

FindImageText
FindImageText[image]
检测 image 中的文字并返回一个边界框.
FindImageText[image,level]
返回指定结构层次的边界框列表.
FindImageText[image,level,prop]
返回给定层次的文字的 prop.
FindImageText[video,…]
检测 video各帧中的文字.
更多信息和选项


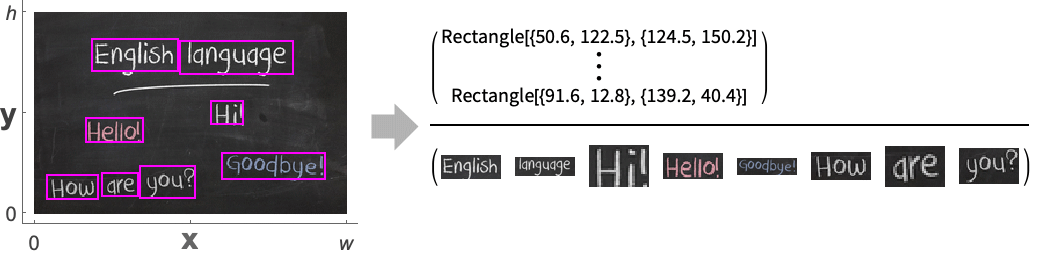
- FindImageText 用于检测包含文字的图像区域. 当要求特定的结构层次时,它将返回边界框列表,每个边界框均以 Parallelogram 给出.
- 假设坐标 {x,y} 位于标准图像坐标系中.
- 用 TextRecognize 识别检测到的文字的内容.
- level 的可能设置包括:
-
Automatic 将在整个图像中找到的文字作为一个结果(默认) "Block" 检测到的每个字块的列表 "Line" 检测到的每行文字的列表 "Word" 检测到的每个单词的列表 "Character" 检测到的每个字符的列表 - prop 的可能设置包括:
-
"AlignedImage" 含有每个检测到的文字的剪切好的对齐的图像 "BoundingBox" 以 Rectangle 给出的包围每个检测到的文字的边界框 "BoundingBoxArea" 包围每个检测到的文字的边界框的面积 "Confidence" 识别出的文字的强度 "DeskewAngle" 检测到的文字的偏斜校正角 "Image" 含有检测到的文字的剪切好的图像 "OrientedBoundingBox" 包围每个检测到的文字的平行四边形(默认) "RegionCentroid" 文本周围的边界框的质心 {prop1,prop2,…} 属性列表 - 可指定以下选项:
-
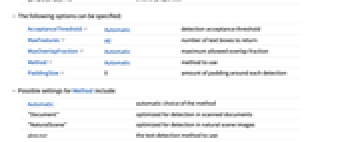
AcceptanceThreshold Automatic 检测可接受阈值 MaxFeatures All 返回的文本框的数量 MaxOverlapFraction Automatic 允许的最大重叠的程度 Method Automatic 使用的方法 PaddingSize 0 每个检测结果周围的填充量 - Method 的可能设置包括:
-
Automatic 自动选择方法 "Document" 最适宜于在扫描文档中检测的方法 "NaturalScene" 最适宜于在自然场景图像中检测的方法 detector 使用的文本检测方法 - detector 的可能设置有:
-
"DBNet" 可微分二值化网络 "Tesseract" 魔方(Tesseract)引擎 - FindImageText 使用机器学习. 在不同版本的 Wolfram 语言中,其方法、训练集和偏差可能会改变并给出不同的结果.
- FindImageText 可下载一些资源,保存在 $LocalBase 的本地对象存储库 (local object store) 中,可用 LocalObjects[] 显示,用 ResourceRemove 移除.
范例
打开所有单元 关闭所有单元范围 (8)
选项 (7)
MaxFeatures (1)
用 MaxFeatures30 只返回 30 个最可靠的检测:
Method (3)
默认情况下,FindImageText 会选择更适合图像的检测方法:
用 Method"NaturalScene" 检测自然场景中出现的文本:
用 Method"Document" 处理扫描的文档:
PaddingSize (1)
应用 (1)
属性和关系 (3)
无论方位如何,FindImageText 都可以检测出文本:
FindImageText 用于检测图像中的文本内容:
用 TextRecognize 在图像上进行 OCR:
用 FindImageText 检测图像中的车牌:
用 TextRecognize 识别车牌并在原始图像中突出显示:
文本
Wolfram Research (2020),FindImageText,Wolfram 语言函数,https://reference.wolfram.com/language/ref/FindImageText.html (更新于 2025 年).
CMS
Wolfram 语言. 2020. "FindImageText." Wolfram 语言与系统参考资料中心. Wolfram Research. 最新版本 2025. https://reference.wolfram.com/language/ref/FindImageText.html.
APA
Wolfram 语言. (2020). FindImageText. Wolfram 语言与系统参考资料中心. 追溯自 https://reference.wolfram.com/language/ref/FindImageText.html 年