"LatentSemanticAnalysis" (机器学习方法)
"LatentSemanticAnalysis" (机器学习方法)
- 用于 DimensionReduction、DimensionReduce、FeatureSpacePlot 和 FeatureSpacePlot3D 的方法.
- 使用潜在语义分析方法将数据映射到低维空间.
详细信息和子选项
- "LatentSemanticAnalysis" 是一种线性降维方法. 该方法将输入数据投影到低维空间中,尝试保留数据点之间的语义关联.
- "LatentSemanticAnalysis" 适用于具有大量特征或大量示例的数据集,尤其适用于稀疏数据集(大多数值为零). "LatentSemanticAnalysis" 通常用于降低术语文档矩阵的维数(文档中的术语计数).
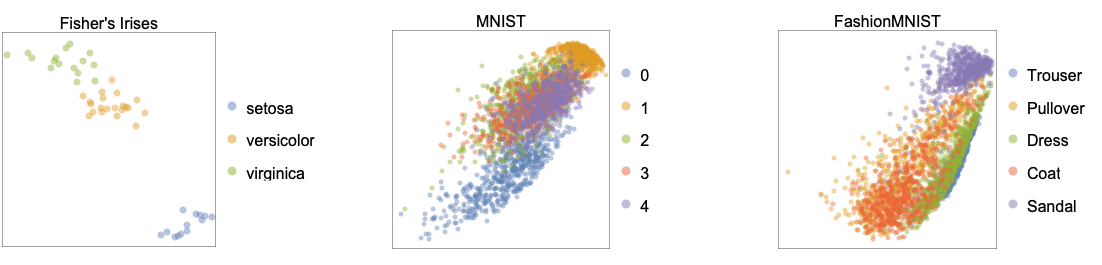
- 下图显示了 "LatentSemanticAnalysis" 方法应用于基准数据集(Fisher's Irises、MNIST 和 FashionMNIST)的结果:
- "LatentSemanticAnalysis" 等效于 "Linear" 和 "PrincipalComponentsAnalysis" 方法,但数据不居中.
- 该方法广泛用于信息检索以创建搜索引擎. 该方法还用于文本分类和主题建模等任务的自然语言处理.
范例
打开所有单元 关闭所有单元范围 (1)
数据集可视化 (1)
从 ExampleData 加载 Fisher Iris 数据集: