m2 (L1^2 + (L2^2/3) + L1 L2 Cos[θ2[t]])) θ1''[t] + m2 ((L2^2/3) + (1/2) L1 L2 Cos[θ2[t]]) θ2''[t] == -(1/2) g L1 m1 Cos[θ1[t]] - g m2 (L1 Cos[θ1[t]] + (1/2) L2 Cos[θ1[t] + θ2[t]]) - (-L1 Sin[θ1[t]] - L2 Sin[θ1[t] + θ2[t]] + 2 (L1 Cos[θ1[t]] + L2 Cos[θ1[t] + θ2[t]]) (L1 Sin[θ1[t]] + L2 Sin[θ1[t] + θ2[t]])) λ[t] + (1/2) L1 L2 m2 Sin[θ1[t] + θ2[t]] (2 θ1'[t] θ2'[t] + θ2'[t]^2),
m2 ((L2^2/3) + (1/2) L1 L2 Cos[θ2[t]]) θ1''[t] + (1/3) L2^2 m2 θ2''[t] == -(1/2) g L2 m2 Cos[θ1[t] + θ2[t]] - (-L2 Sin[θ1[t] + θ2[t]] + 2 L2 Cos[θ1[t] + θ2[t]] (L1 Sin[θ1[t]] + L2 Sin[θ1[t] + θ2[t]])) λ[t] - (1/2) L1 L2 m2 Sin[θ1[t] + θ2[t]] θ1'[t]^2
};robotParams = {m1 -> 36, m2 -> 36, L1 -> 1, L2 -> 1, g -> 9.81};ics = {θ1[0] == 70. Degree, θ1'[0] == 0, θ2'[0] == 0};
roboticArmSol = First@NDSolve[{eqns, constraints, ics} /. robotParams, vars, {t, 0, 10}, Method -> {"IndexReduction" -> {Automatic}}, MaxSteps -> 100000]Row[Plot[Evaluate[#[t] /. roboticArmSol], {t, 0, 10}, PlotLabel -> #[t], PlotRange -> All, ImageSize -> Small]& /@ vars]paramplot = ParametricPlot[Evaluate[{x2, y2} /. robotParams /. roboticArmSol], {t, 0, 10}];
Animate[
{Subscript[θ, 1], Subscript[θ, 2]} = {θ1[t], θ2[t]} * (180 / Pi) /. roboticArmSol;
Module[{bLength = 1, b2Length = 1, b2Angle, b2Loc, endLoc},
Show[Graphics[{
(* parts *)
b2Angle = ArcSin[bLength Cos[(90 - Subscript[θ, 1]) °] / b2Length] * 180 / Pi;
b2Loc = {bLength Sin[(90 - Subscript[θ, 1]) °], bLength Cos[(90 - Subscript[θ, 1]) °]};
endLoc = b2Loc + {b2Length Sin[(Subscript[θ, 2] - (90 - Subscript[θ, 1]) + 180)°], -b2Length Cos[(Subscript[θ, 2] - (90 - Subscript[θ, 1]) + 180)°]};
bar[{0, 0}, Subscript[θ, 1], 1, bLength, .05, Hue[.6, .2, .9]],
fixedHinge[{0, 0}, 0, .2],
bar[b2Loc, Subscript[θ, 1] + Subscript[θ, 2], 1, b2Length, .05, Hue[.6, .2, .9]],
(* axis *)
LightDarkSwitched[Black, White], AbsoluteThickness[.5], Arrowheads[Medium],
Arrow[{{0, 0}, {.5, 0}}], (* x *)
LightDarkSwitched[Black, White], Text[Style["x", 12, Italic], {0, .54}],
Arrow[{{0, 0}, {0, .5}}], (* y *)
LightDarkSwitched[Black, White], Text[Style["y", 12, Italic], {.54, 0}]
(* dimensions *)
}, ImageSize -> Medium, PlotRange -> {{-2, 2}, {-2, 2}}], paramplot]
],
{t, 0, 10}, AnimationRunning -> False, SaveDefinitions -> True]n-Pendulum Problem
Clear[x, y, yp, c, eqns, vars, ics, i];
NPendulumDAESystem[np_, length_, gravity_, t_] := Module[{eqns, vars, ics, i},
x[0][t] = y[0][t] = 0; c[np + 1][t] = 0;
eqns = Flatten[Table[(| |
| --------------------------------------------------------------------------------------------- |
| x[i]''[t] == c[i][t] (x[i][t] - x[i - 1][t]) - c[i + 1][t] (x[i + 1][t] - x[i][t]) |
| y[i]''[t] == c[i][t] (y[i][t] - y[i - 1][t]) - c[i + 1][t] (y[i + 1][t] - y[i][t]) - gravity |
| (x[i][t] - x[i - 1][t])^2 + (y[i][t] - y[i - 1][t])^2 == length^2 |),
{i, np}]];
vars = Flatten[Table[{x[i], y[i], c[i]}, {i, np}]];
ics = Flatten[Table[{x[i][0] == i, y[i]'[0] == 1.1}, {i, np}]];
{eqns, vars, ics}]Clear[x, y, c];
{eqns, vars, ics} = NPendulumDAESystem[2, 1, 1, t];sol = Quiet@NDSolve[{eqns, ics}, vars, {t, 0, 30}, Method -> {"IndexReduction" -> {Automatic, "IndexGoal" -> 0}, "EquationSimplification" -> "Residual"}, MaxSteps -> 100000];
Row[Plot[Evaluate[#[t] /. sol], {t, 0, 30}, PlotLabel -> #, ImageSize -> Small]& /@ vars]Show[ParametricPlot[Evaluate[{x[1][t], y[1][t]} /. sol], {t, 0, 30}, PlotStyle -> StandardBlue],
ParametricPlot[Evaluate[{x[2][t], y[2][t]} /. sol], {t, 0, 30}, PlotStyle -> StandardRed],
Graphics[{{LightDarkSwitched[Black, White], CapForm["Round"], Thickness[0.03], Line[{{0, 0}, {x[1][10], y[1][10]}}]}, {Orange, Thickness[0.03], CapForm["Round"], Line[{{x[1][10], y[1][10]}, {x[2][10], y[2][10]}}]}}] /. sol,
PlotRange -> All, ImageSize -> 300]Transistor-Amplifier Circuit

Clear[ve, params, vb, r0, r1, r2, r3, r4, r5, α, β, c1, c2, c3, v23, node1, node2, node3, node4, node5, ics, sol, v1, v2, v3, v4, v5];
ve[t_] := (4 / 10) Sin[200 Pi t];
params = {vb -> 6, r0 -> 1000, r1 -> 9000, r2 -> 9000, r3 -> 9000, r4 -> 9000, r5 -> 9000, α -> 99 / 100, β -> 10 ^ -6, c1 -> 10 ^ -6, c2 -> 2 10 ^ -6, c3 -> 3 10 ^ -6};
v23[t_] = β (Exp[(v2[t] - v3[t]) / .026] - 1);
node1 = c1 (v2'[t] - v1'[t]) == v1[t] / r0 - ve[t] / r0;
node2 = c1(v1'[t] - v2'[t]) == (1 - α)v23[t] + v2 [t] / r1 + v2[t] / r2 - vb / r2;
node3 = c2 v3'[t] == v23[t] - v3[t] / r3;
node4 = c3(v4'[t] - v5'[t]) == vb / r4 - v4[t] / r4 - α v23[t];
node5 = c3(v4'[t] - v5'[t]) == v5[t] / r5;
ics = {v1[0] == 0, v2[0] == vb / 2, v3[0] == vb / 2, v4[0] == vb, v5[0] == 0};sol = First@NDSolve[{node1, node2, node3, node4, node5, ics} //. params, {v1, v2, v3, v4, v5}, {t, 0, 0.2}, Method -> {"EquationSimplification" -> "Residual"}, MaxSteps -> 100000] ;
Plot[Evaluate[{v3[t], v4[t]} /. sol], {t, 0, 0.2}, PlotRange -> All]Akzo-Nobel Chemical Reaction
The following system describes a chemical process in which two species, FLB and ZHU, are mixed while ![]() is constantly added to the system. The chemical names are fictitious. Details of the system and the dynamics associated with it can be found in [N93]. The reaction equations follow. Associated with each reaction, there are rates of reaction, which are specified. The algebraic constraint comes from the last reaction, which requires FLB and ZHU and its mixture to maintain a constant relationship.
is constantly added to the system. The chemical names are fictitious. Details of the system and the dynamics associated with it can be found in [N93]. The reaction equations follow. Associated with each reaction, there are rates of reaction, which are specified. The algebraic constraint comes from the last reaction, which requires FLB and ZHU and its mixture to maintain a constant relationship.

Fin = klA (pCO2 / H - CO2[t]);
r1 = k1 FLB[t]^2 CO2[t]^1 / 2;
r2 = k2 FLBT[t] ZHU[t];
r3 = (k2 / KK) FLB[t] ZLA[t];
r4 = k3 FLB[t] ZHU[t]^2 CO2[t];
r5 = k4 FLB[t] ZHU[t];
params = {k1 -> 18.7, k2 -> 0.58, k3 -> 0.09, k4 -> 0.42, KK -> 34.4, klA -> 3.3, Ks -> 115.83, pCO2 -> 0.9, H -> 737};eqns = {FLB'[t] == -2 r1 + r2 - r3 - r4, CO2'[t] == -0.5 r1 - r4 - 0.5r5 + Fin, FLBT'[t] == r1 - r2 + r3, ZHU'[t] == -r2 + r3 - 2 r4, ZLA'[t] == r2 - r3 + r5};
eqEqn = Ks FLB[t] ZHU[t] == FLBZHU[t];
ic = {FLB[0] == 0.444, CO2[0] == 0.00123, FLBT[0] == 0, ZHU[0] == 0.007, ZLA[0] == 0};sol = NDSolve[{eqns, eqEqn, ic} /. params, {FLB, ZHU, CO2, ZLA}, {t, 0, 200}];
Plot[Evaluate[#[t] /. sol], {t, 0, 200}, PlotRange -> All, PlotLabel -> #[t]]& /@ {FLB, ZHU, CO2, ZLA}Car-Axis Problem
The car-axis model is a simple multi-body system that is designed to simulate the behavior of a car axis on a bumpy road. A schematic of the system is shown following. The model consists of two wheels: the left wheel is assumed to be moving on a flat surface, while the right wheel moves over a bumpy surface. The bumpy surface is modeled as a sinusoid. The left and right wheels transfer their motion to the chassis of the car through two massless springs as shown following. The chassis of the car is modeled as a bar of mass M. Additional details of this model can be found in Mazzia et. al. [MM08]. This is an index-3 system.

Clear[yB, xL, yL, xB, L, m, Lleft, Lright, ϵ, eqns, ics, ω, carParams, params, vars, carAxis, M];The left tire is always on a flat surface, while the right tire periodically goes over a bump.
yB[t_] = h Sin[ω t];The distance between the wheels must always remain fixed and the car chassis must always have a fixed length.
constraints = {xL[t] xB[t] + yL[t] yB[t] == 0, (xL[t] - xR[t])^2 + (yL[t] - yR[t])^2 == L^2};m = ((ϵ^2M)/2);
xB[t_] = Sqrt[L^2 - yB[t]^2];
Lleft = Sqrt[xL[t]^2 + yL[t]^2];
Lright = Sqrt[(xR[t] - xB[t])^2 + ( yR[t] - yB[t])^2];
eqns = (| |
| ----------------------------------------------------------------------------------- |
| m xL''[t] == ((L0 - Lleft)xL[t]/Lleft) + λ1[t] xB[t] + 2 λ2[t] (xL[t] - xR[t]) |
| m yL''[t] == ((L0 - Lleft) yL[t]/Lleft ) + λ1[t] yB[t] + 2 λ2[t] (yL[t] - yR[t]) - m |
| m xR''[t] == (L0 - Lright)((xR[t] - xB[t])/Lright) - 2 λ2[t] (xL[t] - xR[t]) |
| m yR''[t] == (L0 - Lright) ((yR[t] - yB[t])/Lright) - 2 λ2[t] (yL[t] - yR[t]) - m |);
ics = {xL[0] == 0, yL[0] == 1 / 2, yR[0] == 1 / 2, yL'[0] == 0, yR'[0] == 0};carParams = {L -> 1, L0 -> (1/2), ϵ -> 10^-2, M -> 10, h -> 10^-1, ω -> 10};
vars = {xL, yL, xR, yR, λ1, λ2};carAxis = NDSolve[{eqns, constraints, ics} /. carParams, vars, {t, 0, 3}, Method -> {"IndexReduction" -> Automatic}, AccuracyGoal -> 7] ;Animate[
With[{t = tt},
Show[
(* ground *)
Plot[Evaluate[{h * Exp[-5 * (x - 1.2) ^ 2] * Sin[ω t]} - 0.14 /. carParams], {x, -0.9, 2}, Filling -> -0.5, FillingStyle -> Hue[.1, .2, .4], Prolog -> {Polygon[{Scaled[{0, 0}], Scaled[{1, 0}], Scaled[{1, 1}], Scaled[{0, 1}]}, VertexColors -> {Hue[.6, .2, 1], Hue[.6, .2, 1], Hue[.6, .7, .5], Hue[.6, .7, .5]}]}, PlotStyle -> Hue[.1, .4, .2], PlotRange -> {{-0.9, 1.9}, {-0.5, 1.5}}, Frame -> True, Axes -> False],
Graphics[{
(* Axle *)
{Thickness[0.03], Hue[.6, 1, .3], Line[{{xL[t] - 0.2, yL[t]} / 2, {(xB[t]) + 0.2, (yR[t] - 0 * yB[t]) / 2}}]},
(* tires *)
{Thickness[0.09], GrayLevel[.2], Line[{{Mean[{0 - 0.22, xL[t] - 0.22}], 0}, {Mean[{0 - 0.22, xL[t] - 0.22}], yL[t]}}]},
{Thickness[0.09], GrayLevel[.2], Line[{{Mean[{xB[t] + 0.22, xR[t] + 0.22}], yB[t]}, {Mean[{xB[t] + 0.22, xR[t] + 0.22}], yR[t]}}]},
(* springs *)
{Thickness[0.025], Hue[.1, 1, .9], Line[{{0 + 0.01, yL[0] / 2 + 0.03}, {xL[t] + 0.01, yL[t] + 0.2}}]},
{Thickness[0.025], Hue[.1, 1, .9], Line[{{xB[t], yB[t] / 2 + 0.28}, {xR[t] - 0.01, yR[t] + 0.2}}]},
(* chassis *)
{Thickness[0.01], Hue[.6, 1, .3], Line[{{xL[t] - 0.03, yL[t] + 0.2}, {xR[t] + 0.03, yR[t] + 0.2}}]},
(* body *)
{GrayLevel[1, .3], EdgeForm[{GrayLevel[1, .5]}], GeometricTransformation[
{Polygon[.5 + .0045{{-185., -105.}, {-195., -100.}, {-200., -95.}, {-215., 0}, {-215., 45.}, {-210., 50.}, {-205., 50.}, {-200., 65.}, {-190., 75.}, {-220., 75.}, {-230., 80.}, {-230., 95.}, {-225., 100.}, {-205., 105.}, {-190., 105.}, {-185., 100.}, {-180., 90.}, {-175., 90.}, {-160., 125.}, {-145., 155.}, {-135., 165.}, {-120., 172.}, {-75., 177.}, {0., 180.}, {75., 177.}, {120., 172.}, {135., 165.}, {145., 155.}, {160., 125.}, {175., 90.}, {180., 90.}, {185., 100.}, {190., 105.}, {205., 105.}, {225., 100.}, {230., 95.}, {230., 80.}, {220., 75.}, {190., 75.}, {200., 65.}, {205., 50.}, {210., 50.}, {215., 45.}, {215., 0}, {200., -95.}, {195., -100.}, {185., -105.}}], Polygon[.5 + .0045{{-145., 80.}, {-155., 90.}, {-145., 125.}, {-130., 155.}, {-120., 160.}, {-55., 165.}, {0., 165.}, {55., 165.}, {120., 160.}, {130., 155.}, {145., 125.}, {155., 90.}, {145., 80.}}], Polygon[.5 + .0045{{-190., 20.}, {-185., 25.}, {-150., 25.}, {-110., 20.}, {-100., 15.}, {-100., 10.}, {-110., 0.}, {-140., -0.08875739644975056}, {-160., -10.}, {-175., -10.}, {-185., -5.}, {-190., 5.}}], Polygon[.5 + .0045{{110., -0.08875739644975056}, {140., -0.08875739644975056}, {160., -10.}, {175., -10.}, {185., -5.}, {190., 5.}, {190., 20.}, {185., 25.}, {150., 25.}, {110., 20.}, {100., 15.}, {100., 10.}}], Polygon[.5 + .0045{{-85., 15.}, {-75., 20.}, {-25., 25.}, {0., 25.}, {25., 25.}, {75., 20.}, {85., 15.}, {90., 5.}, {90., -5.}, {85., -30.}, {75., -60.}, {65., -70.}, {55., -75.}, {-55., -75.}, {-65., -70.}, {-75., -60.}, {-85., -30.}, {-90., -5.}, {-90., 5.}}], Polygon[.5 + .0045{{-85., -50.}, {-90., -40.}, {-190., -40.}, {-205., -25.}, {-195., -50.}}], Polygon[.5 + .0045{{85., -50.}, {195., -50.}, {205., -25.}, {190., -40.}, {90., -40.}}]}, RotationTransform[ArcTan[xR[t] - xL[t], yR[t] - yL[t]]]]}
} /. carParams /. carAxis], ImageSize -> 400
]
]
, {tt, 0, .2Pi}, SaveDefinitions -> True, AnimationRunning -> False]Combined Elliptic-Parabolic PDE in 1D
The following is a synthetic example for solving a parabolic and an elliptic PDE that are coupled together in a nonlinear fashion. Spatial discretization of the PDEs results in a system that contains a significant number of algebraic variables. The equations are set up such that the analytic solution exists for the system. The details of the coupled system are given following.
Clear[u, v, nx, eqn1, eqn2, ic1, ic2, vars, eqn1, eqn2, ic1, ic2, vars, sol, PDEsol, order, p, npts];
npts = 100; order = 12; p = 10;
nx = Range[0, 1, 1 / (npts - 1)];
{ddx, d2dx2} = Map[NDSolve`FiniteDifferenceDerivative[Derivative[#], nx, "DifferenceOrder" -> order]["DifferentiationMatrix"]&, {1, 2}] ;
u = Array[u$[#][t]&, npts]; v = Array[v$[#][t]&, npts];
eqn1 = Thread[D[u, t] - D[v, t] == d2dx2.u + u (ddx.v) - v (ddx.u) + (2 π t)^2v];
eqn2 = Thread[d2dx2.v + (2 π t)^2 u == 0];eqn1[[{1, -1}]] = Thread[u[[{1, -1}]] == v[[{1, -1}]]] ;
eqn2[[1]] = v[[1]] == 0;
eqn2[[-1]] = ddx[[-1]].v == 2π t Cos[2 π t] ;ic1 = Thread[u == 0] /. t -> 0;
ic2 = Thread[v == 0] /. t -> 0;vars = Flatten[{u, v}] /. x__[t] :> x ;
PDEsol = First[NDSolve[{eqn1, eqn2, ic1, ic2}, vars, {t, 0, 3}]];time = Flatten@First[vars[[1]] /. PDEsol];
{usol, vsol} = Flatten[Table[Transpose[{nx, ConstantArray[ti, npts], # /. PDEsol}] /. t -> ti, {ti, time[[1]], time[[2]], 0.1}], 1]& /@ {u, v};
GraphicsRow[ListPlot3D[#, PlotRange -> All]& /@ {usol, vsol}, ImageSize -> 500]Multi-species Food Web Model (Combined Elliptic-Parabolic PDE in 2D)
This example is a model of the multi-species food web [B86]. Unlike the typical predator-prey problem, there is a spatial component of this problem. The predator-prey relationships are defined over a 2D spatial domain via a series of diffusion parameters. The general coupled PDE is given by
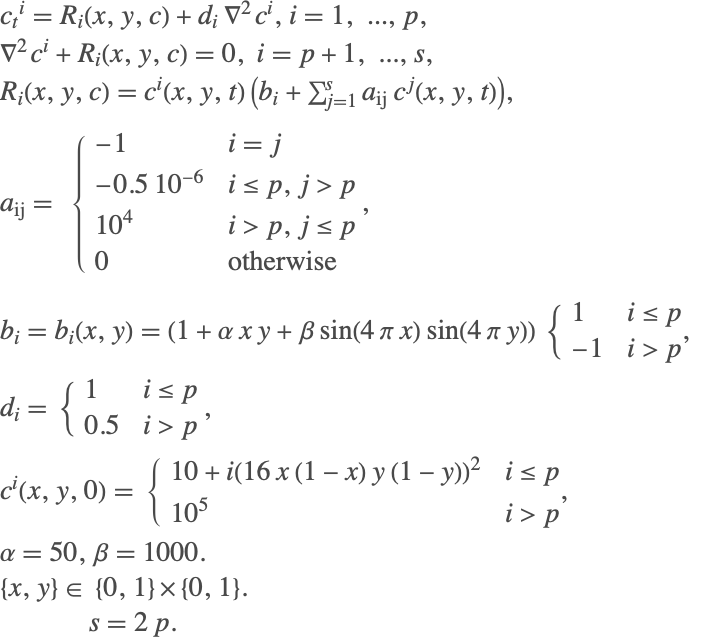
In this system, the first ![]() species are the prey and the next
species are the prey and the next ![]() species are the predators. The specific case of
species are the predators. The specific case of ![]() is considered here. This means that there is one predator and one prey species. The spatial domain is discretized with a 20×20 mesh. This means that there are 2×400 variables in the final DAE system. A uniform distribution of the predators is specified initially. This is leads to a inconsistent initial condition that is corrected by the built-in algorithms.
is considered here. This means that there is one predator and one prey species. The spatial domain is discretized with a 20×20 mesh. This means that there are 2×400 variables in the final DAE system. A uniform distribution of the predators is specified initially. This is leads to a inconsistent initial condition that is corrected by the built-in algorithms.
Clear[p, α, β, a, bv, di, bi, ri, nx, grid, nL, order, x, y, dfdx, dfdy, d2fdx2, d2fdy2, Lapf, species, R, eqns, ics, vars, speciesSol, c];
p = 1; α = 50; β = 1000;
bv = Table[If[i ≤ p, 1, -1], {i, 2p}];
di = Table[If[i ≤ p, 1, 0.5], {i, 2 p}] ;
a = SparseArray[{{i_, i_} -> -1, {i_, j_} /; (i ≤ p && j > p) -> -0.5 10 ^ -6, {i_, j_} /; (i > p && j ≤ p) -> 10 ^ 4}, {2 p, 2 p}] ;
bi[x_, y_] := (1 + α x y + β Sin[4 Pi x] Sin[4 Pi y]) * bv;
ri[{x_, y_}, c_List] := c * (bi[x, y] + a.c);
nx = N@Range[0, 1, 1 / 19];
grid = Flatten[Outer[List, nx, nx], 1];
nL = Length[grid];
order = 2;
{left, right, bot, top} = Flatten[Position[grid, #]]& /@ {{0., y_}, {1., y_}, {x_, 0.}, {x_, 1.}};{dfdx, dfdy, d2fdx2, d2fdy2} = Map[ NDSolve`FiniteDifferenceDerivative[#, {nx, nx}, "DifferenceOrder" -> order]["DifferentiationMatrix"]&, {{1, 0}, {0, 1}, {2, 0}, {0, 2}}];
Lapf = d2fdx2 + d2fdy2;species = Transpose[Table[Array[c[i][#][t]&, nL], {i, 2 p}]];R = Apply[ri, MapThread[List, {grid, species}], 1] ;
eqns = Table[Thread[If[i ≤ p, 1, 0] * D[species[[All, i]], t] == R[[All, i]] + di[[i]] * Lapf.species[[All, i]]], {i, 2 p}];
Do[
eqns[[i]][[left]] = Thread[dfdx[[left]].species[[All, i]] == 0];
eqns[[i]][[right]] = Thread[dfdx[[right]].species[[All, i]] == 0];
eqns[[i]][[bot]] = Thread[dfdy[[bot]].species[[All, i]] == 0];
eqns[[i]][[top]] = Thread[dfdy[[top]].species[[All, i]] == 0];
, {i, 2 p}];ics = Flatten[Table[Thread[(species[[All, i]] /. t -> 0) == If[i ≤ p, 10 + i * (grid /. {x_, y_} :> (16x (1 - x) y (1 - y)) ^ 2), 10 ^ 5]], {i, 2 p}]];vars = Flatten[species] /. x___[t] :> x;
speciesSol = First[NDSolve[{eqns, ics}, vars, {t, 0, 1}]];csol = (species /. t -> 0) /. speciesSol ;
Row[ListPlot3D[Join[grid, csol[[All, {#}]], 2], ImageSize -> 200]& /@ Range[2 p]]speciesRange = {{0, 750}, {0, 7.5 10 ^ 6}};csol = (species /. t -> 0.0001) /. speciesSol ;
Row[Table[ ListPlot3D[Join[grid, csol[[All, {i}]], 2], ImageSize -> 200], {i, 2p}]]csol = (species /. t -> 0.1) /. speciesSol ;
Row[Table[ ListPlot3D[Join[grid, csol[[All, {i}]], 2], ImageSize -> 200, PlotRange -> {{0, 1}, {0, 1}, speciesRange[[i]]}], {i, 2p}]]csol = (species /. t -> 1) /. speciesSol ;
Row[Table[ ListPlot3D[Join[grid, csol[[All, {i}]], 2], ImageSize -> 200, PlotRange -> {{0, 1}, {0, 1}, speciesRange[[i]]}], {i, 2p}]]Andrews's Squeezer Mechanism
The Andrews squeezer mechanism is a multi-body system containing seven different links. The dimensions of the various links and their specifications are given following. The system can be completely defined using seven angles. The angles are labeled q1–q7 in the following system. Additionally, there are six algebraic constraints associated with the link dimensions and connections. This leads to a 14-dimensional, index-3 system. Details of the system can be found in Hairer and Wanner [HW96].

The dimensions associated with the various links are shown below. The seven links are labeled K1–K7.

The notation for the parameters used in the model and their description can be found in Hairer and Wanner [HW96].
Clear[params0, params1, params2, params3, varQ, varL, vars, m, L, force, f, g, r, u, q, i, a, z, Subscript];params0 = {Subscript[x, a] -> -0.06934, Subscript[y, a] -> -0.00227, Subscript[x, b] -> -0.03635, Subscript[y, b] -> 0.03273, Subscript[x, c] -> 0.014, Subscript[y, c] -> 0.072};
params1 = {mom -> 0.033, d -> 0.028, Subscript[e, a] -> 0.01421, Subscript[r, r] -> 0.007, Subscript[s, a] -> 0.01874, Subscript[s, d] -> 0.02, Subscript[t, b] -> 0.00916, Subscript[u, b] -> 0.00449, Subscript[d, a] -> 0.0115, Subscript[z, f] -> 0.02, Subscript[r, a] -> 0.00092, Subscript[s, b] -> 0.01043, Subscript[z, t] -> 0.04, u -> 0.04, Subscript[c, 0] -> 4530, e -> 0.02, Subscript[f, a] -> 0.01421, Subscript[s, s] -> 0.035, Subscript[s, c] -> 0.018, Subscript[t, a] -> 0.02308, Subscript[u, a] -> 0.01228, Subscript[L, 0] -> 0.07785};
params2 = {Subscript[m, 1] -> 0.04325, Subscript[m, 2] -> 0.00365, Subscript[m, 3] -> 0.02373, Subscript[m, 4] -> 0.00706, Subscript[m, 5] -> 0.07050, Subscript[m, 6] -> 0.00706, Subscript[m, 7] -> 0.05498};
params3 = {Subscript[i, 1] -> 2.194 10^-6, Subscript[i, 2] -> 4.410 10^-7, Subscript[i, 3] -> 5.255 10^-6, Subscript[i, 4] -> 5.667 10^-7, Subscript[i, 5] -> 1.169 10^-5, Subscript[i, 6] -> 5.667 10^-7, Subscript[i, 7] -> 1.912 10^-5};
andrewsParams = Join[params0, params1, params2, params3];The motion of the system can be defined using seven angles. The angles are defined as ![]() here. The equations of motion can be derived using Hamiltonian principles resulting in a system of equations of the form
here. The equations of motion can be derived using Hamiltonian principles resulting in a system of equations of the form ![]() where
where ![]() is a mass matrix,
is a mass matrix, ![]() is a vector of forces,
is a vector of forces, ![]() is a vector of constraints, and
is a vector of constraints, and ![]() are Lagrange multipliers.
are Lagrange multipliers.
vQ = {Subscript[q, 1][t], Subscript[q, 2][t], Subscript[q, 3][t], Subscript[q, 4][t], Subscript[q, 5][t], Subscript[q, 6][t], Subscript[q, 7][t]};
vL = {Subscript[λ, 1][t], Subscript[λ, 2][t], Subscript[λ, 3][t], Subscript[λ, 4][t], Subscript[λ, 5][t], Subscript[λ, 6][t]};
vars = Head /@ Join[vQ, vL];M = SparseArray[{
{1, 1} -> Subscript[m, 1] Subscript[r, a]^2 + Subscript[m, 2] (Subscript[r, r]^2 - 2 Subscript[d, a] Subscript[r, r] Cos[Subscript[q, 2][t]] + Subscript[d, a]^2) + Subscript[i, 1] + Subscript[i, 2],
{1, 2} -> Subscript[m, 2](Subscript[d, a]^2 - Subscript[d, a] Subscript[r, r] Cos[Subscript[q, 2][t]]) + Subscript[i, 2],
{2, 1} -> Subscript[m, 2] (Subscript[d, a]^2 - Subscript[d, a] Subscript[r, r] Cos[Subscript[q, 2][t]]) + Subscript[i, 2],
{2, 2} -> Subscript[m, 2] Subscript[d, a]^2 + Subscript[i, 2], {3, 3} -> Subscript[m, 3] (Subscript[s, a]^2 + Subscript[s, b]^2) + Subscript[i, 3], {4, 4} -> Subscript[m, 4] (e - Subscript[e, a])^2 + Subscript[i, 4],
{5, 4} -> Subscript[m, 4] ((e - Subscript[e, a])^2 + Subscript[z, t] (e - Subscript[e, a]) Sin[Subscript[q, 4][t]]) + Subscript[i, 4],
{4, 5} -> Subscript[m, 4] ((e - Subscript[e, a])^2 + Subscript[z, t] (e - Subscript[e, a]) Sin[Subscript[q, 4][t]]) + Subscript[i, 4],
{5, 5} -> Subscript[m, 4](Subscript[z, t]^2 + 2 Subscript[z, t] (e - Subscript[e, a]) Sin[Subscript[q, 4][t]] + (e - Subscript[e, a])^2) + Subscript[m, 5] (Subscript[t, a]^2 + Subscript[t, b]^2) + Subscript[i, 4] + Subscript[i, 5],
{6, 6} -> Subscript[m, 6] (Subscript[z, f] - Subscript[f, a])^2 + Subscript[i, 6], {6, 7} -> Subscript[m, 6] ((Subscript[z, f] - Subscript[f, a])^2 - u (Subscript[z, f] - Subscript[f, a]) Sin[Subscript[q, 6][t]]) + Subscript[i, 6],
{6, 7} -> Subscript[m, 6]((Subscript[z, f] - Subscript[f, a])^2 - u (Subscript[z, f] - Subscript[f, a]) Sin[Subscript[q, 6][t]]) + Subscript[i, 6],
{7, 6} -> Subscript[m, 6] ((Subscript[z, f] - Subscript[f, a])^2 - u (Subscript[z, f] - Subscript[f, a]) Sin[Subscript[q, 6][t]]) + Subscript[i, 6],
{7, 7} -> Subscript[m, 6]((Subscript[z, f] - Subscript[f, a])^2 - 2 u (Subscript[z, f] - Subscript[f, a]) Sin[Subscript[q, 6][t]] + u^2) + Subscript[m, 7] (Subscript[u, a]^2 + Subscript[u, b]^2) + Subscript[i, 6] + Subscript[i, 7]}
];Subscript[x, d] = Subscript[s, d] Cos[Subscript[q, 3][t]] + Subscript[s, c] Sin[Subscript[q, 3][t]] + Subscript[x, b];
Subscript[y, d] = Subscript[s, d] Sin[Subscript[q, 3][t]] - Subscript[s, c] Cos[Subscript[q, 3][t]] + Subscript[y, b];
L = Sqrt[(Subscript[x, d] - Subscript[x, c])^2 + (Subscript[y, d] - Subscript[y, c])^2];
force = -Subscript[c, 0] (L - Subscript[L, 0]) / L;
Subscript[f, x] = force (Subscript[x, d] - Subscript[x, c]);
Subscript[f, y] = force (Subscript[y, d] - Subscript[y, c]);F = (| |
| ----------------------------------------------------------------------- |
| mom - m2 da rr q2'[t] (q2'[t] + 2 q1'[t]) Sin[q2[t]] |
| m2 da rr q1'[t]^2Sin[q2[t]] |
| fx (sc Cos[q3[t]] - sd Sin[q3[t]]) + fy (sd Cos[q3[t]] + sc Sin[q3[t]]) |
| m4 zt (e - ea) q5'[t]^2Cos[q4[t]] |
| -m4 zt (e - ea) q4'[t] (q4'[t] + 2 q5'[t]) Cos[q4[t]] |
| -m6 u (zf - fa) q7'[t]^2Cos[q6[t]] |
| m6 u (zf - fa) q6'[t] (q6'[t] + 2 q7'[t]) Cos[q7[t]] |) //Flatten;g = (| |
| -------------------------------------------------------------------------------- |
| rr Cos[q1[t]] - d Cos[q1[t] + q2[t]] - ss Sin[q3[t]] - xb |
| rr Sin[q1[t]] - d Sin[q1[t] + q2[t]] + ss Cos[q3[t]] - yb |
| rr Cos[q1[t]] - d Cos[q1[t] + q2[t]] - e Sin[q4[t] + q5[t]] - zt Cos[q5[t]] - xa |
| rr Sin[q1[t]] - d Sin[q1[t] + q2[t]] + e Cos[q4[t] + q5[t]] - zt Sin[q5[t]] - ya |
| rr Cos[q1[t]] - d Cos[q1[t] + q2[t]] - zf Cos[q6[t] + q7[t]] - u Sin[q7[t]] - xa |
| rr Sin[q1[t]] - d Sin[q1[t] + q2[t]] - zf Sin[q6[t] + q7[t]] + u Cos[q7[t]] - ya |)//Flatten;eqns = Thread /@ {M.D[vQ, {t, 2}] == F - Transpose[D[g, {vQ}]].vL , g == 0} /. andrewsParams;ics = Thread /@ {vQ == {-0.06171389001427, 0, 0.4552798191630704, 0.22266839016588588, 0.4873649795438425, -0.222668390165, 1.2305474445498212}, D[vQ, t] == 0} /. t -> 0;solAndrews = First@NDSolve[{eqns, ics}, vars, {t, 0, 0.05}, Method -> {"IndexReduction" -> {Automatic, "ConstraintMethod" -> None}, "EquationSimplification" -> "Residual"}, MaxSteps -> ∞];Plot[Evaluate[Mod[vQ /. solAndrews, 2 Pi, -Pi]], {t, 0, 0.05}, ImageSize -> Medium, Frame -> True, FrameLabel -> {"Time (t)", "Angles (q)"},
PlotRange -> {Automatic, {-0.7, 1.5}}, PlotStyle -> {{Dotted, StandardBrown}, {Dotted, StandardGreen}, {Thick, StandardBlue}, {Thick, StandardBrown}, {Thick, LightRed}, {Thick, StandardMagenta}, {Thick, StandardOrange}}, PlotLegends -> (Style[#, 14]& /@ (vQ /. x___[t_] :> x))]Plot[Evaluate[F /. andrewsParams /. solAndrews], {t, 0, 0.05}, ImageSize -> Medium, Frame -> True, FrameLabel -> {"Time (t)", "Forces (SubscriptBox[F, i])"},
PlotRange -> {Automatic, {-0.2, 0.2}},
PlotStyle -> {{Dotted, StandardBrown}, {Dotted, StandardGreen}, {Thick, StandardBlue}, {Thick, StandardBrown}, {Thick, LightRed}, {Thick, StandardMagenta}, {Thick, StandardOrange}}, PlotLegends -> (Style[StringForm["SubscriptBox[K, `1`]", #], 14]& /@ Range[7])]Animate[
p1 = {Subscript[r, r] Cos[Subscript[q, 1][tt]], Subscript[r, r] Sin[Subscript[q, 1][tt]]};
p2 = {Subscript[r, r] Cos[Subscript[q, 1][tt]] - d Cos[Subscript[q, 1][tt] + Subscript[q, 2][tt]], Subscript[r, r]Sin[Subscript[q, 1][tt]] - d Sin[Subscript[q, 1][tt] + Subscript[q, 2][tt]]};
p3 = {Subscript[x, b] + Subscript[s, c] Sin[Subscript[q, 3][tt]] + Subscript[s, d] Cos[Subscript[q, 3][tt]], Subscript[y, b] - Subscript[s, c] Cos[Subscript[q, 3][tt]] + Subscript[s, d] Sin[Subscript[q, 3][tt]]};
p3c = {Subscript[x, b] + Subscript[s, a] Sin[Subscript[q, 3][tt]] + Subscript[s, b] Cos[Subscript[q, 3][tt]], Subscript[y, b] - Subscript[s, a] Cos[Subscript[q, 3][tt]] + Subscript[s, b] Sin[Subscript[q, 3][tt]]};
p4 = {Subscript[x, a] + Subscript[z, t]Cos[Subscript[q, 5][tt]], Subscript[y, a] + Subscript[z, t] Sin[Subscript[q, 5][tt]]};
p5 = {Subscript[x, a] + Subscript[t, a] Cos[Subscript[q, 5][tt]] - Subscript[t, b] Sin[Subscript[q, 5][tt]], Subscript[y, a] + Subscript[t, a] Sin[Subscript[q, 5][tt]] + Subscript[t, b] Cos[Subscript[q, 5][tt]]};
p6 = {Subscript[x, a] + u Sin[Subscript[q, 7][tt]], Subscript[y, a] - u Cos[Subscript[q, 7][tt]]};
p7 = {Subscript[x, a] + Subscript[u, a] Sin[Subscript[q, 7][tt]] - Subscript[u, b] Cos[Subscript[q, 7][tt]], Subscript[y, a] - Subscript[u, a] Cos[Subscript[q, 7][tt]] - Subscript[u, b] Sin[Subscript[q, 7][tt]]};
link1 = {Thickness[0.05], LightDarkSwitched[Black, White], CapForm["Round"], Line[{{0, 0}, p1}]} ;
link2 = {Thickness[0.05], Green, EdgeForm[LightDarkSwitched[Black, White]], CapForm["Round"], Line[{p1, p2}]} ;
link3 = {Thickness[0.05], Blue, CapForm["Round"], Line[{p2, p3c}], Line[{{Subscript[x, b], Subscript[y, b]}, p3c}], Line[{p3c, p3}]} ;
link4 = {Thickness[0.05], Brown, CapForm["Round"], Line[{p2, p4}]};
link5 = {Thickness[0.05], LightRed, CapForm["Round"], Line[{p2, p6}]};
link6 = {Thickness[0.05], Magenta, CapForm["Round"], Line[{{Subscript[x, a], Subscript[y, a]}, p5}], Line[{p5, p4}]} ;
link7 = {Thickness[0.05], Orange, CapForm["Round"], Line[{{Subscript[x, a], Subscript[y, a]}, p7}], Line[{p7, p6}]} ;
spring = {Thickness[0.02], Purple, CapForm["Round"], Line[{p3, {Subscript[x, c], Subscript[y, c]}}]};
disk0 = {White, EdgeForm[{LightDarkSwitched[Black, White], Thick}], Disk[{0, 0}, 0.0017]};
disk1 = {White, EdgeForm[{LightDarkSwitched[Black, White], Thick}], Disk[p1, 0.0017]};
disk2 = {White, EdgeForm[{LightDarkSwitched[Black, White], Thick}], Disk[{Subscript[x, b], Subscript[y, b]}, 0.0017]} ;
disk3 = {White, EdgeForm[{LightDarkSwitched[Black, White], Thick}], Disk[p2, 0.0017]} ;
disk4 = {White, EdgeForm[{LightDarkSwitched[Black, White], Thick}], Disk[p4, 0.0017]};
disk5 = {White, EdgeForm[{LightDarkSwitched[Black, White], Thick}], Disk[p3, 0.001]};
disk6 = {White, EdgeForm[{LightDarkSwitched[Black, White], Thick}], Disk[p6, 0.0017]};
disk7 = {White, EdgeForm[{LightDarkSwitched[Black, White], Thick}], Disk[{Subscript[x, a], Subscript[y, a]}, 0.0017]};
Graphics[{link1, disk0, link2, link3, link4, link5, link6, link7, spring, disk1, disk2, disk3, disk4, disk6, disk7, disk5} /. andrewsParams /. solAndrews,
PlotRange -> {{-0.09, 0.02}, {-0.03, 0.08}}, Frame -> True, ImageSize -> 400]
, {tt, 0.008, 0.0276}, AnimationRunning -> False, SaveDefinitions -> True]