"LatentSemanticAnalysis" (機械学習メソッド)
- DimensionReduction,DimensionReduce,FeatureSpacePlot,FeatureSpacePlot3Dのためのメソッドである.
- 潜在的意味解析法を使ってデータを低次元空間にマッピングする.
詳細とサブオプション
- "LatentSemanticAnalysis"は線形次元削減法である.このメソッドは,データ点間の意味的連想を保持しようとする低次元空間に入力データを投影する.
- "LatentSemanticAnalysis"は多数の特徴を持つ,あるいは多数の例があるデータ集合に使うことができ,特に(ほとんどの値が0である)疎なデータ集合に対してうまく働く."LatentSemanticAnalysis"は,検索語・文書行列(文書内の語数)の次元削減によく使われる.
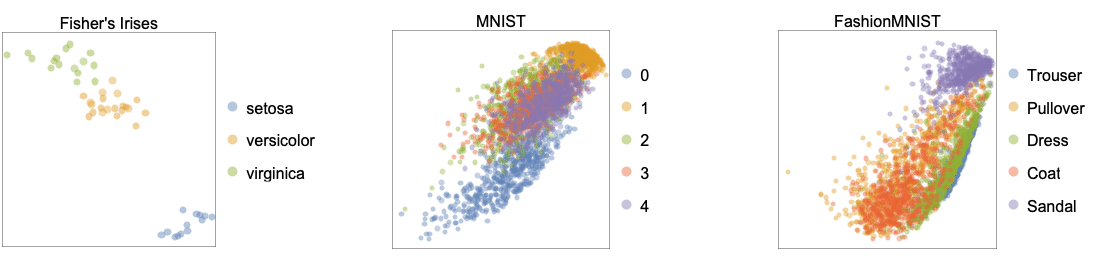
- 次のプロットは"LatentSemanticAnalysis"メソッドをベンチマーキングデータ集合のFisher's Irises,MNIST,FashionMNISTに適用した結果である.
- "LatentSemanticAnalysis"は,データが中央に配置されていない点を除いて"Linear"と"PrincipalComponentsAnalysis"に等しい.
- このメソッドは,検索エンジンを作成するための情報検索に広く使われている.このメソッドは自然言語処理におけるテキストの分類やトピックのモデル化にも使われている.
例題
すべて開くすべて閉じるスコープ (1)
データ集合の可視化 (1)
フィッシャー(Fisher)の「アヤメ」のデータ集合をExampleDataからロードする: