

SemanticImport
SemanticImport[file]
attempts to import a file semantically to give a Dataset object.
SemanticImport[file,type]
attempts to interpret all elements in the file as being of the specified type.
SemanticImport[file,{type1,type2,…}]
attempts to interpret elements in successive columns as being of the specified types.
SemanticImport[file,col1->type1,col2->type2,…]
keeps only the columns coli specified by their positions or names.
SemanticImport[file,typespec,form]
puts the result in the specified form.
Details and Options
- In SemanticImport[file], file can be specified as File["path"] or simply "path".
- SemanticImport is primarily intended for one- and two-dimensional arrays of elements.
- SemanticImport can use free-form linguistics to interpret elements in the structure it is given.
- Types of objects returned include numbers, Quantity objects, Entity objects, DateObject, GeoPosition, etc.
- SemanticImport makes detailed assumptions, for example about date formats, by looking at all elements in particular rows or columns of the input.
- Possible values for type include:
-
Automatic choose type automatically "String" Unicode string "Number" number in any standard format "Integer" integer in decimal notation "Real" real in decimal notation "Quantity" quantity with units "Currency" currency amount "Date" date in any standard format "DateTime" date and time "Time" time of day "GeoCoordinates" geo position specifed as latitude, longitude "URL" correctly formatted URL "EmailAddress" correctly formatted email address "Country" country given in natural language "City" city given in natural language None skip a column ispec any basic form used by Interpreter - The following options can be given to indicate features of the input:
-
CharacterEncoding Automatic assumed encoding of input file Delimiters Automatic delimiters between elements HeaderLines Automatic line numbers to treat as headers ExcludedLines {} lines to exclude from result MissingDataRules {} rules for replacing data to be considered "missing" - Possible values for form include:
-
"Dataset" a row-oriented dataset "List" a single column as a list "Columns" a list of columns, each given as a list "NamedColumns" an association associating column name with list of contents "Rows" a list of rows, each given as a list "NamedRows" a list of rows, each given as an association from column name to content - When elements cannot be interpreted, forms returned in their place include:
-
Missing["Empty"] an empty or whitespace element Missing["Invalid","string"] data with invalid or meaningless fields Missing["Unrecognized","string"] element that could not be parsed Missing["ByDesignation",value] an element matching MissingDataRules Missing[custom] a Missing[…] provided through MissingDataRules
Examples
open all close allBasic Examples (7)
Import a file, automatically detecting and interpreting dates and cities:
sales = SemanticImport["ExampleData/RetailSales.tsv"]Columns shown in bold correspond to semantic objects in the Wolfram Language:
sales[1, "Date"]sales[2, "City"]%["Population"]Import a file with the specified column types:
SemanticImport["ExampleData/RetailSales.tsv", {"Date", "City", "Integer"}]Import only some columns of a file, in the specified format, using column numbers:
SemanticImport["ExampleData/RetailSales.tsv", <|1 -> "Date", 3 -> Automatic|>]Import only some columns of a file, in the specified format, using column names:
SemanticImport["ExampleData/RetailSales.tsv", <|"Date" -> "Date", "Sales" -> Automatic|>]Import only some columns, specifying None for columns that should be dropped:
SemanticImport["ExampleData/RetailSales.tsv", {None, "City", "Integer"}]Import a file as a list of rows:
SemanticImport["ExampleData/RetailSales.tsv", Automatic, "Rows"][[ ;; 5]]Import a file as a list of columns:
{dates, cities, sales} = SemanticImport["ExampleData/RetailSales.tsv", Automatic, "Columns"];dates[[ ;; 5]]cities[[ ;; 5]]sales[[ ;; 5]]Scope (3)
Import a file using a given character encoding:
SemanticImport["ExampleData/UnicodeRetailSales.tsv", CharacterEncoding -> "Unicode"]Import a file using the given delimiter:
SemanticImport["ExampleData/dpkg.log", Delimiters -> " "]Specify that the first line of the file to import is a header:
SemanticImport["ExampleData/buildings.dat", HeaderLines -> 1]Specify that the first and fifth lines of a file should be skipped:
SemanticImport["ExampleData/buildings.dat", ExcludedLines -> {1, 5}]Return missing values with the form "Unknown" in the special form Missing["UnknownData"]:
SemanticImport["ExampleData/RetailSalesMissings.tsv", MissingDataRules -> {"Unknown" -> Missing["UnknownData"]}]Options (7)
SemanticImport uses many of the same options as SemanticImportString. See SemanticImportString for more examples.
CharacterEncoding (1)
The wrong character encoding can derail a good interpretation. Create a file of Unicode-encoded data:
path = FileNameJoin[{$TemporaryDirectory, "UnicodeBuildings.dat"}];
Export[path, Import["ExampleData/buildings.dat", "Text"], "Text", CharacterEncoding -> "Unicode"];Import the data using the default character encoding:
Take[SemanticImport[path, Automatic, "Rows", HeaderLines -> 1], 5]Import the data, specifying that it is encoded as Unicode:
SemanticImport[path, Automatic, "Rows", "CharacterEncoding" -> "Unicode", HeaderLines -> 1]//Take[#, 5]&Delimiters (1)
Specifying the delimiter determines how the values are separated:
SemanticImport["ExampleData/buildings.dat", Automatic, "Rows", Delimiters -> "|", HeaderLines -> 1]//Take[#, 5]&Specifying a nonexistent delimiter gives a single column of newline-separated items:
SemanticImport["ExampleData/buildings.dat", Automatic, "Rows", Delimiters -> ",", HeaderLines -> 1]//InputFormExcludedLines (1)
Lines are excluded by row number prior to header selection or further processing. Here is raw data:
FilePrint["ExampleData/buildings.dat"]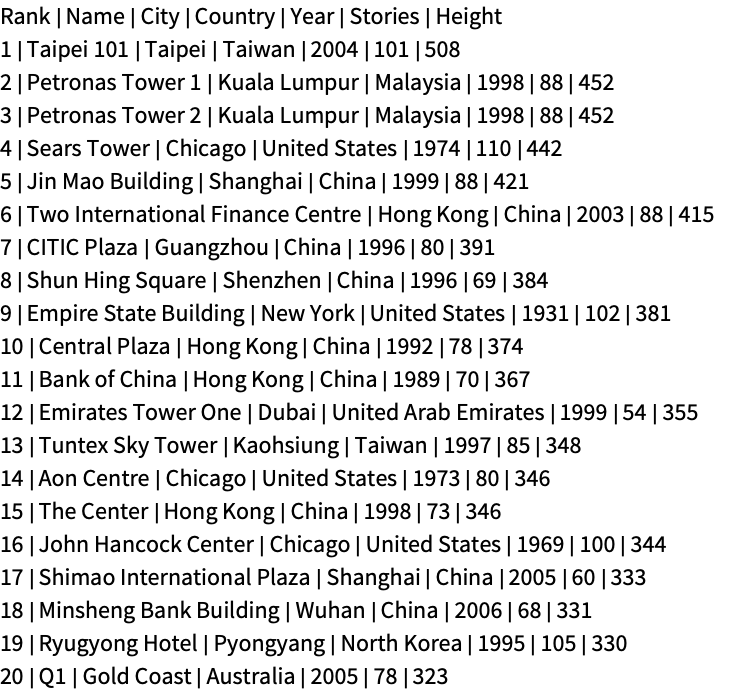
Excluding even line numbers gives the odd-ranked buildings, since the header line puts odd ranks on even lines:
SemanticImport["ExampleData/buildings.dat", Automatic, "NamedColumns", ExcludedLines -> Select[Range[40], EvenQ], HeaderLines -> 1]HeaderLines (1)
Specify the number of lines in the file to treat as a header:
SemanticImport["ExampleData/buildings.dat", Automatic, "NamedColumns", HeaderLines -> 0]//KeysSemanticImport["ExampleData/buildings.dat", Automatic, "NamedColumns", HeaderLines -> 1]//KeysSemanticImport["ExampleData/buildings.dat", Automatic, "NamedColumns", HeaderLines -> 2]//KeysMissingDataRules (2)
Replace strings that start with "Sears" by "Willis Tower":
SemanticImport["ExampleData/buildings.dat", Automatic, "NamedColumns", MissingDataRules -> {("Sears" ~~ ___) -> "Willis Tower"}, HeaderLines -> 1]["Name"]Rules are applied before interpretation:
SemanticImport["ExampleData/buildings.dat", Automatic, "NamedColumns", MissingDataRules -> {"United" ~~ ___ -> Missing["United country caught before interpretation"]}, "HeaderLines" -> 1]["Country"]Applications (6)
Import a table containing the flight cost from London to many countries as a Dataset object:
data = SemanticImport["ExampleData/countries-currency"]Get the geographic position of London:
london = CityData["London", "Coordinates"]Get the maximum price of a flight:
maxPrice = Max[data[[All, "Price"]]]Make a map showing the least expensive flight routes in blue and the most expensive ones in orange:
GeoGraphics[{AbsoluteThickness[2], Normal[{
Blend[{Blue, Orange}, #Price / maxPrice],
GeoPath[{london, CountryData[#"Flight Costs", "CenterCoordinates"]}]
}& /@ data[SortBy[Key["Price"]]]]}]Import the data for a timeline of personal emails:
data = SemanticImport["ExampleData/dates-categories"]Get the values that are in the "family" category:
family = data[Select[#[[2]] == "family"&]]DateListPlot@CountsBy[family, DateValue[First[#], {"Year", "Month"}]&]Import the first and third columns from a table of salaries for college faculty members:
data = SemanticImport["ExampleData/categories-numbers", <|"Salary" -> Automatic, "Rank" -> Automatic|>]ListPlot[data, AxesLabel -> {"Salary", "Rank"}]Import a dataset consisting of dates and numeric values as a Dataset object:
SemanticImport["ExampleData/financialtimeseries.csv"]Obtain the data as a list of rows:
SemanticImport["ExampleData/financialtimeseries.csv", Automatic, "Rows"]//ShortSpecify that dates should be interpreted as strings:
SemanticImport["ExampleData/financialtimeseries.csv", {"String", Automatic}, "Rows"]//ShortImport a dataset containing a list of famous buildings and their properties as a Dataset object. Cities and countries are automatically detected as Entity objects:
SemanticImport["ExampleData/buildings.dat", "HeaderLines" -> 1]Import only the Name, Country, and Height columns of the famous building dataset:
SemanticImport["ExampleData/buildings.dat", <|"Name" -> Automatic, "Country" -> Automatic, "Height" -> Automatic|>, HeaderLines -> 1]Possible Issues (3)
Automatic selection chooses from a less rich set of types than Interpreter:
SemanticImport["ExampleData/buildings.dat", Automatic, "NamedColumns", HeaderLines -> 1]["Name"]Specify explicit types to import Entity objects rather than strings:
SemanticImport["ExampleData/buildings.dat", {"Integer", "Building", "City", "Country", "Date", "Integer", "Integer"}, "NamedColumns", HeaderLines -> 1]["Name"]An Automatic type specifies an automatically selected number of columns:
SemanticImport["ExampleData/buildings.dat", Automatic, "Rows", HeaderLines -> 1]//Take[#, 5]&An {Automatic} type specifies a single column of automatically selected type:
SemanticImport["ExampleData/buildings.dat", {Automatic}, "Rows", HeaderLines -> 1]//Take[#, 5]&//InputFormAutomatic in a type list applies to the corresponding column sequentially:
SemanticImport["ExampleData/buildings.dat", {Automatic, Automatic, Automatic, Automatic, Automatic, Automatic, Automatic}, "Rows", HeaderLines -> 1]//Take[#, 5]&The default Automatic selection of header lines can be incorrect, depending on whether data is organized in rows or columns:
SemanticImport["ExampleData/buildings.dat", Automatic, "Rows"]//Take[#, 2]&Specify the number of header lines explicitly to import the data correctly:
SemanticImport["ExampleData/buildings.dat", Automatic, "Rows", "HeaderLines" -> 1]//Take[#, 2]&Related Links
Text
Wolfram Research (2014), SemanticImport, Wolfram Language function, https://reference.wolfram.com/language/ref/SemanticImport.html (updated 2016).
CMS
Wolfram Language. 2014. "SemanticImport." Wolfram Language & System Documentation Center. Wolfram Research. Last Modified 2016. https://reference.wolfram.com/language/ref/SemanticImport.html.
APA
Wolfram Language. (2014). SemanticImport. Wolfram Language & System Documentation Center. Retrieved from https://reference.wolfram.com/language/ref/SemanticImport.html