Scrape Data from a Website
WORKFLOW
Scrape Data from a Website
Easily extract lists and tables from webpages.
Import webpage data
Data on webpages is often stored in list (<li>...</li>) and table (<table>...</table>) elements. You can extract all of the lists and tables on a page using the "Data" element of Import.
Here is a weather forecast webpage:
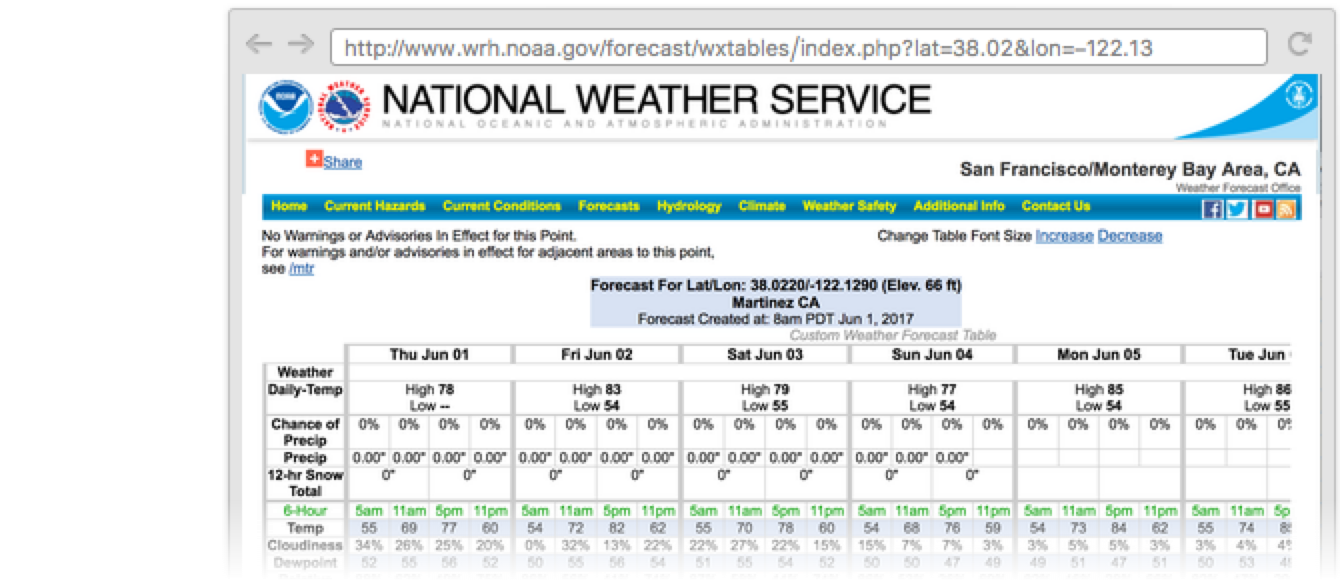
Scrape all of the lists and tables on that page:


- Use "FullData" to include empty elements in the scraped data, preserving the complete structures of lists and tables.
Extract the data you want
Pull out just the temperature data:

Analyze the data
Plot the temperature data. The “Temp” header in the numerical data is automatically ignored:
Notes
If a URL contains data in a format other than HTML, you can often import the data directly. Here is an import of earthquake data in "CSV" format, which is inferred from the “csv” extension:

