Text (.txt)
- Import 与 Export 支持各种西文字符编码和 Unicode 标准.
- 支持 Unicode 转换格式(UTF)与 通用字符集(UCS)映射方法.
- Wolfram 语言可以显示广范围的字符集,包括西方和东方的脚本,数学符号以及其他特殊字符.
背景
-
- 纯文本文件.
- 存储和交换文本信息的通用格式.
- 以字符序列和行分隔符表示文本.
- 以 ASCII、8位西文字符码或 Unicode 存储字符.
Import 与 Export
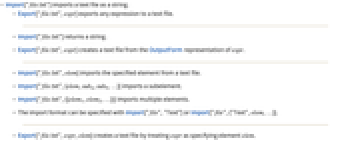
- Import["file.txt"] 以字符串形式导入文本文件.
- Export["file.txt",expr] 将任意表达式导出为一个文本文件.
- Import["file.txt"] 返回一个字符串.
- Export["file.txt",expr] 从 expr 的 OutputForm 表示中创建一个文本文件.
- Import["file.txt",elem] 从一个文本文件中导入指定的参数.
- Import["file.txt",{elem,suba,subb,…}] 导入一个子参数.
- Import["file.txt",{{elem1,elem2,…}}] 导入多个参数.
- 导入格式可以用 Import["file","Text"] 或 Import["file",{"Text",elem,…}] 明确指定.
- Export["file.txt",expr,elem] 通过将 expr 作为指定参数 elem 创建一个文本文件.
- Export["file.txt",{expr1,expr2,…},{{elem1,elem2,…}}] 将每一个 expri 指定为相应的 elemi.
- Export["file.txt",expr,opt1->val1,…] 导出具有指定值的指定选项参数的 expr.
- Export["file.txt",{elem1->expr1,elem2->expr2,…},"Rules"] 使用规则指定要导出的参数.
- 请到以下参考页面了解完整的基本信息:
-
Import, Export 从文件导入或导出到文件 CloudImport, CloudExport 从云对象导入或导出到云对象 ImportString, ExportString 从字符串导入或导出到字符串 ImportByteArray, ExportByteArray 从字节数组导入或导出到字节数组
导入参数

- Import 的通用参数:
-
"Elements" 该文件可用的参数和选项列表 "Summary" 文件摘要 "Rules" 所有可用参数的规则列表 - 表示数据的参数:
-
"Data" 文本的表格表示 "Lines" 以字符串列表形式表示的行 "Plaintext" 表示为单个 Wolfram 语言字符串的文本文件 "String" 原始字节字符串 "Words" 由空格分隔的单词,以字符串列表形式表示 - 默认情况下,Import 与 Export 使用 "Plaintext"参数.
- Import["file.txt"] 读取一个文本文件,默认情况下,认为字符编码为 "UTF8".
- Import["file.txt","Data"] 尝试以 TSV、CSV 或Table 形式读取任何文本文件,返回字符串和数字的数组.
- Import["file",{"Text","String"}] 或 Import["file.txt","String"] 导入原始字节序列并以 Wolfram 语言的字符字符串形式返回.
- 指定和选择文本文件的子参数:
-
"Lines",n 文件中的第 n  行
行"Words",n 文件中第 n  个单词
个单词 - 当从文本文件中导入时,Import 自动将常用作行分隔符的任何字符序列取代为 "\n".
- Wolfram 语言在内部的文本表示中一般用 10 ("\n") 作为行分隔符.
- Export 使用运行 Wolfram 系统的计算机系统的行分隔字符的常用规范.
选项


- Import 选项:
-
CharacterEncoding "UTF8ISOLatin1" 用于读取文件的原始字符编码 - Export 选项:
-
CharacterEncoding "UTF8" 文件中使用的原始字符编码 - CharacterEncoding 的可能设置包括:
-
Automatic 尝试推断文件的字符编码 "AdobeStandard" Adobe 标准 PostScript 字体编码 "ASCII" 完整的 ASCII,带有控制字符 "EUC" 用于日文的扩展的 Unix 编码 "ISOLatin1" ISO 8859‐1 标准 "ISOLatin2" ISO 8859‐2 标准 "ISOLatin3" ISO 8859‐3 标准 "ISOLatin4" ISO 8859‐4 标准 "ISOLatinCyrillic" ISO 8859‐5 标准 "MacintoshRoman" Macintosh 罗马字体编码 "PrintableASCII" 可打印的 ASCII "ShiftJIS" JIS X 0208‐1990 以及扩展的 Shift‐JIS 编码 "Symbol" 符号字体编码 "Unicode" 具有字节顺序标记的固定宽度 2 字节 Unicode(UCS-2) "UTF-8" 可变宽度的一字节 Unicode 格式 "UTF8ISOLatin1" 解释位数为 UTF8,替代为 ISOLatin1 "WindowsANSI" Windows 标准字体编码 - 在默认情况下,Import 尝试将数据解释为 "UTF-8" 编码文本. 如果文件中存储的任意位数序列无法表示为 "UTF-8",则 Import 使用 "ISOLatin1" 替代.
- Wolfram 语言内部存储字符为 Unicode 值.
- 使用设置 CharacterEncoding->"Unicode" 导入时,如果文本中不存在字节顺序标记,则 Wolfram 语言将假定 $ByteOrdering 给定的字节顺序. 用 ByteOrderingorder 强制特定的字节排序.
- 由 $CharacterEncodings 给出完整的可能编码列表.