

ClusteringTree
ClusteringTree[{e1,e2,…}]
constructs a weighted tree from the hierarchical clustering of the elements e1, e2, ….
ClusteringTree[{e1v1,e2v2,…}]
represents ei with vi in the constructed graph.
ClusteringTree[{e1,e2,…}{v1,v2,…}]
represents ei with vi in the constructed graph.
ClusteringTree[label1e1,label2e2…]
represents ei using labels labeli in the constructed graph.
ClusteringTree[data,h]
constructs a weighted tree from the hierarchical clustering of data by joining subclusters at distance less than h.
Details and Options


- ClusteringTree creates a Tree object showing how data points cluster together hierarchically.
- The data elements ei can be numbers; numeric lists, matrices, or tensors; lists of Boolean elements; strings or images; geo positions or geographical entities; colors; as well as combinations of these. If the ei are lists, matrices, or tensors, each must have the same dimensions.
- The result from ClusteringTree is a binary weighted tree, where the weight of each vertex indicates the distance between the two subtrees that have that vertex as root:
- ClusteringTree has the same options as Graph, with the following additions and changes: [List of all options]
-
ClusterDissimilarityFunction Automatic the clustering linkage algorithm to use DistanceFunction Automatic the distance or dissimilarity to use EdgeStyle GrayLevel[0.65] styles for edges FeatureExtractor Automatic how to extract features from data VertexSize 0 size of vertices - By default, ClusteringTree will preprocess the data automatically unless either a DistanceFunction or a FeatureExtractor is specified.
- ClusterDissimilarityFunction defines the intercluster dissimilarity, given the dissimilarities between member elements.
- Possible settings for ClusterDissimilarityFunction include:
-
"Average" average intercluster dissimilarity "Centroid" distance from cluster centroids "Complete" largest intercluster dissimilarity "Median" distance from cluster medians "Single" smallest intercluster dissimilarity "Ward" Ward's minimum variance dissimilarity "WeightedAverage" weighted average intercluster dissimilarity a pure function - The function f defines a distance from any two clusters.
- The function f needs to be a real-valued function of the DistanceMatrix.
-
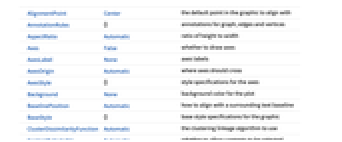
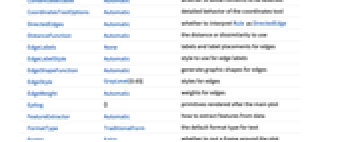
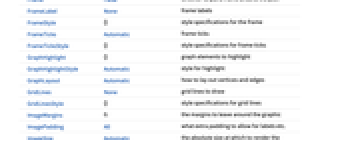
AlignmentPoint Center the default point in the graphic to align with AnnotationRules {} annotations for graph, edges and vertices AspectRatio Automatic ratio of height to width Axes False whether to draw axes AxesLabel None axes labels AxesOrigin Automatic where axes should cross AxesStyle {} style specifications for the axes Background None background color for the plot BaselinePosition Automatic how to align with a surrounding text baseline BaseStyle {} base style specifications for the graphic ClusterDissimilarityFunction Automatic the clustering linkage algorithm to use ContentSelectable Automatic whether to allow contents to be selected CoordinatesToolOptions Automatic detailed behavior of the coordinates tool DirectedEdges Automatic whether to interpret Rule as DirectedEdge DistanceFunction Automatic the distance or dissimilarity to use EdgeLabels None labels and label placements for edges EdgeLabelStyle Automatic style to use for edge labels EdgeShapeFunction Automatic generate graphic shapes for edges EdgeStyle GrayLevel[0.65] styles for edges EdgeWeight Automatic weights for edges Epilog {} primitives rendered after the main plot FeatureExtractor Automatic how to extract features from data FormatType TraditionalForm the default format type for text Frame False whether to put a frame around the plot FrameLabel None frame labels FrameStyle {} style specifications for the frame FrameTicks Automatic frame ticks FrameTicksStyle {} style specifications for frame ticks GraphHighlight {} graph elements to highlight GraphHighlightStyle Automatic style for highlight GraphLayout Automatic how to lay out vertices and edges GridLines None grid lines to draw GridLinesStyle {} style specifications for grid lines ImageMargins 0. the margins to leave around the graphic ImagePadding All what extra padding to allow for labels etc. ImageSize Automatic the absolute size at which to render the graphic LabelStyle {} style specifications for labels Method Automatic details of graphics methods to use PerformanceGoal Automatic aspects of performance to try to optimize PlotLabel None an overall label for the plot PlotRange All range of values to include PlotRangeClipping False whether to clip at the plot range PlotRangePadding Automatic how much to pad the range of values PlotRegion Automatic the final display region to be filled PlotTheme $PlotTheme overall theme for the graph PreserveImageOptions Automatic whether to preserve image options when displaying new versions of the same graphic Prolog {} primitives rendered before the main plot RotateLabel True whether to rotate y labels on the frame Ticks Automatic axes ticks TicksStyle {} style specifications for axes ticks VertexCoordinates Automatic coordinates for vertices VertexLabels None labels and placements for vertices VertexLabelStyle Automatic style to use for vertex labels VertexShape Automatic graphic shape for vertices VertexShapeFunction Automatic generate graphic shapes for vertices VertexSize 0 size of vertices VertexStyle Automatic styles for vertices VertexWeight Automatic weights for vertices
List of all options

Examples
open all close allBasic Examples (5)
Scope (8)
Obtain a cluster hierarchy from a list of numbers:
Look at the distance between subclusters by looking at the VertexWeight:
Find the shortest path from the root vertex to the leaf 3.4:
Obtain a cluster hierarchy from a heterogeneous dataset:
Compare it with the cluster hierarchy of the colors:
Generate a list of random colors:
Obtain a cluster hierarchy from the list using the "Centroid" linkage:
Compute the hierarchical clustering from an Association:
Compare it with the hierarchical clustering of its Values:
Compare it with the hierarchical clustering of its Keys:
Obtain a cluster hierarchy by merging clusters at distance less than 0.4:
Change the style and the layout of the ClusteringTree:
Obtain a cluster hierarchy from a list of three-dimensional vectors and label the leaves with the total of the corresponding element:
Compare it with the cluster hierarchy of the total of each vector:
Options (9)
ClusterDissimilarityFunction (1)
DistanceFunction (1)
Generate a list of random vectors:
Obtain a cluster hierarchy using different DistanceFunction:
FeatureExtractor (1)
Obtain a cluster hierarchy from a list of pictures:
Use a different FeatureExtractor to extract features:
Use the Identity FeatureExtractor to leave the data unchanged:
ImageSize (2)
Specify an explicit image size for the whole tree:
Independent settings for width and height affect the tree bounding box but not its aspect ratio:
Set both ImageSize and AspectRatio explicitly:
VertexLabelStyle (4)
Customize several aspects of the labels:
Some expressions, like images, are not affected by FontSize:
Use Magnification to affect every type of expression:
Text
Wolfram Research (2016), ClusteringTree, Wolfram Language function, https://reference.wolfram.com/language/ref/ClusteringTree.html (updated 2017).
CMS
Wolfram Language. 2016. "ClusteringTree." Wolfram Language & System Documentation Center. Wolfram Research. Last Modified 2017. https://reference.wolfram.com/language/ref/ClusteringTree.html.
APA
Wolfram Language. (2016). ClusteringTree. Wolfram Language & System Documentation Center. Retrieved from https://reference.wolfram.com/language/ref/ClusteringTree.html