

ClusteringTree
ClusteringTree[{e1,e2,…}]
constructs a weighted tree from the hierarchical clustering of the elements e1, e2, ….
ClusteringTree[{e1v1,e2v2,…}]
represents ei with vi in the constructed graph.
ClusteringTree[{e1,e2,…}{v1,v2,…}]
represents ei with vi in the constructed graph.
ClusteringTree[label1e1,label2e2…]
represents ei using labels labeli in the constructed graph.
ClusteringTree[data,h]
constructs a weighted tree from the hierarchical clustering of data by joining subclusters at distance less than h.
Details and Options
- ClusteringTree creates a Tree object showing how data points cluster together hierarchically.
- The data elements ei can be numbers; numeric lists, matrices, or tensors; lists of Boolean elements; strings or images; geo positions or geographical entities; colors; as well as combinations of these. If the ei are lists, matrices, or tensors, each must have the same dimensions.
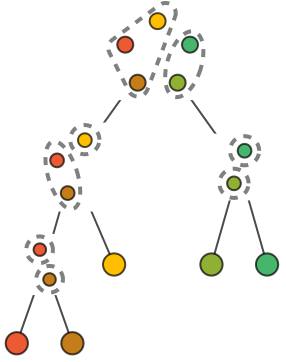
- The result from ClusteringTree is a binary weighted tree, where the weight of each vertex indicates the distance between the two subtrees that have that vertex as root:
- ClusteringTree has the same options as Graph, with the following additions and changes: [List of all options]
-
ClusterDissimilarityFunction Automatic the clustering linkage algorithm to use DistanceFunction Automatic the distance or dissimilarity to use EdgeStyle GrayLevel[0.65] styles for edges FeatureExtractor Automatic how to extract features from data VertexSize 0 size of vertices - By default, ClusteringTree will preprocess the data automatically unless either a DistanceFunction or a FeatureExtractor is specified.
- ClusterDissimilarityFunction defines the intercluster dissimilarity, given the dissimilarities between member elements.
- Possible settings for ClusterDissimilarityFunction include:
-
"Average" average intercluster dissimilarity "Centroid" distance from cluster centroids "Complete" largest intercluster dissimilarity "Median" distance from cluster medians "Single" smallest intercluster dissimilarity "Ward" Ward's minimum variance dissimilarity "WeightedAverage" weighted average intercluster dissimilarity a pure function - The function f defines a distance from any two clusters.
- The function f needs to be a real-valued function of the DistanceMatrix.
List of all options
Examples
open all close allBasic Examples (5)
Obtain a cluster hierarchy from a list of numbers:
ClusteringTree[{1, 2, 5}]Unify clusters at distance less than 2:
ClusteringTree[{1, 2, 5}, 1.3]Obtain a cluster hierarchy from a list of strings:
ClusteringTree[{"a", "abba", "ababa", "abcdefg"}]Obtain a cluster hierarchy from a list of images:
ClusteringTree[{[image], [image], [image], [image]}]Obtain a cluster hierarchy from a list of cities:
ClusteringTree[{Entity["City", {"Paris", "IleDeFrance", "France"}], Entity["City", {"Sydney", "NewSouthWales", "Australia"}], Entity["City", {"Boston", "Massachusetts", "UnitedStates"}], Entity["City", {"SanFrancisco", "California", "UnitedStates"}]}]Obtain a cluster hierarchy from a list of Boolean entries:
ClusteringTree[{{False, False}, {True, False}, {True, True}}]Scope (8)
Obtain a cluster hierarchy from a list of numbers:
g = ClusteringTree[{0.1, 2.2, 3.4, 5.6, 8.9}]AnnotationValue[g, "LeafLabels"]Look at the distance between subclusters by looking at the VertexWeight:
AnnotationValue[g, VertexWeight]Find the shortest path from the root vertex to the leaf 3.4:
FindShortestPath[g, 1, 7 ]Obtain a cluster hierarchy from a heterogeneous dataset:
data = {{RGBColor[0.3882530591983919, 0.2972372289203644, 0.14662872236042124], "brown"}, {RGBColor[0.3134110772018093, 0.6577487501778145, 0.7061181487042973], "light blue"}, {RGBColor[0.31684543929904985, 0.32154575812724917, 0.8496239355766027], "blue"}, {RGBColor[0.5443420548178017, 0.4583234220657759, 0.8094937667804043], "violet"}, {RGBColor[0.4274650545373566, 0.9072941688093845, 0.898117681435409], "light blue"}, {RGBColor[0.9323469092538643, 0.8301659871869203, 0.4534352919547222], "yellow"}, {RGBColor[0.7518445360980579, 0.05631287374652039, 0.6430690822523268], "light violet"}};ClusteringTree[data]Compare it with the cluster hierarchy of the colors:
ClusteringTree[data[[All, 1]]]Generate a list of random colors:
data = RandomColor[20]Obtain a cluster hierarchy from the list using the "Centroid" linkage:
ClusteringTree[data, ClusterDissimilarityFunction -> "Centroid"]Compute the hierarchical clustering from an Association:
association = <|"Red" -> RGBColor[0.7355420127983632, 0.2464091158003272, 0.1318671396857256], "Blue" -> RGBColor[0.19595271830233885, 0.10998208611256777, 0.5195988419509086], "Pink" -> RGBColor[0.98714064424384, 0.4517971556938676, 0.7345757642205208], "Yellow" -> RGBColor[0.914802573832932, 0.9472567075421043, 0.19573643015491093]|>;ClusteringTree[association]Compare it with the hierarchical clustering of its Values:
ClusteringTree[Values[association]]Compare it with the hierarchical clustering of its Keys:
ClusteringTree[Keys[association]]Obtain a cluster hierarchy by merging clusters at distance less than 0.4:
data = RandomColor[20]ClusteringTree[data, 0.4, ClusterDissimilarityFunction -> "Centroid"]Change the style and the layout of the ClusteringTree:
data = RandomInteger[{0, 100}, 50];disk = Graphics[{GrayLevel[.45], Disk[]}]ClusteringTree[data, VertexSize -> 0.2, VertexShape -> disk]ClusteringTree[data, GraphLayout -> "RadialEmbedding"]Obtain a cluster hierarchy from a list of three-dimensional vectors and label the leaves with the total of the corresponding element:
r = RandomReal[1, {7, 3}];g = ClusteringTree[r -> Total /@ r]Compare it with the cluster hierarchy of the total of each vector:
ClusteringTree[Total /@ r]Obtain a cluster hierarchy from a list of integers:
data = RandomSample[Range[3, 10], 6];g = ClusteringTree[data]Change the vertex labels by using regular polygons:
labels = Graphics[{Blue, RegularPolygon[#]}, ImageSize -> 20]& /@ datag = ClusteringTree[data -> labels]Options (9)
ClusterDissimilarityFunction (1)
Generate a list of random colors:
data = RandomColor[80]Obtain a cluster hierarchy from the list using the "Centroid" linkage:
ClusteringTree[data, ClusterDissimilarityFunction -> "Centroid"]Obtain a cluster hierarchy from the list using the "Single" linkage:
ClusteringTree[data, ClusterDissimilarityFunction -> "Single"]Obtain a cluster hierarchy from the list using a different "ClusterDissimilarityFunction":
ClusteringTree[data, ClusterDissimilarityFunction -> (Max[#]&)]DistanceFunction (1)
Generate a list of random vectors:
data = RandomReal[{10, 20}, {10, 2}];Obtain a cluster hierarchy using different DistanceFunction:
ClusteringTree[data, DistanceFunction -> ManhattanDistance]ClusteringTree[data, DistanceFunction -> ChessboardDistance]FeatureExtractor (1)
Obtain a cluster hierarchy from a list of pictures:
flowers = { [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image]};ClusteringTree[flowers]Use a different FeatureExtractor to extract features:
fe = FeatureExtraction[flowers, "ImageFeatures"]ClusteringTree[flowers, FeatureExtractor -> fe]Use the Identity FeatureExtractor to leave the data unchanged:
ClusteringTree[flowers, FeatureExtractor -> Identity]ImageSize (2)
Specify an explicit image size for the whole tree:
ClusteringTree[{1, 2, 5}, ImageSize -> Tiny]Independent settings for width and height affect the tree bounding box but not its aspect ratio:
ClusteringTree[{1, 2, 5}, ImageSize -> {300, 150}]//FramedSet both ImageSize and AspectRatio explicitly:
ClusteringTree[{1, 2, 5}, ImageSize -> {300, 150}, AspectRatio -> 150 / 300]VertexLabelStyle (4)
ClusteringTree[{3, 3, 5, 4, 7, 7}, VertexLabelStyle -> Large]ClusteringTree[{3, 3, 5, 4, 7, 7}, VertexLabelStyle -> Red]Customize several aspects of the labels:
ClusteringTree[{3, 3, 5, 4, 7, 7}, VertexLabelStyle -> Directive[Purple, Italic, 40]]Some expressions, like images, are not affected by FontSize:
images = {[image], [image], [image], [image]};ClusteringTree[images, VertexLabelStyle -> Tiny, ImageSize -> Small]Use Magnification to affect every type of expression:
ClusteringTree[images, VertexLabelStyle -> Directive[Magnification -> .3], ImageSize -> Small]Alternatively, provide explicit labels:
labels = ColorConvert[ImageResize[#, {Automatic, 40}], "Grayscale"]& /@ imagesClusteringTree[images -> labels, ImageSize -> Small]Text
Wolfram Research (2016), ClusteringTree, Wolfram Language function, https://reference.wolfram.com/language/ref/ClusteringTree.html (updated 2017).
CMS
Wolfram Language. 2016. "ClusteringTree." Wolfram Language & System Documentation Center. Wolfram Research. Last Modified 2017. https://reference.wolfram.com/language/ref/ClusteringTree.html.
APA
Wolfram Language. (2016). ClusteringTree. Wolfram Language & System Documentation Center. Retrieved from https://reference.wolfram.com/language/ref/ClusteringTree.html