"SupportVectorMachine" (机器学习方法)
- 是 Classify 的方法.
- 通过使用最大间隔超平面找到将训练数据分成两个类的超平面来模拟类的概率.
详细信息与子选项
- 支持向量机是二元分类器. 用内核函数从实例中提取特征. 在训练时,该方法可找到分隔不同类的最大间隔超平面. 多类分类问题被简化为二元分类问题(使用一对一或一对多方法). 目前是在后端使用 LibSVM 框架来实现.
- 选项 "KernelType" 允许你选择内核的类型. "KernelType" 的可能设置包括:
-
"RadialBasisFunction" 用指数径向基核函数作为内核 "Polynomial" 用多项式函数作为内核 "Sigmoid" 用 sigmoidal 函数作为内核 "Linear" 用线性函数作为内核 - 内核 "RadialBasisFunction" 的格式如下:
- 内核 "Polynomial" 的格式如下:
- 内核 "Sigmoid" 的格式如下:
- 内核 "Linear" 的格式如下:
- 可以给出下列选项:
-
"BiasParameter" 1 bias term c in polynomial and sigmoid kernels "GammaScalingParameter" Automatic 前一个内核中的参数 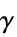
"KernelType" "RadialBasisFunction" 用于映射到更高维空间的内核 "MulticlassStrategy" Automatic 用于获取多类分类器的方法 "PolynomialDegree" 3 多项式内核中l多项式 d 的次数 - "MulticlassStrategy" 的可能设置包括:
-
"OneVersusOne" 为每对类别训练一个二元分类器 "OneVersusAll" 为每个类别训练一个二元分类器 - "GammaScalingParameter" 控制支持向量的影响. 较大的伽玛值意味着较小的影响半径.
- "PolynomialDegree" 选项是多项式内核专有的.
- "MulticlassStrategy" 选项用于将二元分类器推广到多类分类器. "OneVersusOne" 策略对每个类别互相进行测试,而 "OneVersusAll" 策略只将每个类别与训练集中剩下的类别进行测试.