

NeedlemanWunschSimilarity
NeedlemanWunschSimilarity[u,v]
gives a number representing the Needleman–Wunsch similarity between strings, vectors or biomolecular sequences u and v.
Details and Options
- NeedlemanWunschSimilarity[u,v] finds an optimal global alignment between the elements of u and v, and returns the number of one-element matches.
- NeedlemanWunschSimilarity takes the following options:
-
GapPenalty 0 additional cost for each alignment gap IgnoreCase False whether to ignore case of letters in strings SimilarityRules Automatic rules for similarities between elements - With the default setting SimilarityRules->Automatic, each match between two elements contributes
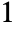 to the total similarity score, while each mismatch, insertion or deletion contributes
to the total similarity score, while each mismatch, insertion or deletion contributes 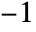 .
. - The option GapPenalty specifies an additional cost to be subtracted from the similarity score for any run of insertions or deletions.
Examples
open all close allBasic Examples (3)
Needleman–Wunsch similarity between two strings:
NeedlemanWunschSimilarity[ "abcde", "abcXde"]Needleman–Wunsch similarity between two vectors:
NeedlemanWunschSimilarity[{1, 1, 0, 0, 1, 1}, {1, 1, 1, 1, 1, 1}]Needleman–Wunsch similarity between two biomolecular sequences:
NeedlemanWunschSimilarity[BioSequence["DNA", "AGGTCCCAAAA"], BioSequence["DNA", "AGGTTCCAAT"]]Options (3)
GapPenalty (1)
GapPenalty adds an extra penalty for deletion or insertion actions:
NeedlemanWunschSimilarity[ "ABCDEF", "ABCxDEF"]NeedlemanWunschSimilarity[ "ABCDEF", "ABCxDEF", GapPenalty -> 1]IgnoreCase (1)
By default, lowercase and uppercase letters are treated as distinct:
{NeedlemanWunschSimilarity[ "ABCDEF", "abcdef"], NeedlemanWunschSimilarity[ "ABCDEF", "ABCDEF"]}Set IgnoreCase to True to treat them as equivalent:
NeedlemanWunschSimilarity[ "ABCDEF", "abcdef", IgnoreCase -> True]SimilarityRules (1)
The "SimilarDegenerateBases" setting allows a higher similarity for matching degenerate terms in biomolecular sequences:
NeedlemanWunschSimilarity[BioSequence["DNA", "ANNTNCC"], BioSequence["DNA", "GGTTCC"]]NeedlemanWunschSimilarity[BioSequence["DNA", "ANNTNCC"], BioSequence["DNA", "GGTTCC"], SimilarityRules -> "SimilarDegenerateBases"]Text
Wolfram Research (2008), NeedlemanWunschSimilarity, Wolfram Language function, https://reference.wolfram.com/language/ref/NeedlemanWunschSimilarity.html (updated 2020).
CMS
Wolfram Language. 2008. "NeedlemanWunschSimilarity." Wolfram Language & System Documentation Center. Wolfram Research. Last Modified 2020. https://reference.wolfram.com/language/ref/NeedlemanWunschSimilarity.html.
APA
Wolfram Language. (2008). NeedlemanWunschSimilarity. Wolfram Language & System Documentation Center. Retrieved from https://reference.wolfram.com/language/ref/NeedlemanWunschSimilarity.html