"Markov" (機械学習メソッド)
"Markov" (機械学習メソッド)
- Classifyのためのメソッドである.
- 指定された文字列の n グラム頻度を使ってクラス確率をモデル化する.
詳細とサブオプション
- マルコフ(Markov)モデルでは,訓練時間に各クラスについての n グラム言語モデルが計算される.検定時間では,各クラスの確率がベイズ理論
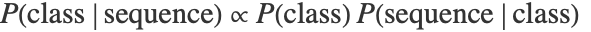 に従って計算される.
に従って計算される.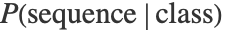 は指定されたクラスの言語モデルによって与えられる.
は指定されたクラスの言語モデルによって与えられる. はクラスの事前確率である.
はクラスの事前確率である. - 次は,使用可能なオプションである.
-
"AdditiveSmoothing" .1 使用する平滑化パラメータ "MinimumTokenCount" Automatic 考慮する n グラムの最小数 "Order" Automatic n グラムの長さ - "Order"n のとき,このメソッドは文字列を(n+1)グラムに分割する.
- "Order"0のとき,このメソッドはユニグラム(シングルトークン)を使う.モデルはユニグラムモデルまたはネイティブベイズモデルと呼ぶことができる.
- "AdditiveSmoothing"の値はすべての n グラム数に加えられる.これは,言語モデルの正規化に使われる.