"KMedoids" (机器学习方法)
- 用于 FindClusters、ClusterClassify 和 ClusteringComponents 的方法.
- 使用 k-medoids 聚类算法将数据划分为
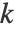 个由相似元素组成的聚类.
个由相似元素组成的聚类.
Details & Suboptions
- "KMedoids" 方法,也称为“围绕中心点的分区”(PAM),是一种简单快速的基于中心点的方法. 当聚类的大小相似且局部分布在其中心点(又称 medoids)周围时,"KMedoids" 效果很好. 当聚类的大小差异很大、相互交织或存在异常值时,"KMedoids" 可能会产生较差的结果.
- 下图展示了将 "KMedoids" 方法应用于玩具数据集的结果:
-

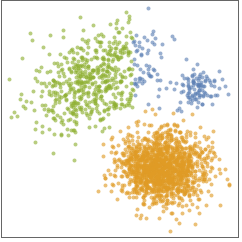
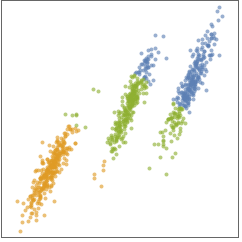

- "KMedoids" 方法旨在找到定义 k 个聚类的 k 个中心点. 每个数据点被分配给其最近的中心点. 所有分配给特定中心点的点形成一个聚类.
- 寻找最佳 k 个中心点的过程与 "KMeans" 相同,只是中心点不是定义为聚类的平均值. 相反,聚类中心点被定义为聚类中最中心的数据点,即与聚类中其他点的平均距离最小的数据点. 由于 "KMedoids" 不像 "KMedoids" 那样计算平均值,它可以在非数值空间中使用(只需要一个距离函数就足够了).
- 由于初始中心点是随机选择的,运算结果可能会有所不同.
- 子选项 "InitialCentroids" 可用于将初始中心点指定为数据点列表. 每个初始中心点必须与现有的数据点相匹配.
- 可以给出以下子选项:
-
"InitialCentroids" Automatic 初始中心点列表
范例
打开所有单元关闭所有单元基本范例 (3)
使用 "KMedoids" 聚类方法找到恰好四个邻近值的聚类:
在字符串列表上训练 ClassifierFunction:
选项 (3)
可能存在的问题 (1)
使用 "KMedoids" 方法为两个聚类训练 ClassifierFunction,并在测试集中查找聚类: