

FindImageText
FindImageText[image]
image 中のテキストを検出し,境界ボックスを1つ返す.
FindImageText[image,level]
指定された構造レベルにおける境界ボックスのリストを返す.
FindImageText[image,level,prop]
指定されたレベルのテキストの prop を返す.
FindImageText[video,…]
video のフレーム中のテキストを検出する.
詳細とオプション



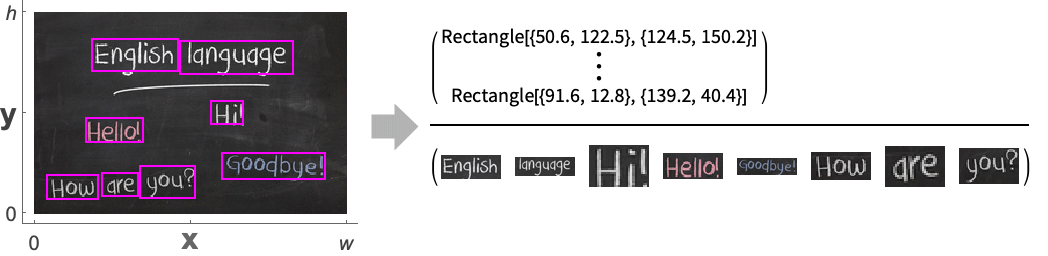
- FindImageTextを使ってテキストを含む画像の部分を検出する.特定の構造レベルを要求すると,それぞれがParallelogramとして与えられる境界ボックスのリストが返される.
- 座標{x,y}は標準的な画像座標系であると仮定される.
- TextRecognizeを使って検出されたテキストの内容を認識する.
- 次は,level の可能な設定である.
-
Automatic 画像全体の中で見付かったテキストを単一の結果として(デフォルト) "Block" テキストの各ブロックについての結果のリスト "Line" 各行についての結果のリスト "Word" 各単語についての結果のリスト "Character" 各文字についての結果のリスト - 次は prop の可能な設定である.
-
"AlignedImage" 検出された各テキストを含む切り取られ整列された画像 "BoundingBox" 検出された各テキストの周りのRectangleとしての境界ボックス "BoundingBoxArea" 各テキストの周りの境界ボックスの面積 "Confidence" 認識されたテキストの強度 "DeskewAngle" 検出されたテキストの歪み調整角度 "Image" 検出されたテキストを含む切取り画像 "OrientedBoundingBox" 検出された各テキストの周りの平行四辺形(デフォルト) "RegionCentroid" テキストの周りの境界ボックスの重心 {prop1,prop2,…} 特性のリスト - 次は,使用可能なオプションである.
-
AcceptanceThreshold Automatic 検出の受容閾値 MaxFeatures All 返すテキストボックスの数 MaxOverlapFraction Automatic 許容される最大のオーバーラップ Method Automatic 使用するメソッド PaddingSize 0 各検出項目の周りの充填量 - 次は,Methodの可能な設定である.
-
Automatic メソッドの自動選択 "Document" スキャンされたドキュメントからの検出に最適化 "NaturalScene" 自然の場面における画像からの検出に最適化 detector 使用するテキスト検出法 - 次は,detector の可能な設定である.
-
"DBNet" 微分可能な二値化ネット "Tesseract" Tesseractエンジン - FindImageTextは機械学習を使う.含まれるメソッド,訓練集合,バイアスは,Wolfram言語のバージョンによって異なることがあり,与えられる結果も異なる可能性がある.
- FindImageTextはリソースをダウンロードすることがある.ダウンロードされたリソースは,$LocalBaseのローカルなオブジェクトストアに保存され,LocalObjects[]でリストしたりResourceRemoveで削除したりできる.
例題
すべて開く すべて閉じるスコープ (8)
オプション (7)
MaxFeatures (1)
MaxFeatures30を使って検出強度が高いものから30個だけを返すようにする:
Method (3)
デフォルトで,FindImageTextは画像により適した検出メソッドを選択しようとする:
Method"NaturalScene"を使って自然な場面に存在するテキストを検出する:
スキャンされたドキュメントに対してMethod"Document"を使う:
PaddingSize (1)
PaddingSizes を使って検出された単語の境界ボックスの充填を指定する:
アプリケーション (1)
テキスト以外のコンテンツがたくさん含まれた画像に対して光学文字認識(OCR)を行うのは難しいかもしれない:
まずFindImageTextを使って画像を前処理する:
特性と関係 (3)
FindImageTextは方向に関係なくテキストを検出する:
FindImageTextを使って画像中のテキストコンテンツを検出する:
TextRecognizeを使って画像のコンテンツにOCRを行う:
FindImageTextを使って画像中のナンバープレートを検出する:
TextRecognizeを使ってナンバープレートを認識し,もとの画像中でハイライトする:
テキスト
Wolfram Research (2020), FindImageText, Wolfram言語関数, https://reference.wolfram.com/language/ref/FindImageText.html (2025年に更新).
CMS
Wolfram Language. 2020. "FindImageText." Wolfram Language & System Documentation Center. Wolfram Research. Last Modified 2025. https://reference.wolfram.com/language/ref/FindImageText.html.
APA
Wolfram Language. (2020). FindImageText. Wolfram Language & System Documentation Center. Retrieved from https://reference.wolfram.com/language/ref/FindImageText.html