Text (.txt)
- ImportとExportは種々の西ヨーロッパ文字コードとUnicode標準をサポートする.
- UTF (Unicode Transformation Format)およびUCS (Universal Character Set)マッピング法がサポートされる.
- Wolfram言語は西ヨーロッパやアジアのスクリプト文字,数学記号,その他の特殊文字を含む.幅広い文字セットを表示することができる.
予備知識
-
- テキストファイル.
- テキスト情報の保管と交換に使われる一般的な形式.
- テキストを文字の列と行区切り記号の列として表す.
- 文字をASCII,8ビット西ヨーロッパ文字コード,あるいはUnicodeとして保管する.
ImportとExport
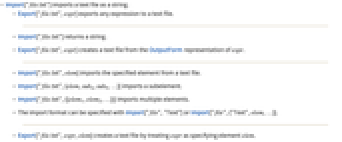
- Import["file.txt"]はテキストファイルを文字列としてインポートする.
- Export["file.txt",expr]は式をテキストファイルとしてエキスポートする.
- Import["file.txt"]は文字列を返す.
- Export["file.txt",expr]は expr のOutputForm表現からテキストファイルを作成する.
- Import["file.txt",elem]はテキストファイルから指定された要素をインポートする.
- Import["file.txt",{elem,suba,subb,…}]はサブ要素をインポートする.
- Import["file.txt",{{elem1,elem2,…}}]は複数の要素をインポートする.
- インポート形式はImport["file","Text"]またはImport["file",{"Text",elem,…}]で指定できる.
- Export["file.txt",expr,elem]は expr が要素 elem を指定してるとしてテキストファイルを作成する.
- Export["file.txt",{expr1,expr2,…},{{elem1,elem2,…}}]は各 expri が対応する elemi を指定しているとして扱う.
- Export["file.txt",expr,opt1->val1,…]は指定の値を持つ指定のオプション要素で expr をエキスポートする.
- Export["file.txt",{elem1->expr1,elem2->expr2,…},"Rules"]は規則を使ってエキスポートする要素を指定する.
- 一般的な情報は,以下の関数ページを参照のこと.
-
Import, Export ファイルからインポートする,あるいはファイルへエキスポートする CloudImport, CloudExport クラウドオブジェクトからインポートする,あるいはクラウドオブジェクトへエキスポートする ImportString, ExportString 文字列からインポートする,あるいは文字列へエキスポートする ImportByteArray, ExportByteArray バイト配列からインポートする,あるいはバイト配列へエキスポートする
Import要素

- 一般的なImport要素:
-
"Elements" ファイル中の有効な要素とオプションのリスト "Summary" ファイルの概要 "Rules" 使用可能なすべての要素の規則のリスト - データ表現要素:
-
"Data" 表で表されたテキスト "Lines" 文字列のリストとして与えられた行 "Plaintext" 単一のWolfram言語の文字列として表されたテキストファイル "String" 生のバイト文字列 "Words" 文字列のリストとして与えられた,空白で区切られた単語 - ImportとExportはデフォルトで"Plaintext"要素を使用する.
- Import["file.txt"]はデフォルトで文字コードを"UTF8"としてテキストファイルを読み込む.
- Import["file.txt","Data"]はテキストファイルをTSV,CSV,Tableとして読み込むことを試み,文字列と数の配列を返す.
- Import["file",{"Text","String"}]またはImport["file.txt","String"]はバイトの生の列をインポートし,Wolfram言語の文字列として返す.
- テキストファイルのサブ要素の指定と選択:
-
"Lines",n ファイルの n 行目 "Words",n ファイルの n 番目の単語 - テキストファイルからインポートする際,Importは一般的に改行記号として使われる文字列をすべて自動的に"\n"に置き換える.
- Wolfram言語は通常テキストの内部表現の改行文字に文字コード10 ("\n")を使用する.
- ExportはWolframシステムが実行されているコンピュータシステムに従った改行文字を使用する.
オプション


- Importオプション:
-
CharacterEncoding "UTF8ISOLatin1" ファイルの読取りで使用される生の文字コード - Exportオプション:
-
CharacterEncoding "UTF8" ファイルへの書込みで使用される生の文字コード - CharacterEncodingに使用できる設定の例:
-
Automatic ファイルの文字コードの推測を試みる "AdobeStandard" Adobe標準PostScriptフォント符号化方式 "ASCII" 制御文字を含む全ASCII "EUC" Japanese用の拡張Unixコード "ISOLatin1" ISO 8859‐1標準 "ISOLatin2" ISO 8859‐2標準 "ISOLatin3" ISO 8859‐3標準 "ISOLatin4" ISO 8859‐4標準 "ISOLatinCyrillic" ISO 8859‐5標準 "MacintoshRoman" Macintosh明朝体文字コード "PrintableASCII" 表示可能なASCII "ShiftJIS" JIS X 0208‐1990および拡張のShift‐JIS符号化方式 "Symbol" 記号フォント文字コード "Unicode" BOM (Byte Order Mark)付き固定幅2バイト(UCS-2) "UTF8" 可変幅1バイトUnicode形式 "UTF8ISOLatin1" バイトをUTF8として解釈し,ISOLatin1に戻す "WindowsANSI" Windows標準フォント文字コード - デフォルトでは,Importはデータが"UTF8"で符号化されたテキストであるとして解釈を試みる.ファイルに保存されたバイト列で"UTF8"で表せないものがある場合,Importは代りに"ISOLatin1"を使用する.
- Wolfram言語は文字を内部的にUnicode値として保管する.
- CharacterEncoding->"Unicode"という設定でテキストをインポート,エキスポートする際,テキスト内にバイト順マークがない場合は,Wolfram言語は$ByteOrderingで与えられるバイト順を想定する.特定のバイト順を矯正するためにはByteOrderingorder を使用する.
- 使用できる全符号化方式のリストは$CharacterEncodingsで得られる.