HistogramDistribution
HistogramDistribution[{x1,x2,…}]
表示与数据值 xi 的直方图对应的概率分布.
HistogramDistribution[{{x1,y1,…},{x2,y2,…},…}]
表示基于数据值 {xi,yi,…} 的多变量直方图分布.
HistogramDistribution[…,bspec]
表示分组方法由 bspec 指定的直方图分布.
更多信息

- HistogramDistribution 返回 DataDistribution 对象,用法和任意其它概率分布一样.
- 值
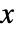 的 HistogramDistribution 的概率密度函数由
的 HistogramDistribution 的概率密度函数由 ![sum_(j=1)^m(c_j)/(n m_j) Boole[b_(j-1)<=x<b_j]](Files/HistogramDistribution.zh/2.png "sum_(j=1)^m(c_j)/(n m_j) Boole[b_(j-1)<=x<b_j]") 给出,其中
给出,其中 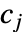 为直方条
为直方条 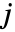 中的数据点个数,
中的数据点个数,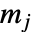 为直方条
为直方条 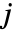 的宽度,
的宽度,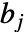 为分组界限值,
为分组界限值,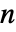 为数据点的总数.
为数据点的总数. - 各箱
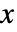 方向的宽根据值 xi 计算,
方向的宽根据值 xi 计算,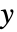 方向的宽度根据值 yi 计算,依此类推.
方向的宽度根据值 yi 计算,依此类推. - 可以给出下列分组规范 bspec:
-
n 分成 n 组 {w} 组距为 w {min,max,w} 在 min 到 max 的范围内使用宽度为 w 的直方条 {{b1,b2,…}} 使用界限值 [b1,b2),[b2,b3),… 分组 Automatic 自动确定组距 "name" 使用已命名的分组方法 fw 应用 fw 以得到明确的分组规定 {b1,b2,…} {xspec,yspec,…} 给出不同的 x、y 等的规范 - 可能的已命名的分组方法包括:
-
"FreedmanDiaconis" 四分间距的两倍除以样本大小的立方根 "Knuth" 平衡分段均匀模型的似然值和先验概率 "Scott" 渐近最小化均方误差 "Sturges" 根据数据长度计算组数 "Wand" 一级递归近似 Wand 分组方法 - 在直方图分布中,值
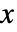 的概率密度为分段常数函数.
的概率密度为分段常数函数. - HistogramDistribution 可以与 Mean、CDF 和 RandomVariate 等函数配合使用.
范例
打开所有单元关闭所有单元范围 (29)
基本用途 (5)
分布属性 (10)
与 HistogramDistribution 比较:
应用 (6)
利用 Knuth 方法、Scott 规则和 Freedman-Diaconis 规则的密度估计:
Knuth 方法在 LogLikelihood 上的性能超过其它两个:
HistogramDistribution 的累积分布函数是分段线性的:
属性和关系 (10)
HistogramDistribution 的 PDF 等价于概率密度的 Histogram:
CDF 与 SurvivalFunction 是分段线性函数:
HazardFunction 是线性分式函数:
HistogramDistribution 是均匀分布的 MixtureDistribution:
HistogramDistribution 是底层分布的相容估计量:
当输入是 TimeSeries 时 HistogramDistribution 只能用于数值:
当输入是 TemporalData 时 HistogramDistribution 适用于所有的值:
巧妙范例 (1)
采用 HistogramDistribution 的随机波普艺术:
文本
Wolfram Research (2010),HistogramDistribution,Wolfram 语言函数,https://reference.wolfram.com/language/ref/HistogramDistribution.html (更新于 2016 年).
CMS
Wolfram 语言. 2010. "HistogramDistribution." Wolfram 语言与系统参考资料中心. Wolfram Research. 最新版本 2016. https://reference.wolfram.com/language/ref/HistogramDistribution.html.
APA
Wolfram 语言. (2010). HistogramDistribution. Wolfram 语言与系统参考资料中心. 追溯自 https://reference.wolfram.com/language/ref/HistogramDistribution.html 年