"MultidimensionalScaling" (机器学习方法)
"MultidimensionalScaling" (机器学习方法)
- 用于 DimensionReduction、DimensionReduce、FeatureSpacePlot 和 FeatureSpacePlot3D 的方法.
- 使用度量多维尺度降低数据的维度.
Details & Suboptions
- "MultidimensionalScaling" 是一种基于距离的非线性降维方法. 该方法试图通过保持数据点之间的成对距离来找到数据的低维嵌入.
- "MultidimensionalScaling" 能够学习非线性流形;然而,当样本数量很大时,它可能会变得较慢.
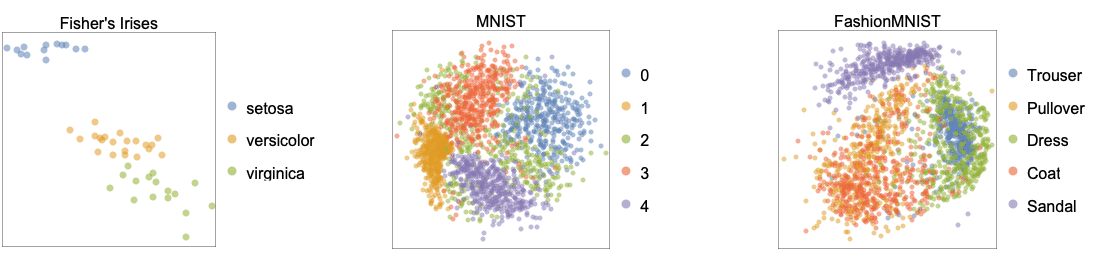
- 以下图表展示了 "MultidimensionalScaling" 方法应用于基准数据集 Fisher's Irises、MNIST 和 FashionMNIST 后学习到的二维嵌入:
- 给定原始空间中数据点的距离矩阵
") ,"MultidimensionalScaling" 试图找到低维嵌入
,"MultidimensionalScaling" 试图找到低维嵌入 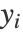 ,使得在低维空间中的距离与原始空间中数据点之间的距离相匹配,即
,使得在低维空间中的距离与原始空间中数据点之间的距离相匹配,即 yi-yj
yi-yj ≈
≈ ") . 低维嵌入
. 低维嵌入 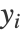 通过最小化以下嵌入成本来计算: ∑i,j [
通过最小化以下嵌入成本来计算: ∑i,j [ yi-yj
yi-yj -
- ") ]2.
]2. - 可以给出以下子选项:
-
MaxIterations Automatic 优化步骤的最大次数 "MinRelativeChange" Automatic 成本值的最小相对变化,以继续优化过程
范例
打开所有单元 关闭所有单元基本范例 (2)
范围 (1)
数据集可视化 (1)
从 ExampleData 加载 Fisher Iris 数据集:
选项 (1)
MaxIterations (1)
使用 "MultidimensionalScaling" 降低图像的维度:
使用不同的 MaxIterations 选项查找降维后的特征: