变换规则和定义
变换规则和定义
当使用一系列循环规则时,//. 能一直得到不同的结果. 在实际操作中,对一个特定表达式 //. 所能进行的最大循环次数取决于选项的设置. 用可选项 MaxIterations 可以确定对一个表达式的迭代次数. 当需要一直替换下去时,可以用 ReplaceRepeated[expr,rules,MaxIterations->Infinity] 来实现. 通过中断 Wolfram 语言总可以停止迭代.
没有指定层时,Replace 仅将规则用于整个表达式:
| expr/.rules | 将规则运用于表达式 expr 的子项 |
| Replace[expr,rules] | 仅将规则运用于整个表达式 expr |
| Replace[expr,rules,levspec] | 将规则用到由 levspec 指定层表达式 expr 的项上 |
Replace 给出使用第一个规则后的结果:
ReplaceList 给出一列规则使用后的结果:
当一个规则有多种使用方式时,ReplaceList 给出所有的结果:
| Replace[expr,rules] | 仅以一种方式用 rules |
| ReplaceList[expr,rules] | 以所有可能的方式使用 rules |
Wolfram 语言为了提高 /. 的运行速度,可以先对一组规则进行处理,其方法是让 Dispatch 作用在这组规则上. Dispatch 函数作用的结果还是这一组规则,但它产生了一个分派表. 该分派表使 /. 不再逐个测试每个规则,而立即转到可使用的规则上去.
| Dispatch[rules] | 产生一列具有分派表的规则 |
| expr/.drules | 产生有分派表的规则 |
对于较长的规则列表,用了分派表之后可以使一列规则的替换运行得很快,当这些规则不是模式,而是一些单个符号或表达式时更显示出优势,用了分派表时就会发现 /. 操作符所花的时间几乎与规则的数量无关,而没有分派表时,/. 所花的时间与规则的数量成比例.
另外一种避免这一错误的途径是对常用或简单的变量名赋值时要仔细考虑. 例如,经常使用变量名 x 作为符号参数. 但是如果用 x=3 赋值后,以后出现的 x 都用 3 代替,且以后也再不能将 x 当作一个符号参数使用.
一般来说,不要对有几种用途的变量赋值. 例如,若在某处用 c 变量表示光速 3.*10^8. 则以后就不能将 c 用作一个待定参数. 避免这种情况的一种途径是对光速用更加明确的变量名,如 SpeedOfLight.
| x=. | 清除对 x 的赋值 |
| Clear[x,y,…] | 清除变量 x,y,… 的所有值 |
AppendTo[v,elem] 是与 v=Append[v,elem] 等价的. 由于 Wolfram 系统中集合的存储方式,建立像每层长度为2的集合所组成的嵌套结构比增添一列元素更有效,当建立了这种嵌套结构后就可以用 Flatten 将其简化为一维列表.
用 Flatten 取消这种结构:
在多种计算中,需要建立包含一列带标号的表达式的阵列. 在 Wolfram 语言中得到阵列的一种途径是定义列表. 你可以定义一个列表,如 a={x,y,z,…},然后就可以用 a[[i]] 来调用它的元素或用 a[[i]]=value 来修改它. 这一方式的缺陷是必须给出它的所有元素.
| a[i]=value | 增加变量或改动变量的值 |
| a[i] | 调用变量 |
| a[i]=. | 删除变量 |
| ?a | 显示定义过的值 |
| Clear[a] | 清除定义过的值 |
| Table[a[i],{i,1,n}] 或 Array[a,n] | 转换为一个列表 List |
"自定义函数" 节中讨论了在 Wolfram 语言中函数的定义. 在典型情况下,可以用 f[x_]=x^2 定义一个函数 f. (事实上,在 "自定义函数" 节中用 := 而不是 = 来定义. 在 "立即定义和延时定义" 节中将解释何时使用 := 和 = ).
定义 f[x_]=x^2 表明当 Wolfram 语言遇到与模式 f[x_] 匹配的表达式时,它将用 x^2 来代替该表达式. 由于模式f[x_] 与所有形如 f[anything] 的表达式匹配,这一定义可用于具有任何变量的函数 f.
函数定义如 f[x_]=x^2 可以与 "定义带标号的对象" 节讨论的有标号变量 f[a]=b 进行比较. 定义 f[a]=b 表明当特定 的表达式 f[a] 出现时用 b 代替. 但这定义对 f[y] 等表达式不起作用,因为这时 f 有另外的标号.
阶乘函数的数学定义几乎可以直接在 Wolfram 语言中使用,其形式为 f[n_]:=n f[n-1];f[1]=1. 此定义表明对 n 等于 1 的情况,f[1] 等于 1;对其余 n,f[n] 等于 n f[n-1].
这种行为对于 "定义函数" 节中给出的阶乘函数特别重要. 不管输入方式如何,Wolfram 系统总是把特殊规则 f[1] 放在 f[n_] 之前. 这意味着,当 Wolfram 系统在计算形如 f[n] 的表达式时,先测试 f[1],当它不能用时,再使用一般情况 f[n_]. 所以,在计算 f[5] 时,Wolfram 系统将一直使用一般规则直到“终止条件” f[1] 使用了为止.
如果 Wolfram 系统不遵循上述原则,则特殊规则将会被一般规则所“屏蔽”. 在阶乘的定义中,如果规则 f[n_] 在规则f[1] 之前使用,则 Wolfram 系统即使在求 f[1] 时也会用 f[n_] 规则,而 f[1] 规则永远不会被使用.
尽管在许多情况下,Wolfram 系统能判断哪一个规则更一般一些,但总有些例外. 例如,在两个含有 /; 的规则中,就无法确定哪一个更一般,事实上也没有明确的顺序. 在顺序不清楚时,Wolfram 系统总是按输入顺序保存规则.
Wolfram 语言中有两种赋值形式:lhs=rhs 和 lhs:=rhs. 其主要区别是什么时候 计算 rhs 的值. lhs=rhs 是立即赋值,即 rhs 是在赋值时立即计算. 而 lhs:=rhs 则是延时赋值,即赋值时并不计算 rhs,而是在需要 lhs 的值时才进行计算.
现在保存的定义是 Expand 命令的结果:
尽管 := 比 = 用得多一些,但还有必须用 = 定义函数的一个重要情形. 当进行一个运算得到具有符号参数 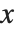 的结果时,还需要进一步得到对应于不同
的结果时,还需要进一步得到对应于不同 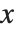 的结果. 一种方式是用 /. 将适当的规则用于
的结果. 一种方式是用 /. 将适当的规则用于 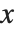 . 通常用 = 去定义变量
. 通常用 = 去定义变量 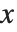 的函数就较方便一些.
的函数就较方便一些.
在上面的例子中,符号 a 是一个全局变量,它的值决定了 t 的大小. 当参数中大部分偶尔才变化时,用这种方式是方便的. 但必须认识到明显的或隐含的变量之间的依赖关系是容易混淆的,应该尽可能地使用函数明确地反映依赖关系.
用户可以看到定义如 f[x_]:=f[x]=f[x-1]+f[x-2] 是如何工作的. 函数 f[x_] 被定义为这个“程序” f[x]=f[x-1]+f[x-2]. 当调用函数 f 的值时,执行该“程序”. 该程序首先计算 f[x-1]+f[x-2],再将结果保存到 f[x] 中.
在 Wolfram 语言中进行递推运算时,使用能保存已有值的函数是一个好方法. 递推的一个典型情况是函数 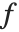 在整数
在整数 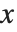 的值通过它在
的值通过它在  、
、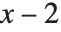 等值给出. Fibonacci 函数定义
等值给出. Fibonacci 函数定义 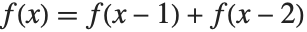 就是这样的一种递推,在计算
就是这样的一种递推,在计算  时,需反复递推,如需要反复计算
时,需反复递推,如需要反复计算  多次,故此时记住
多次,故此时记住  的值下次直接找出就比反复计算要好.
的值下次直接找出就比反复计算要好.
在 Wolfram 语言中,f[args]=rhs 或 f[args]:=rhs 会将对象 f 和你的定义相关联. 也就是说,当输入 ?f 时,就会显示该定义. 一般我们把符号 f 作为标头的表达式称为 f 的下值 (downvalue).
此定义不与 Exp 相关联:
一般的原则是,当函数 f 比 g 更常用的时,f[g[x]] 的定义应该作为 g 的上值. 因此,例如,在 Exp[g[x]] 中,Exp 是 Wolfram 语言中的内部函数,g 是引入的一个函数,此时将 Exp[g[x]] 作为 g 的上值,而不是 Exp 的下值,会更合理和自然.
一般来说,当 Wolfram 语言遇到一个特定函数时,它会尝试所有已给出的该函数的定义. 如果把 g[x_]+g[y_] 定义为 Plus 的下值时,则当遇到 Plus 时,Wolfram 语言就会试用这个定义. 这样,当每次 Wolfram 语言遇到加法时都会测试这个定义,因此使得运行速度变慢.
然而,当把 g[x_]+g[y_] 的定义作为 g 的上值时,你把定义与 g 关联. 仅当 g 出现在函数,例如 Plus 内时才尝试这个定义. 因为 g 出现的频率比 Plus 出现的少,因此这个是更有效的进程.
| f[g]^=value 或 f[g[args]]^=value | |
让赋值与 g 相关联而不是与 f 相关联 | |
| f[g]^:=value 或 f[g[args]]^:=value | |
让延迟赋值与 g 相关联 | |
| f[arg1,arg2,…]^=value | 让赋值与所有 argi 的标头相关联 |
一般可以将一个表达式的定义和出现在表达式中足够高层次的任何符号相关联. 在形如 f[args] 的表达式中,只要 g 本身或以 g 为标头的对象出现在 args 中时,就可以定义符号 g 的上值. 但当 g 出现在表达式的较低层次中时,就无法将这些定义与它相关联.
如 "表达式的含义" 中描述的,在 Wolfram 语言中,符号可作为“标记”来表明表达式的“类型”. 例如,复数在 Wolfram 语言中的内部形式为 Complex[x,y],这里符号 Complex 表明此对象是一个复数.
当定义 quat 关于 Plus 运算的上值时,就是扩大 Plus 的运算域以便包括 quat,即告诉 Wolfram 语言使用特殊的加法规则,当 quat 对象被加在一起时,它们仍是 quat 对象.
在定义 quat 对象的加法时,可以总是有特殊的加法操作,例如 quatPlus,你可以对其赋予合适的下值. 但用 Wolfram 语言中的标准运算 Plus 来表示加法,当遇到 quat 对象时,通过指定特殊行为来“覆盖”该操作,会更方便一些.
| expr=value | 定义一个任何情况下都用的量 |
| N[expr]=value | 定义一个用作近似值的量 |
去掉 Log 的保护:
现在可以自行定义 Log 函数. 即使这个定义不正确,Wolfram 语言也允许你这样定义:
清除 Log 的不正确定义:
恢复对 Log 的保护:
| DownValues[f] | 给出 f 的下值集 |
| UpValues[f] | 给出 f 的上值集 |
| DownValues[f]=rules | 建立 f 的下值 |
| UpValues[f]=rules | 建立 f 的上值 |
正如在 "定义函数" 中讨论的一样,Wolfram 语言按特殊定义出现在一般定义之前的原则对定义排序. 但事实上,没有唯一确定的方式去排序,可以用与 Wolfram 语言默认次序不同的方式去排序,对用 DownValues 和 UpValues 得到的规则表重新排序就达到目的.