"Markov" (机器学习方法)
- Classify 的方法.
- 使用已知序列的 n-gram 频率模拟类别概率.
详细信息与子选项
- 在马尔可夫模型中,在训练时,为每个类别计算一个 n-gram 语言模型. 在测试时,每个类的概率根据贝叶斯定理
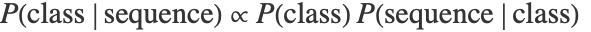 计算,其中
计算,其中 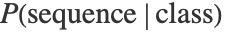 由给定类别的语言模型给出,
由给定类别的语言模型给出,  是类别先验.
是类别先验. - 可以给出下列选项:
-
"AdditiveSmoothing" .1 要使用的平滑参数 "MinimumTokenCount" Automatic 要考虑的 n-gram 的最小计数 "Order" Automatic n-gram 长度 - 当 "Order"n 时,该方法分割 (n+1)-gram 中的序列.
- 当 "Order"0 时,该方法使用 Unigram(一元,或称单一符号). 该模型可以称为 Unigram 模型或朴素的贝叶斯模型.
- "AdditiveSmoothing" 的值被添加至所有的 n-gram 计数. 它用于规范语言模型.