

ClassifierMeasurements
ClassifierMeasurements[classifier,testset,prop]
gives measurements associated with property prop when classifier is evaluated on testset.
ClassifierMeasurements[classifier,testset]
yields a measurement report that can be applied to any property.
ClassifierMeasurements[data,…]
uses classifications data instead of a classifier.
ClassifierMeasurements[…,{prop1,prop2,…}]
gives properties prop1, prop2, etc.
Details and Options
- Measurements are used to determine the performance of a classifier on data that was not used for training purposes (the test set).
- Possible measurements include classification metrics (accuracy, likelihood, etc.), visualizations (confusion matrix, ROC curve, etc.) or specific examples (such as the worst classified examples).
- Classifiers can be a ClassifierFunction or a neural net (NetGraph, NetChain, etc.) that has a "Class" decoder.
- In ClassifierMeasurements[data,…], the classifications data can have the following forms:
-
{class1,class2,…} classifications from a classifier (human, algorithm, etc.) {dist1,dist2,…} class distributions obtained by a classifier {<class1p1,…>,<class1q1,…>,…} classification probabilities obtained by a classifier - ClassifierMeasurements[…,opts] specifies that the classifier should use the options opts when applied to the test set. Possible options are as given in ClassifierFunction.
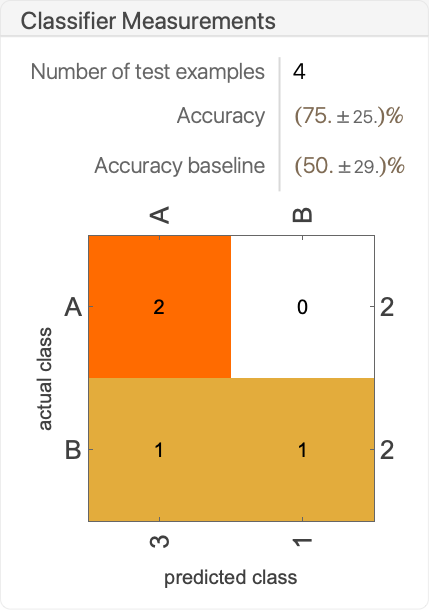
- ClassifierMeasurements[classifier,testset] returns a ClassifierMeasurementsObject[…] that displays as a report panel, such as:
- ClassifierMeasurementsObject[…][prop] can be used to obtain the property prop. When repeated property lookups are required, this is typically more efficient than using ClassifierMeasurements every time.
- ClassifierMeasurementsObject[…][prop,opts] specifies that the classifier should use the options opts when applied to the test set. These options supersede original options given to ClassifierMeasurements.
- ClassifierMeasurements has the same options as ClassifierFunction[…], with the following additions:
-
Weights Automatic weights to be associated with test set examples ComputeUncertainty False whether measures should be given with their statistical uncertainty - When ComputeUncertaintyTrue, numerical measures will be returned as Around[result,err] where err represents the standard error (corresponding to a 68% confidence interval) associated with measure result.
- Possible settings for Weights include:
-
Automatic associates weight 1 with all test examples {w1,w2,…} associates weight wi with the i ") test examples
test examples - Changing the weight of a test example from 1 to 2 is equivalent to duplicating the example.
- Weights affect measures as well as their uncertainties.
- Properties returning a single numeric value related to classification abilities on the test set include:
-
"Accuracy" fraction of correctly classified examples "Accuracy"n top-n accuracy "AccuracyBaseline" accuracy if predicting the commonest class "CohenKappa" Cohen's kappa coefficient "Error" fraction of incorrectly classified examples "GeometricMeanProbability" geometric mean of the actual-class probabilities "LogLikelihood" log-likelihood of the model given the test set "MeanCrossEntropy" mean cross entropy over test examples "MeanDecisionUtility" mean utility over test example "Perplexity" exponential of the mean cross entropy "RejectionRate" fraction of examples classified as Indeterminate "ScottPi" Scott's pi coefficient - Examples classified as Indeterminate are discarded when measuring properties related to classification abilities on the test set, such as "Accuracy", "Error", or "MeanCrossEntropy".
- Confusion matrix–related properties include:
-
"ConfusionMatrix" counts cij of class i examples classified as class j "ConfusionMatrixPlot" plot of the confusion matrix "ConfusionMatrixPlot"{c1,c2,…} confusion matrix plot restricted to classes c1, c2, etc. "ConfusionMatrixPlot"n confusion matrix plot for the worst n-class subset "ConfusionFunction" function giving confusion matrix values "TopConfusions" pairs of classes that are most confused "TopConfusions"n n most confused class pairs - Timing-related properties include:
-
"EvaluationTime" time needed to classify one example of the test set "BatchEvaluationTime" marginal time to classify one example in a batch - Properties returning one value for each test-set example include:
-
"DecisionUtilities" value of the utility function for each example "Probabilities" actual-class classification probabilities for each example "SHAPValues" Shapley additive feature explanations for each example - "SHAPValues" assesses the contribution of features by comparing predictions with different sets of features removed and then synthesized. The option MissingValueSynthesis can be used to specify how the missing features are synthesized. SHAP explanations are given as odds ratio multipliers with respect to the class training prior. "SHAPValues"n can be used to control the number of samples used for the numeric estimations of SHAP explanations.
- Properties related to probability calibration include:
-
"CalibrationCurve" probability calibration curve in logit scale "LinearCalibrationCurve" probability calibration curve in linear scale "CalibrationData" probability calibration curve data - Properties returning graphics include:
-
"AccuracyRejectionPlot" plot of the accuracy as function of the rejection rate "ICEPlots" Individual Conditional Expectation (ICE) plots "ProbabilityHistogram" histogram of actual-class probabilities "Report" panel reporting main measurements "ROCCurve" Receiver Operating Characteristics curve for each class "SHAPPlots" Shapley additive feature explanations plot for each class - Properties returning examples from the test set include:
-
"Examples" all test examples "Examples"{i,j} all class i examples classified as class j "BestClassifiedExamples" examples having the highest actual-class probability "WorstClassifiedExamples" examples having the lowest actual-class probability "CorrectlyClassifiedExamples" examples correctly classified "MisclassifiedExamples" examples misclassified "TruePositiveExamples" true positive test examples for each class "FalsePositiveExamples" false positive test examples for each class "TrueNegativeExamples" true negative test examples for each class "FalseNegativeExamples" false negative test examples for each class "IndeterminateExamples" test examples classified as Indeterminate "LeastCertainExamples" examples having the highest distribution entropy "MostCertainExamples" examples having the lowest distribution entropy - Examples are given in the form inputiclassi, where classi is the actual class from the test set.
- Properties such as "WorstClassifiedExamples" or "MostCertainExamples" output up to 10 examples. ClassifierMeasurementsObject[…][propn] can be used to output n examples.
- Properties returning one measure for each class include:
-
"AreaUnderROCCurve" area under the ROC curve for each class "ClassMeanCrossEntropy" mean cross entropy for each class "ClassRejectionRate" rejection rate for each class "F1Score" F1 score for each class "FalseDiscoveryRate" false discovery rate for each class "FalseNegativeRate" false negative rate for each class "FalsePositiveRate" false positive rate for each class "MatthewsCorrelationCoefficient" Matthews correlation coefficient for each class "NegativePredictiveValue" negative predictive value for each class "Precision" precision of classification for each class "Recall" recall rate of classification for each class "Specificity" specificity for each class "TruePositiveNumber" number of true positive examples "FalsePositiveNumber" number of false positive examples "TrueNegativeNumber" number of true negative examples "FalseNegativeNumber" number of false negative examples - ClassifierMeasurementsObject[…][propclass] can be used to only return the measure associated with the specified class.
- ClassifierMeasurementsObject[…][prop<class1w1,class2w2,…>] can be used to return a weighted average of each class measure.
- ClassifierMeasurementsObject[…][propf] can be used to apply function f to the returned class measures (e.g. ClassifierMeasurementsObject[…][propMean]).
- Properties such as "Precision" or "Recall" give one measure for each possible "positive class". The "negative class" is the union of all the classes that are not the positive class. For such properties, one can average the measures for all possible positive classes using ClassifierMeasurementsObject[…][propaverage], where average can be:
-
"MacroAverage" takes the mean of the measures "WeightedMacroAverage" weights each measure by its related class frequency "MicroAverage" joins true positive/true negative etc. examples of all classes to give a unique measure - Other properties include:
-
"ClassifierFunction" ClassifierFunction[…] being measured "Properties" list of measurement properties available
Examples
open all close allBasic Examples (4)
Measure the accuracy of a ClassifierFunction on a test set:
ClassifierMeasurements[ClassifierFunction[Association["ExampleNumber" -> 6, "ClassNumber" -> 2,
"Input" -> Association["Preprocessor" -> MachineLearning`MLProcessor["ToMLDataset",
Association["Input" -> Association["f1" -> Association["Type" -> "Numerical"]],
... -> DateObject[{2025, 11, 6, 16, 12,
52.1822776`9.470097878158642}, "Instant", "Gregorian", -6.], "ProcessorCount" -> 4,
"ProcessorType" -> "x86-64", "OperatingSystem" -> "Windows", "SystemWordLength" -> 64,
"Evaluations" -> {}]]], {2.2 -> "A", 2.7 -> "A", 4.5 -> "B", 1.4 -> "B"}, "Accuracy"]Train a classifier on a training set:
c = Classify[{1 -> "A", 2 -> "A", 3.5 -> "B", 4 -> "A", 5 -> "B", 6 -> "B"}]Generate a measurement object of the classifier on a test set:
cm = ClassifierMeasurements[c, {2.2 -> "A", 2.7 -> "A", 4.5 -> "B", 1.4 -> "B"}]Measure the mean cross-entropy from classification probabilities:
ClassifierMeasurements[{<|"A" -> 0.9, "B" -> 0.1|>, <|"A" -> 0.8, "B" -> 0.2|>, <|"A" -> 0.2, "B" -> 0.8|>, <|"A" -> 0.6, "B" -> 0.4|>}, {"A", "A", "B", "B"}, "MeanCrossEntropy"]Visualize the confusion matrix of a neural network classifier:
ClassifierMeasurements[NetChain[Association["Type" -> "Chain",
"Nodes" -> Association["1" -> Association["Type" -> "Linear",
"Arrays" -> Association["Weights" -> NumericArray[{{-0.36878493428230286},
{0.7268890738487244}}, "Real32"], "Biases" -> Nume ... ls" -> {"A", "B"},
"InputDepth" -> 1, "Multilabel" -> False, "Dimensions" -> 2, "$Rank" -> 0,
"$Version" -> "15.0.1"], NeuralNetworks`TensorT[{2}, NeuralNetworks`RealT]]]],
Association["Version" -> "15.0.1", "Unstable" -> False]], {2.2 -> "A", 2.7 -> "A", 4.5 -> "B", 1.4 -> "B"}, "ConfusionMatrixPlot"]Scope (7)
Decision Metrics (3)
Measure the accuracy of classified examples against their true labels:
ClassifierMeasurements[{"A", "A", "B", "A", "B"}, {"A", "A", "B", "B", "B"}, "Accuracy"]Obtain the statistical uncertainty on this measure:
ClassifierMeasurements[{"A", "A", "B", "A", "B"}, {"A", "A", "B", "B", "B"}, "Accuracy", ComputeUncertainty -> True]Compare the accuracy to a baseline (always predicting the most likely test-set class, "B" in this case):
ClassifierMeasurements[{"A", "A", "B", "A", "B"}, {"A", "A", "B", "B", "B"}, "AccuracyBaseline", ComputeUncertainty -> True]Measure the error on the same data:
ClassifierMeasurements[{"A", "A", "B", "A", "B"}, {"A", "A", "B", "B", "B"}, "Error"]Check that error and accuracy sum to 1:
Total@ClassifierMeasurements[{"A", "A", "B", "A", "B"}, {"A", "A", "B", "B", "B"}, {"Accuracy", "Error"}]Measure the accuracy using a higher weight for the last two examples:
ClassifierMeasurements[{"A", "A", "B", "A", "B"}, {"A", "A", "B", "B", "B"}, "Accuracy", Weights -> {1, 1, 1, 2, 2}]Create a training set and a test set on MNIST data:
{training, test} = TakeDrop[RandomSample[ResourceData["MNIST"], 2000], 1000];training//ShortTrain a model on the training set:
c = Classify[training]Compute the accuracy of the model on the test set:
ClassifierMeasurements[c, test, "Accuracy", ComputeUncertainty -> True]Compute the "top-3" accuracy of the model on the test set (classification is considered correct if the true class is among the three predicted classes with the highest probabilities):
ClassifierMeasurements[c, test, "Accuracy" -> 3, ComputeUncertainty -> True]Measure Cohen's kappa coefficient on classified examples against their true labels:
ClassifierMeasurements[{"A", "A", "B", "A"}, {"A", "A", "B", "B"}, "CohenKappa"]Measure Scott's pi on the same data:
ClassifierMeasurements[{"A", "A", "B", "A"}, {"A", "A", "B", "B"}, "ScottPi"]Confusion Matrix & Example Extraction (1)
Create a training set and a test set on MNIST data:
{training, test} = TakeDrop[RandomSample[ResourceData["MNIST"], 2000], 1000];training//ShortTrain a model on the training set:
c = Classify[training]Create a classifier measurements object for this classifier on the test set:
cm = ClassifierMeasurements[c, test]Find the 10 test examples that have the worst classification (lowest probabiity for the correct class):
cm["WorstClassifiedExamples" -> 10]Compute their correct-class probability:
#1 -> c[#1, "Probability" -> #2]&@@@cm["WorstClassifiedExamples" -> 10]Find the 10 test examples that have the best classification:
cm["BestClassifiedExamples" -> 10]Compute their correct-class probability:
#1 -> c[#1, "Probability" -> #2]&@@@cm["BestClassifiedExamples" -> 10]Visualize the confusion matrix:
cm["ConfusionMatrixPlot"]cm["ConfusionMatrix"]Extract the number of test examples of "3" classified as a "5":
cm["ConfusionFunction"][3, 5]Find the 5 most frequent class confusions:
cm["TopConfusions" -> 5]Restrict the confusion matrix to the set of 3 classes that are the most confused with each other:
cm["ConfusionMatrixPlot" -> 3]Restrict the confusion matrix to the set of 3 classes that are the least confused with each other:
cm["ConfusionMatrixPlot" -> -3]Restrict the confusion matrix to classes "1", "4" and "9":
cm["ConfusionMatrixPlot" -> {1, 4, 9}]Extract the examples of "4" that are confused with a "9":
cm["Examples" -> {4, 9}]Probabilistic Metrics (1)
Load the Fisher's Irises dataset:
fisher = ResourceData["Sample Data: Fisher's Irises"]//Dataset[#, MaxItems -> 5]&Create a training set and a test set:
{training, test} = TakeDrop[RandomSample[fisher], 100];Train a classifier to recognize the iris species from their attributes:
iris = Classify[training -> "Species"]Measure the log-likelihood of the test set (total log-probabilities of correct classes):
ClassifierMeasurements[iris, test, "LogLikelihood"]Measure the mean cross-entropy:
ClassifierMeasurements[iris, test, "MeanCrossEntropy"]The mean cross-entropy is the average negative log-likelihood:
-ClassifierMeasurements[iris, test, "LogLikelihood"] / Length[test]Measure the geometric mean of the probabilities for the correct class:
ClassifierMeasurements[iris, test, "GeometricMeanProbability"]This geometric mean is related to the mean cross-entropy:
Exp[-ClassifierMeasurements[iris, test, "MeanCrossEntropy"]]Probability Calibration (1)
Create a training set and a test set on MNIST data:
{training, test} = TakeDrop[RandomSample[ResourceData["MNIST"], 8000], 4000];Train a random forest classifier for which the probability calibration is deactivated:
c1 = Classify[training, Method -> "RandomForest", RecalibrationFunction -> None]Visualize the reliability diagram (a.k.a calibration curve) of the classifier on the test set in a logit scale:
ClassifierMeasurements[c1, test, "CalibrationCurve"]Visualize the same reliability diagram using a linear scaling:
ClassifierMeasurements[c1, test, "LinearCalibrationCurve"]Train a classifier where the calibration is activated:
c2 = Classify[training, Method -> "RandomForest"]Visualize its reliability diagram in logit scale:
ClassifierMeasurements[c2, test, "CalibrationCurve"]Visualize its reliability diagram in linear scale:
ClassifierMeasurements[c2, test, "LinearCalibrationCurve"]Binary-Classification Metrics (1)
Load the Fisher's Irises dataset:
fisher = ResourceData["Sample Data: Fisher's Irises"]//Dataset[#, MaxItems -> 5]&Create a training set and a test set:
{training, test} = TakeDrop[RandomSample[fisher], 100];Train a classifier to recognize the iris species from their attributes:
iris = Classify[training -> "Species"]Compute a ROC curve for each possible "positive" class:
ClassifierMeasurements[iris, test, "ROCCurve"]Compute the area under these curves:
ClassifierMeasurements[iris, test, "AreaUnderROCCurve"]Measure the F1 score for each possible "positive" class:
ClassifierMeasurements[iris, test, "F1Score"]Measure the F1 score if versicolor is the "positive" class:
ClassifierMeasurements[iris, test, "F1Score" -> "versicolor"]Take the mean of all F1 scores:
ClassifierMeasurements[iris, test, "ClassAccuracy" -> "MacroAverage"]Weight each score according to the class prior:
ClassifierMeasurements[iris, test, "ClassAccuracy" -> "WeightedMacroAverage"]Compute F1 scores by joining true positive/true negative, etc. examples of all classes to give a unique measure:
ClassifierMeasurements[iris, test, "ClassAccuracy" -> "MicroAverage"]Options (6)
ClassPriors (1)
Load the training set and test set of the "Satellite" dataset:
trainingset = ExampleData[{"MachineLearning", "Satellite"}, "TrainingData"];testset = ExampleData[{"MachineLearning", "Satellite"}, "TestData"];Train a classifier on the training set:
c = Classify[trainingset]Train a classifier on the training set:
ClassifierMeasurements[c, testset, "ConfusionMatrixPlot"]Visualize the confusion matrix obtained when the classifier has a different value of ClassPriors:
ClassifierMeasurements[c, testset, "ConfusionMatrixPlot", ClassPriors -> <|"cotton crop" -> 0.5, "gray soil" -> 0.5|>]Perform the same operation by first generating a ClassifierMeasurementsObject:
cm = ClassifierMeasurements[c, testset];cm["ConfusionMatrixPlot", ClassPriors -> <|"cotton crop" -> 0.5, "gray soil" -> 0.5|>]IndeterminateThreshold (1)
Load the training set and test set of the "Titanic" dataset:
trainingset = ExampleData[{"MachineLearning", "Titanic"}, "TrainingData"];testset = ExampleData[{"MachineLearning", "Titanic"}, "TestData"];Train a classifier on the training set:
c = Classify[trainingset, Method -> "LogisticRegression"]Visualize the confusion matrix of the classifier on the test set:
ClassifierMeasurements[c, testset, "ConfusionMatrixPlot"]Visualize the confusion matrix obtained when the classifier has a different value of IndeterminateThreshold:
ClassifierMeasurements[c, testset, "ConfusionMatrixPlot", IndeterminateThreshold -> 0.8]Measure the accuracy of the classifier on the test set for different values of IndeterminateThreshold:
cm = ClassifierMeasurements[c, testset]cm["Accuracy", IndeterminateThreshold -> #] & /@ {0., 0.6, 0.8, 0.9}Visualize the accuracy-versus-rejection curve:
cm["AccuracyRejectionPlot"]TargetDevice (1)
Train a classifier using a neural network:
trainingData = RandomReal[1, {2000, 4}] -> RandomChoice[{"a", "b", "c", "d"}, 2000];
classifier = Classify[trainingData, Method -> "NeuralNetwork"]Measure the accuracy of the classifier on a test set for different setting of TargetDevice:
testset = RandomReal[1, {10, 4}] -> RandomChoice[{"a", "b", "c", "d"}, 10];AbsoluteTiming[ClassifierMeasurements[classifier, testset, "Accuracy", TargetDevice -> "GPU"]]AbsoluteTiming[ClassifierMeasurements[classifier, testset, "Accuracy", TargetDevice -> "CPU"]]UtilityFunction (1)
Load the training set and test set of the "Mushroom" dataset:
trainingset = ExampleData[{"MachineLearning", "Mushroom"}, "TrainingData"];testset = ExampleData[{"MachineLearning", "Mushroom"}, "TestData"];Train a classifier on a part of the training set:
c = Classify[RandomSample[trainingset, 100]]Visualize the confusion matrix of the classifier on the test set:
ClassifierMeasurements[c, testset, "ConfusionMatrixPlot"]Visualize the confusion matrix obtained when the classifier has a different value of UtilityFunction:
utility = <|
"edible" -> <|"edible" -> 1, "poisonous" -> 0, Indeterminate -> 0.5|>,
"poisonous" -> <|"edible" -> -10, "poisonous" -> 1, Indeterminate -> 0.8|>
|>;ClassifierMeasurements[c, testset, "ConfusionMatrixPlot", UtilityFunction -> utility]Perform the same operation by first generating a ClassifierMeasurementsObject:
cm = ClassifierMeasurements[c, testset]cm["ConfusionMatrixPlot", UtilityFunction -> utility]ComputeUncertainty (1)
Train a classifier that classifies movie review snippets as "positive" or "negative":
training = ExampleData[{"MachineLearning", "MovieReview"}, "TrainingData"];c = Classify[ExampleData[{"MachineLearning", "MovieReview"}, "TrainingData"]]Generate a ClassifierMeasurements[…] object using a test set:
test = ExampleData[{"MachineLearning", "MovieReview"}, "TestData"];cm = ClassifierMeasurements[c, test]Obtain a measure of the accuracy along with its uncertainty:
cm["Accuracy", ComputeUncertainty -> True]Obtain a measure of other properties along with their uncertainties:
Dataset[AssociationMap[cm[#, ComputeUncertainty -> True]&, {"AreaUnderROCCurve" -> "positive", "CohenKappa", "Error", "F1Score" -> "positive", "GeometricMeanProbability", "MatthewsCorrelationCoefficient" -> "positive", "MeanCrossEntropy", "Precision" -> "positive", "Recall" -> "positive", "ScottPi"}]]Weights (1)
Create a classifier on a training set:
c = Classify[{1 -> "A", 2 -> "A", 3.5 -> "B", 4 -> "A", 5 -> "B", 6 -> "B"}]Generate a measurement object while specifying the weights that each test example has:
cm = ClassifierMeasurements[c, {2.2 -> "A", 2.7 -> "A", 4.5 -> "B", 1.4 -> "B"}, Weights -> {1.5, 3, 2, 1}]cm["Accuracy"]Weights can also be modified when using the measurement object:
cm["Accuracy", Weights -> {1, 1, 1, 3}]Uncertainties are also affected by weights:
cm["Accuracy", ComputeUncertainty -> True]cm["Accuracy", Weights -> {1, 1, 1, 3}, ComputeUncertainty -> True]Applications (2)
Train a classifier on the Fisher Iris dataset to predict the species of Iris (setosa, versicolor, virginica) from four measured features:
c = Classify[ExampleData[{"MachineLearning", "FisherIris"}, "TrainingData"]]Measure the accuracy of the classifier on a test set:
cm = ClassifierMeasurements[c, ExampleData[{"MachineLearning", "FisherIris"}, "TestData"]]cm["Accuracy"]Generate a confusion matrix to visualize the actual and predicted classifications of the test set using the classifier:
cm["ConfusionMatrixPlot"]Extract examples of class "versicolor" being misclassified as "virginica":
cm["Examples" -> {"versicolor", "virginica"}]Return the confusion matrix as a set of associations:
cm["ConfusionFunction"]Train a classifier on a sample of the MNIST dataset:
{training, test} = TakeDrop[RandomSample[ResourceData["MNIST"], 8000], 4000];c = Classify[training]Generate a ClassifierMeasurementsObject of the classifier on the MNIST test set:
cm = ClassifierMeasurements[c, ExampleData[{"MachineLearning", "MNIST"}, "TestData"]]Extract examples of 9 confused with 0:
cm["Examples" -> {9, 0}]Extract the 20 worst classified examples:
cm["WorstClassifiedExamples" -> 20]Compute the F-score of each class to find for which class the classifier should be improved:
cm["F1Score"]Find the minimal value for the rejection threshold in order for the accuracy to be above 95%:
cm["AccuracyRejectionPlot"]Visualize the confusion matrix and compute the F-scores with this rejection threshold:
cm["ConfusionMatrixPlot", IndeterminateThreshold -> 0.15]cm["F1Score", IndeterminateThreshold -> 0.67]Visualize the 3 most confused classes:
cm["ConfusionMatrixPlot" -> 3, IndeterminateThreshold -> 0.67]Text
Wolfram Research (2014), ClassifierMeasurements, Wolfram Language function, https://reference.wolfram.com/language/ref/ClassifierMeasurements.html (updated 2021).
CMS
Wolfram Language. 2014. "ClassifierMeasurements." Wolfram Language & System Documentation Center. Wolfram Research. Last Modified 2021. https://reference.wolfram.com/language/ref/ClassifierMeasurements.html.
APA
Wolfram Language. (2014). ClassifierMeasurements. Wolfram Language & System Documentation Center. Retrieved from https://reference.wolfram.com/language/ref/ClassifierMeasurements.html