Text (.txt)
- Import and Export support a variety of Western character encodings and the Unicode standard.
- UTF (Unicode Transformation Format) and UCS (Universal Character Set) mapping methods are supported.
- The Wolfram Language can display a wide range of character sets, including Western and Asian scripts, mathematical symbols, and other special characters.
Background & Context
-
- Plain text file.
- Universal format for storage and exchange of textual information.
- Represents text as a sequence of characters and line separators.
- Stores characters as ASCII, 8-bit Western character codes, or Unicode.
Import & Export
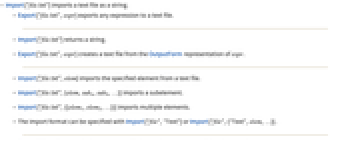
- Import["file.txt"] imports a text file as a string.
- Export["file.txt",expr] exports any expression to a text file.
- Import["file.txt"] returns a string.
- Export["file.txt",expr] creates a text file from the OutputForm representation of expr.
- Import["file.txt",elem] imports the specified element from a text file.
- Import["file.txt",{elem,suba,subb,…}] imports a subelement.
- Import["file.txt",{{elem1,elem2,…}}] imports multiple elements.
- The import format can be specified with Import["file","Text"] or Import["file",{"Text",elem,…}].
- Export["file.txt",expr,elem] creates a text file by treating expr as specifying element elem.
- Export["file.txt",{expr1,expr2,…},{{elem1,elem2,…}}] treats each expri as specifying the corresponding elemi.
- Export["file.txt",expr,opt1->val1,…] exports expr with the specified option elements taken to have the specified values.
- Export["file.txt",{elem1->expr1,elem2->expr2,…},"Rules"] uses rules to specify the elements to be exported.
- See the following reference pages for full general information:
-
Import, Export import from or export to a file CloudImport, CloudExport import from or export to a cloud object ImportString, ExportString import from or export to a string ImportByteArray, ExportByteArray import from or export to a byte array
Import Elements

- General Import elements:
-
"Elements" list of elements and options available in this file "Summary" summary of the file "Rules" list of rules for all available elements - Data representation elements:
-
"Data" tabular representation of the text "Lines" lines, given as a list of strings "Plaintext" text file represented as a single Wolfram Language string "String" raw byte string "Words" words separated by spaces, given as a list of strings - Import and Export use the "Plaintext" element by default.
- Import["file.txt"] reads a text file, taking the character encoding to be "UTF8" by default.
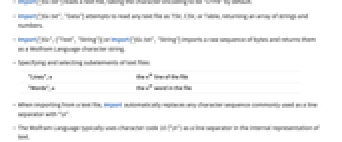
- Import["file.txt","Data"] attempts to read any text file as TSV, CSV, or Table, returning an array of strings and numbers.
- Import["file",{"Text","String"}] or Import["file.txt","String"] imports a raw sequence of bytes and returns them as a Wolfram Language character string.
- Specifying and selecting subelements of text files:
-
"Lines",n the n ") line of the file
line of the file"Words",n the n ") word in the file
word in the file - When importing from a text file, Import automatically replaces any character sequence commonly used as a line separator with "\n".
- The Wolfram Language typically uses character code 10 ("\n") as a line separator in the internal representation of text.
- Export uses the line separator convention of the computer system on which the Wolfram System is being run.
Options

- Import option:
-
CharacterEncoding "UTF8ISOLatin1" raw character encoding used to read the file - Export option:
-
CharacterEncoding "UTF8" raw character encoding used to write the file - Possible settings for CharacterEncoding include:
-
Automatic attempts to infer the character encoding of the file "AdobeStandard" Adobe standard PostScript font encoding "ASCII" full ASCII, with control characters "EUC" extended Unix code for Japanese "ISOLatin1" ISO 8859‐1 standard "ISOLatin2" ISO 8859‐2 standard "ISOLatin3" ISO 8859‐3 standard "ISOLatin4" ISO 8859‐4 standard "ISOLatinCyrillic" ISO 8859‐5 standard "MacintoshRoman" Macintosh roman font encoding "PrintableASCII" printable ASCII "ShiftJIS" Shift‐JIS encoding of JIS X 0208‐1990 and extensions "Symbol" symbol font encoding "Unicode" fixed-width 2-byte Unicode with byte-order mark (UCS-2) "UTF-8" variable-width 1-byte Unicode format "UTF8ISOLatin1" interprets bytes as UTF8, falling back to ISOLatin1 "WindowsANSI" Windows standard font encoding - By default, Import attempts to interpret the data as "UTF-8" encoded text. If any sequence of bytes stored in the file cannot be represented in "UTF-8", Import uses "ISOLatin1" instead.
- The Wolfram Language internally stores characters as Unicode values.
- When importing with the setting CharacterEncoding->"Unicode", if no byte order mark is present in the text, the Wolfram Language assumes the byte ordering given by $ByteOrdering. Use ByteOrderingorder to force a specific byte ordering.
- A complete list of possible encodings is given by $CharacterEncodings.