"SubwordTokens" (Net Encoder)
NetEncoder[{"SubwordTokens",{token1,token2,…}}]
represents an encoder that segments text into subwords from a given vocabulary.
NetEncoder[{"SubwordTokens",File["path"]}]
loads a SentencePiece BPE model from a file.
NetEncoder[{"SubwordTokens",…,"param"value}]
represents an encoder in which additional parameters have been specified.
Details



- Subword tokenization is a scheme between word-level and character-level tokenizations, in which tokens are either full words or word subparts.
- The output of the encoder is a sequence of integers between 1 and d, where d is the number of elements in the token list.
- NetEncoder[…][input] applies the encoder to a string to produce an output.
- NetEncoder[…][{input1,input2,…}] applies the encoder to a list of strings to produce a list of outputs.
- An encoder can be attached to an input port of a net by specifying "port"->NetEncoder[…] when constructing the net.
- NetDecoder[NetEncoder[{"SubwordTokens",…}]] produces a NetDecoder[{"SubwordTokens",…}] with settings inherited from those of the given encoder.
- In NetEncoder[{"SubwordTokens",{token1,token2,…},…}], each token must be a string or one of these special tokens:
-
StartOfString virtual token that occurs before the beginning of the string EndOfString virtual token that occurs after the end of the string _ any unassigned character - By convention, tokens starting a word correspond to strings with a space first (like " word") and tokens within a word correspond to strings with any other character first (like "tion").
- The list of tokens must always include the unassigned character _.
- With parameter "IncludeTerminalTokens"True, it must also include StartOfString and EndOfString.
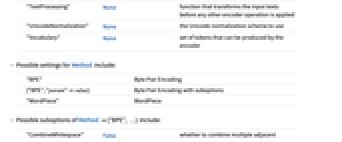
- The following parameters are supported:
-
IgnoreCase False whether to ignore case when matching tokens from the string "IncludeTerminalTokens" False whether to include the StartOfString and EndOfString tokens in the output "InputType" "String" format of each input to the encoder Method "BPE" algorithm to segment text into subwords "OutputProperties" "VocabularyIndex" property to output for each subword token "TargetLength" All length of the final sequence to crop or pad to "TextPreprocessing" None function that transforms the input texts before any other encoder operation is applied "UnicodeNormalization" None the Unicode normalization scheme to use "Vocabulary" None set of tokens that can be produced by the encoder - Possible settings for Method include:
-
"BPE" Byte Pair Encoding {"BPE","param"value} Byte Pair Encoding with suboptions "WordPiece" WordPiece - Possible suboptions of Method{"BPE", …} include:
-
"CombineWhitespace" False - whether to combine multiple adjacent whitespace characters
"WhitespacePadding" None control the insertion of whitespace to the input string - The parameter "WhitespacePadding" can be set to Left or Right to add a whitespace to the beginning or to the end of the input string, respectively, before encoding. The default value, None, does not insert additional whitespace.
- The following settings for the parameter "InputType" are available:
-
"ListOfStrings" each input text is represented by a list of strings "String" each input text is represented by a string - The following settings for the parameter "OutputProperties" are available:
-
"VocabularyIndex" index of the token in the list of tokens (default) "InputIndex" index of the string that includes the token (can be different from 1 with "InputType""ListOfStrings") "StartPosition" starting position of the token in the text "EndPosition" ending position of the token in the text {prop1,prop2,…} a list of valid properties - With the default parameter setting "TargetLength"->All, all tokens found in the input string are encoded.
- With the parameter "TargetLength"->n, the first n tokens found in the input string are encoded, with padding applied if fewer than n tokens are found. If EndOfString is present in the token list, the padding value is the integer code associated with it; otherwise, the code associated with the last token is used.
- The possible settings for "UnicodeNormalization" include Unicode normalization forms of CharacterNormalize:
-
"NFD" canonical decomposition (Form D) "NFC" canonical decomposition, followed by canonical composition (Form C) "NFKD" compatibility decomposition (Form KD) "NFKC" compatibility decomposition, followed by canonical composition (Form KC) None no normalization - A vocabulary can be specified as a list of token strings using option "Vocabulary"{token1,token2,…}. If a vocabulary is specified, integer codes of tokens not present in the vocabulary will not be produced by the encoder. With Method"BPE", in case the tokenization produces an out-of-vocabulary token, operations that produced that token will be reversed until the token is split into either in-vocabulary tokens or single characters.
- A BPE model file from the SentencePiece library can be imported using NetEncoder[{"SubwordTokens",File["path"],…}].
- A vocabulary file from the SentencePiece library can be imported using option "Vocabulary"File["path"]. A threshold for acceptance of vocabulary tokens can be specified using "Vocabulary"{File["path"],"Threshold"value} where value is a number. The entire vocabulary will be imported if no threshold is specified.
- SentencePiece BPE vocabulary files associate an integer score to each token. The score of each token is associated to its frequency in the training data, with the most frequent token having a score of zero and other tokens having a negative integer score. By setting the suboption "Threshold" to a number n, only tokens with a score of at least n are accepted in the vocabulary.
- When importing a SentencePiece BPE model file, any parameter specification will override settings from the file (if present).
Parameters
Importing a BPE Model from SentencePiece
Examples
open all close allBasic Examples (1)
Scope (1)
Parameters (10)
"CombineWhitespace" (1)
Import a SentencePiece BPE model and override its "CombineWhitespace" setting:
Encode a string of characters. Multiple whitespace characters are not combined into one before encoding:
The default setting for this model is "CombineWhitespace"->True:
IgnoreCase (1)
"IncludeTerminalTokens" (1)
SentencePiece BPE models do not include terminal tokens by default. Import a model and enable "IncludeTerminalTokens":
Encode a string of characters. StartOfString and EndOfString tokens are now produced:
"OutputProperties" (1)
"TargetLength" (1)
Import a SentencePiece BPE model and specify that the sequence should be padded or trimmed to be 12 elements long:
Encode a string of characters. Outputs with fewer than 12 elements are padded with the EndOfString token:
"TextPreprocessing" (1)
"UnicodeNormalization" (1)
Import a SentencePiece BPE model that does not perform any Unicode normalization:
This model encodes the capital omega character, whose Unicode decimal is 937, to ID 29:
The ohm symbol, identified by the Unicode decimal 8486, is not recognized and is encoded to the unknown token, whose ID for this model is 1:
By specifying a Unicode normalization setting for the model, the ohm character is normalized to a capital omega before encoding:
"Vocabulary" (2)
Create a BPE encoder from a SentencePiece BPE model and vocabulary files:
Encode a string of characters with the vocabulary constraint:
The word "world" is segmented into subwords because it is not in the vocabulary:
Import a BPE model with a vocabulary and specify a vocabulary threshold:
Encode a string of characters:
No compound token will be produced due to the vocabulary restriction:
"WhitespacePadding" (1)
Import a SentencePiece BPE model and override its "WhitespacePadding" setting:
Encode a string of characters. The initial word "great" is segmented into subwords:
The default setting for this model is "WhitespacePadding"Left, which inserts a leading whitespace, creating a match for the token "great":
Applications (1)
Train a classifier that classifies movie review snippets as "positive" or "negative". First, obtain the training and test data:
Using NetModel, obtain an EmbeddingLayer using a "SubwordTokens" encoder from the Wolfram Neural Net Repository:
Use the embeddings to define a net that takes a string of words as input and returns either "positive" or "negative":
Train the net for five training rounds. Keep the weights of the EmbeddingLayer fixed using the option LearningRateMultipliers:
Evaluate the trained net on a example from the test set, obtaining the probabilities: