"SubwordTokens" (神经网络编码器)
NetEncoder[{"SubwordTokens",{token1,token2,…}}]
表示一个编码器,根据给定词汇将文本分割成子词.
NetEncoder[{"SubwordTokens",File["path"]}]
从文件中加载 SentencePiece BPE 模型.
NetEncoder[{"SubwordTokens",…,"param"value}]
表示一个已被指定附加参数的编码器.
更多信息



- 子词词元化是单词层级和字母层级之间的结构,词元要么是完整的单词,要么是子部分.
- 编码器的输出是 1 到 d 之间的整数序列,其中 d 是词元列表中元素的数量.
- NetEncoder[…][input] 将编码器应用于字符串生成输出.
- NetEncoder[…][{input1,input2,…}] 将编码器应用于字符串列表生成输出列表.
- 当构建网络时,可通过指定 "port"->NetEncoder[…] 将编码器附于网络的输入端口.
- NetDecoder[NetEncoder[{"SubwordTokens",…}]] 生成从给定编码器继承设置的 NetDecoder[{"SubwordTokens",…}].
- 在 NetEncoder[{"SubwordTokens",{token1,token2,…},…}] 中,每个词元必须是字符串或这些特殊词元中的一个:
-
StartOfString 出现在字符串开始的虚拟词元 EndOfString 出现在字符串尾部之后的虚拟词元 _ 任何未分配字符 - 按照惯例,引领一个单词的词元对应于以空格开头的字符串(如 "word"),单词中的词元对应于以任何其他字符开头的字符串(如"tion").
- 词元列表必须包含字符 _.
- 当设定 "IncludeTerminalTokens"True 时,必须同时包含 StartOfString 和 EndOfString.
- 支持下列参数:
-
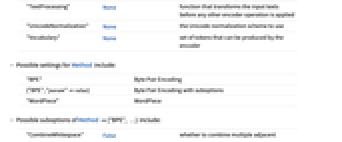
IgnoreCase False 是否忽略从字符串匹配词元的情况 "IncludeTerminalTokens" False 是否在输出中包括 StartOfString 和 EndOfString 词元 "InputType" "String" 编码器每个输入的格式 Method "BPE" 将文本分割为子词的算法 "OutputProperties" "VocabularyIndex" 每个子词词元的输出的属性 "TargetLength" All 要裁剪或填充的最终序列的长度 "TextPreprocessing" None 可以在任何其他编码器操作应用之前转换输入文本的函数 "UnicodeNormalization" None 要使用的 Unicode 标准化方案 "Vocabulary" None 可由编码器生成的词元组 - Method 的可能设置包括:
-
"BPE" 字节对编码 {"BPE","param"value} 有子选项的字节对编码 "WordPiece" WordPiece - Method{"BPE", …} 的可能子选项包括:
-
"CombineWhitespace" False - 是否结合多个相邻空白字符
"WhitespacePadding" None 控制空白符插入输入字符串 - 参数 "WhitespacePadding" 可设置为 Left 或 Right,以在编码前将空白符分别添加在输入字符串的开头或结尾. 默认值 None 不会插入任何额外空白符.
- 可用下列对参数 "InputType" 的设置:
-
"ListOfStrings" 每个输入文本由一个字符串列表表示 "String" 每个输入文本由一个字符串表示 - 可用下列对参数 "OutputProperties" 的设置:
-
"VocabularyIndex" 词元列表中的词元指数(缺省) "InputIndex" 包括词元的字符串指数(可能在 "InputType""ListOfStrings"的设置下不是 1) "StartPosition" 文本中词元的起始位置 "EndPosition" 文本中词元的结束位置 {prop1,prop2,…} 有效属性列表 - 默认设置参数 "TargetLength"->All,所有在输入字符串中找到的词元都会被编码.
- 设置 "TargetLength"->n,则在输入字符串中找到的前 n 个词元都会被编码,并在如果找到的词元小于 n 个时应用填充. 若 EndOfString 存在于词元列表中,则填充值是与其相关联的整数代码;否则会使用与上个词元关联的代码.
- "UnicodeNormalization" 的可能设置包括 CharacterNormalize 的 Unicode 标准化格式:
-
"NFD" 标准分解(格式 D) "NFC" 标准分解,跟着是标准分解(格式 C) "NFKD" 兼容性分解(格式 KD) "NFKC" 兼容性分解,跟着是标准分解(格式 KC) None 无标准化 - 词汇可使用选项 "Vocabulary"{token1,token2,…} 指定为一个词元字符串列表. 若词汇已被指定,编码器不会生成词汇中词元的整数代码. 设置 Method"BPE" 时,在词元化生成未登录词词元的情况下,生成该词元的操作会被逆转直到该词元分解成词汇词元或单个字符.
- SentencePiece 库中的 BPE 模型文件可使用 NetEncoder[{"SubwordTokens",File["path"],…}] 导入.
- SentencePiece 库中的词汇文件可使用选项 "Vocabulary"File["path"] 导入. 接受词汇的阈值可使用 "Vocabulary"{File["path"],"Threshold"value} 来指定,其中 value 是一个数字. 如果没有指定阈值则会导入整个词汇.
- SentencePiece BPE 词汇文件将整数分数与每个词元关联在一起. 每个词元的分数与其在训练数据中的频率关联在一起,最频繁出现的词元的分数为零,其他词元的分数为负整数. 通过将子选项 "Threshold" 设置为数字 n,词汇表只接受分数至少为 n 的词元.
- 当导入 SentencePiece BPE 模型文件时,任何参数规范都会覆盖文件中的设置(如有).
参数
从 SentencePiece 中导入 BPE 模型
范例
打开所有单元关闭所有单元参数 (10)
"CombineWhitespace" (1)
导入 SentencePiece BPE 模型并覆盖其 "CombineWhitespace" 设置:
该模型的默认设置为 "CombineWhitespace"->True:
"IncludeTerminalTokens" (1)
SentencePiece BPE 模型默认情况下不包括终端词元. 导入模型并启用 "IncludeTerminalTokens":
对字符的字符串进行编码. 现在可以生成 StartOfString 和 EndOfString 词元:
"OutputProperties" (1)
"TargetLength" (1)
导入 SentencePiece BPE 模型并指定该序列应被填充或裁剪至 12 个元素的长度:
对字符的字符串进行编码. 少于 12 个元素的输出使用 EndOfString 词元进行填充:
"TextPreprocessing" (1)
"UnicodeNormalization" (1)
"Vocabulary" (2)
"WhitespacePadding" (1)
导入 SentencePiece BPE 模型并覆盖其 "WhitespacePadding" 设置:
此模型的默认设置是 "WhitespacePadding"Left,该设置插入一个前导空格,为标记 "great" 创建一个匹配项:
应用 (1)
将一个对影评片段分类为 "positive" 或 "negative" 的分类器进行训练. 首先,获取训练和检验数据:
使用 NetModel,使用 Wolfram 神经网络资源库中的 "SubwordTokens" 编码器获取一个 EmbeddingLayer:
使用嵌入定义一个将单词字符串作为输入并返回 "positive" 或 "negative" 的网络:
对该网络进行五个回合的训练. 使用选项 LearningRateMultipliers 保持 EmbeddingLayer 的权重不变: