NIntegrate積分ストラテジー
はじめに
積分ストラテジーとは,ユーザ指定の目標精度あるいは目標確度を満足する積分推定値を計算しようと試みるアルゴリズムである.
積分ストラテジーは,通常初期積分領域の非隣接部分領域集合の新しい要素を生成し管理する方法を指示する.それぞれの部分領域にはそれ自体の被積分関数とそれに関連付けられた積分則がある場合がある.積分推定値はすべての部分領域の積分推定値の総和である.積分ストラテジーは積分則を使い,部分領域の積分推定値を計算する.積分則はサンプル点(または分点)と呼ばれる点の集合における被積分関数をサンプリングする.
積分推定値を向上させるためには,被積分関数をもっと多くの点でサンプリングしなければならない.それには2つの主な方法がある.(i)1つ目は適応型ストラテジーと言い,これは問題のある積分部分を見付け,それに対して計算努力(サンプル点)を集中させる.(ii)2つ目は非適応型ストラテジーで,領域全体のサンプル点の数を多くし,以前の積分推定値の被積分関数の評価を再利用する,高次の積分則推定値を計算するものである.
どちらのアプローチも,より速く収束させるために記号的前処理,変数変換あるいはシーケンス総和加速を使うことができる.
セクション「適応型ストラテジー」には,適応型ストラテジーの一般的な説明がある.NIntegrateのデフォルト(主)ストラテジーは"GlobalAdaptive"であり,これについては「大域的適応型ストラテジー」で説明している.これと相補的であるのが「局所的適応型ストラテジー」で説明している局所的適応型ストラテジーである.どちらの適応型ストラテジーも「特異点処理」で説明する特異点処理メカニズムを使用する.
モンテカルロストラテジーは,セクション「単純モンテカルロ法と準モンテカルロ法」および「大域的適応型モンテカルロストラテジーと準モンテカルロストラテジー」で説明してある.
| "GlobalAdaptive" | 任意の被積分関数,適応型サンプリング,規則ベース |
| "LocalAdaptive" | 任意の被積分関数,適応型サンプリング,規則ベース |
| "DoubleExponential" | 任意の被積分関数,一様サンプリング |
| "Trapezoidal" | 任意の被積分関数,一様サンプリング |
| "MultiPeriodic" | 多次元被積分関数,一様サンプリング |
| "MonteCarlo" | 任意の被積分関数,一様ランダムサンプリング |
| "QuasiMonteCarlo" | 任意の被積分関数,一様擬似乱数サンプリング |
| "AdaptiveMonteCarlo" | 任意の被積分関数,適応型乱数サンプリング |
| "AdaptiveQuasiMonteCarlo" | 任意の被積分関数,適応型擬似乱数サンプリング |
| "DoubleExponentialOscillatory" | 一次元無限範囲の振動被積分関数 |
| "ExtrapolatingOscillatory" | 一次元無限範囲の振動被積分関数 |
NIntegrateの積分ストラテジー
NIntegrateは特殊な型の積分(あるいは被積分関数)に対して,一定のプリプロセッサストラテジーを使う.これについてはそれぞれ「Duffyの座標ストラテジー」,「振動ストラテジー」,「コーシー(Cauchy)の主値積分」で説明する.プリプロセッサストラテジーもまた被積分関数の記号的前処理を扱う.
| "SymbolicPreprocessing" | 全体的なプリプロセッサ制御子 |
| "EvenOddSubdivision" | 偶関数および奇関数の被積分関数を簡約化する |
| "InterpolationPointsSubdivision" | 補間関数を含む被積分関数を部分分割する |
| "OscillatorySelection" | 振動する被積分関数を検出し,適応したメソッドを選ぶ |
| "SymbolicPiecewiseSubdivision" | 区分関数を含む被積分関数を部分分割する |
| "UnitCubeRescaling" | 多次元の被積分関数を単位立方体に再スケールする |
| "DuffyCoordinates" | 多次元の特異点除去変換 |
| "PrincipalValue" | コーシー主値と等価の数値積分 |
NIntegrateのプリプロセッサストラテジー
適応型ストラテジー
適応型ストラテジーは,被積分関数が非連続であったり,被積分関数に他の種類の特異性がある部分に計算努力を集中させようとする.適応型ストラテジーは,積分領域を非隣接の部分領域に分割する方法が異なる.各部分領域の積分値は積分値全体に影響を与える.
適応型ストラテジーの基本的な前提は,指定された積分則 ![]() と被積分関数
と被積分関数 ![]() がある場合,積分領域
がある場合,積分領域 ![]() が2つの非隣接部分領域
が2つの非隣接部分領域 ![]() と
と ![]() (ここで
(ここで ![]() ,
,![]() )に分割されるならば,
)に分割されるならば,![]() と
と ![]() 上の
上の ![]() の積分推定値の総和は実際の積分
の積分推定値の総和は実際の積分 ![]() により近くなるということである.つまり
により近くなるということである.つまり
であり,(1)は ![]() および
および ![]() に対する誤差推定値の総和は
に対する誤差推定値の総和は ![]() の誤差推定値よりも小さいことを意味している.
の誤差推定値よりも小さいことを意味している.
したがって,適応型ストラテジーには以下のようなコンポーネントがある[MalcSimp75].
(ii) 領域集合![]() のどの要素を分割・部分分割するかを決定するメソッド
のどの要素を分割・部分分割するかを決定するメソッド
(iii) 適応型ストラテジーアルゴリズムをいつ終了するかを決定するための終了基準
大域的適応型ストラテジー
大域的適応型ストラテジーは最大誤差を持つ部分領域を2つに繰返し分割することにより,積分推定値の要求された目標精度および目標確度に到達し,二分されたそれぞれについて積分と誤差推定を計算する.
オプション名
|
デフォルト値
| |
| Method | Automatic | 各部分領域上の積分と誤差推定値を計算するために使われる積分則 |
| "SingularityDepth" | Automatic | 特異性ハンドラを適用する前の再帰的二分法の回数 |
| "SingularityHandler" | Automatic | 特異性ハンドラ |
| "SymbolicProcessing" | Automatic | 記号的前処理を行う秒数 |
"GlobalAdaptive"はNIntegrateのデフォルト積分ストラテジーである.これは一次元・多次元のどちらの積分に使うこともできる."GlobalAdaptive"はデカルト積規則と完全対称多次元則で使うことができる.
"GlobalAdaptive"はヒープと呼ばれるデータ構造を使い,ヒープの最上部が最大の誤差領域となるようにして,領域の集合を部分的にソートした状態に保つ.アルゴリズムのメインループでは,最大誤差領域は,その誤差のほとんどの原因であると推定される次元で二分される.
このアルゴリズムは,ノードが領域となる二分木の葉を生成すると言うことができる.ノード・領域の子は二分法の後得られる部分領域である.
まず領域を二分してそれぞれの領域で積分を計算し,もとの領域上での大域的積分値と大域的誤差推定をそれぞれ,二分木の葉である各領域上で積分値の和および誤差推定の和として計算する.
それぞれの領域には,それが生成されるために次元について何回の二分法が行われたかが記録されている.領域の生成に行われた二分法が多すぎると,特異点平滑化アルゴリズムが適用される.特異点の処理を参照のこと.
"GlobalAdaptive"は,以下の式が真の場合に中止される.
このストラテジーは,1つの領域の再帰的二分法の数が一定数を超えた場合(MinRecursionとMaxRecursionを参照)あるいは大域的積分誤差の振動が大きすぎる場合(MaxErrorIncreasesを参照)にも中止される.
理論的および実践的な証拠から,大域的適応型ストラテジーは一般に局所的適応型ストラテジーよりもパフォーマンスが勝ると言える[MalcSimp75][KrUeb98].
MinRecursionとMaxRecursion
再帰的二分法の最小および最大の深さは,オプションMinRecursionとMaxRecursionの値で指定する.
ある部分領域において,いずれかの次元の二分法の回数がMaxRecursionより大きくなると,"GlobalAdaptive"による積分は中止される.
MinRecursionを正の整数に指定することで,被積分関数が評価される前に積分領域の再帰的二分法を強制する.これは被積分関数の細く尖った部分を見逃さないようにするために行う(誤差推定器をごまかすを参照).
多次元積分の場合は,MinRecursionの再帰の各レベルに対して各次元の二分法をできるだけ行おうとする.
"MaxErrorIncreases"
(2)は"GlobalAdaptive"で有効であると想定されるため,最大誤差領域の二分割およびその新しい領域上での積分後,大域的誤差は減少すると想定される.換言すると,大域的誤差は多かれ少なかれ,積分ステップの数に対して単調に減少すると予想される.
大域的誤差は,積分則の位相誤差のために振動することがある.それでも大域的誤差はある点で単調に減り始めるものと想定される.
(ii) 指定された作業精度が,指定された目標精度に対して十分密ではない.

(iii) 積分条件が悪い[KrUeb98].例えば,被積分関数が複雑な式,または微分方程式や非線形代数方程式等の数学的問題の近似解で定義されている場合である.
"GlobalAdaptive"ストラテジーは,領域を最大の誤差推定値で二分した後に合計誤差推定が減少しなかった回数を記録している.その数が"GlobalAdaptive"のオプション"MaxErrorIncreases"を超えると,積分はメッセージ(NIntegrate::eincr)を出力して中止される.
"MaxErrorIncreases"のデフォルト値は一次元積分では400,多次元積分では2000である.

大域的適応型ストラテジーの実装例題
局所的適応型ストラテジー
積分推定値の要求精度および目標確度に達するために,局所的適応型ストラテジーは再帰的に部分領域をより小さい非隣接部分領域に分割し,それぞれに対する積分値と誤差推定値を計算する.
オプション名
|
デフォルト値
| |
| Method | Automatic | 部分領域上での積分値と誤差推定を計算するために使われる積分則 |
| "SingularityDepth" | Automatic | 特異点ハンドラを適用する前の再帰的二分法の回数 |
| "SingularityHandler" | Automatic | 特異点ハンドラ |
| "Partitioning" | Automatic | 積分推定値を向上させるために領域を分割する方法 |
| "InitialEstimateRelaxation" | True | 不必要な計算を避けるための初期積分推定値の大きさを調整しようとする試み |
| "SymbolicProcessing" | Automatic | 記号的前処理を実行する秒数 |
"GlobalAdaptive"と同様に,"LocalAdaptive"も一次元・多次元積分に使える."LocalAdaptive"は直積型積分則と多次元の完全対称積分則の両方で使える.
"LocalAdaptive"ストラテジーは,初期化ルーチンとRR(再帰ルーチン)を持つ.RRは木の葉を生成し,そのノードが領域となる.ノード・領域の子がその分割により得られる部分領域である.RRは引数として領域を取り,それに対する積分値を返す.
RRは積分則を使い,領域引数の積分値および誤差推定値を計算する.誤差推定値が大きすぎる場合,RRは分割により得られた隣接しない部分領域に対して自身を呼び出す.これらの再帰的呼出しから返される積分値の総和は,領域の積分値になる.
RRは,それが実行される領域の積分値および誤差推定のみが分かると,再帰の継続を決定する(こういうわけで,このストラテジーは「局所的適応型」と呼ばれる).
初期化ルーチンは,初期領域上の積分の初期推定値を計算する.この初期積分値はRRの中止基準で使用される.領域の誤差が初期積分値と比較して有意な場合,その領域は隣接しない領域に分割され,それに対してRRが呼ばれる.誤差が有意でなければ再帰は中止される.
ならば有意でないと見られる.中止基準(3)は作業精度まで積分を計算する.積分値をユーザ指定の目標精度あるいは目標確度まで計算するために,次の中止基準が使われる.
ここでepsは作業精度において1+eps≠1となるような最小の数であり,pgとagはユーザ指定の目標精度および確度である.
"LocalAdaptive"の再帰的ルーチンは,次の場合に中止される.
3. 領域の誤差が有意でない,つまり基準(4)が真である場合
MinRecursionとMaxRecursion
"LocalAdaptive"のオプションMinRecursionとMaxRecursionは,"GlobalAdaptive"に対するものと同じ意味および機能を持つ.「MinRecursionとMaxRecursion」を参照のこと.
"InitialEstimateRelaxation"
最初の再帰が終了すると,よりよい積分推定値 ![]() が利用できるようになる.このよりよい推定値は,積分則で初期ステップに対する積分値(
が利用できるようになる.このよりよい推定値は,積分則で初期ステップに対する積分値(![]() )および誤差推定値(
)および誤差推定値(![]() )を与えるために使われた2つの積分推定値
)を与えるために使われた2つの積分推定値 ![]() ,
,![]() と比較される.もし
と比較される.もし
で増加させることができる—つまり,条件(6)は緩められる.それは ![]() が規則の積分推定値は規則の誤差推定値が予想するものよりも正確であるということを意味しているからである.
が規則の積分推定値は規則の誤差推定値が予想するものよりも正確であるということを意味しているからである.
"Partitioning"
"LocalAdaptive"には,(7)を満足しない領域を分割する方法を指定するためのオプション"Partitioning"がある.一次元積分の場合,"Partitioning"がAutomaticに設定されていると,"LocalAdaptive"は再スケールされた積分則のサンプル点の間の領域を分割する.これで,積分則が閉形式ならば,すべての積分値が再利用できる."Partitioning"に積分変数の数に等しい長さ ![]() の整数のリスト
の整数のリスト![]() が与えられると,積分領域の各次元
が与えられると,積分領域の各次元 ![]() は
は ![]() 個の等しい部分に分割される."Partitioning"に整数
個の等しい部分に分割される."Partitioning"に整数 ![]() が与えられると,すべての次元が
が与えられると,すべての次元が ![]() 個の等しい部分に分割される.
個の等しい部分に分割される.
被積分関数値の再利用
"LocalAdaptive"の一次元積分に対するデフォルトの分割設定では,(8)を満足しない積分値および誤差推定値を持つ部分区間の終端点における被積分関数値が再利用される.
局所的適応型ストラテジーの例題実装
"GlobalAdaptive"と"LocalAdaptive"
一般に大域的適応型ストラテジーは,局所的適応型ストラテジーよりもパフォーマンスが優れている.しかし,局所的適応型ストラテジーの方がロバストでありパフォーマンスが優れている場合もある.
"GlobalAdaptive"と"LocalAdaptive"には2つの大きな違いがある.
1. "GlobalAdaptive"は全領域の誤差の総和が目標精度を満足すると終了する.一方"LocalAdaptive"は各領域の誤差が積分の推定に比べて十分小さいときに終了する.
2. 積分推定値を向上させるために,"GlobalAdaptive"は領域を最大誤差で二分するが,"LocalAdaptive"は十分小さくない誤差で全領域を分割する.
多次元積分の場合,"LocalAdaptive"は軸に沿って分割を実行するため,領域の数は組合せ論的に増加する可能性がある.したがって,"GlobalAdaptive"の方がずっと速い.
大域的適応型ストラテジーの方が一次元の滑らかな被積分関数に対してなぜどのように速いのかは[MalcSimp75]で証明(説明)されている.
"LocalAdaptive"の方が"GlobalAdaptive"より速くパフォーマンスも優れている場合,それは"LocalAdaptive"の目標精度中止基準および分割ストラテジーの方が被積分関数の特性に適しているからである.別の要因は,"LocalAdaptive"がすでにサンプリングされたすべての点の積分値を再利用できるということにある."GlobalAdaptive"はほんのわずかな積分値しか再利用できない(規則の適用につき最大で3つ,一次元積分のデフォルトであるガウス・クロンロッド則では0).
次では,"GlobalAdaptive"と"LocalAdaptive"のパフォーマンスの差を示す.
通常"LocalAdaptive"に勝る"GlobalAdaptive"
所要時間の比と被積分関数評価の数を含む下の表は,ほとんどの場合"GlobalAdaptive"の方が"LocalAdaptive"よりもよいことを示している.考慮されるすべての積分は![]() 上の一次元積分である.なぜならば,(i) "LocalAdaptive"は各軸に沿って領域を分割するため,多次元積分ではパフォーマンスの差は深くなることが予想されるからであり,(ii) 異なる範囲上の一次元積分は
上の一次元積分である.なぜならば,(i) "LocalAdaptive"は各軸に沿って領域を分割するため,多次元積分ではパフォーマンスの差は深くなることが予想されるからであり,(ii) 異なる範囲上の一次元積分は![]() 上になるよう再スケールすることができるからである.
上になるよう再スケールすることができるからである.
特異点の処理
NIntegrateの適応型ストラテジーにより,積分領域境界線およびユーザ指定の特異点または多様体における変数変換を介した収束がスピードアップされている.適応型ストラテジーは,特異点における被積分関数の評価結果も無視する.
特異点の指定は「ユーザ指定の特異点」で説明する.
変数変換で多次元の特異点を扱う場合は注意が必要である.「IMT多次元特異点処理」を参照するとよい.多次元積分に対する座標変換により特異点を簡約あるいは削除することができる.「多次元特異点処理のためのDuffyの座標」を参照のこと.
NIntegrateがどのように特異点を無視するかの詳細は「特異点の無視」に記述してある.
コーシー主値積分の計算は「コーシー主値積分」に記述してある.
ユーザ指定の特異点
点の特異性
特異点が発生した場所が分かっていると,それは積分範囲あるいはオプションExclusionsで指定することができる.
曲線,曲面,超曲面の特異点
一般に曲線,曲面,超曲面上の特異点は,方程式のオプションExclusionsで指定することができる.このような特異点は通常変数範囲を使っては指定できない.

曲線,曲面,超曲面の特異点処理の例題実装
特異点が生じている曲線,曲面,超曲面が暗示的形式(1つの方程式として記述できる)で分かっている場合,関数Booleを使って特異曲線,曲面,超曲面を境界として持つ積分領域を形成することができる.
"SingularityHandler"と"SingularityDepth"
適応型ストラテジーは領域の二分により積分推定値を向上させる.適応型ストラテジーの部分領域がオプション"SingularityDepth"により指定された二分法の数により得られるならば,その部分領域には特異点があると決まる.その部分領域上の積分は"SingularityHandler"により指定された特異点ハンドラで行われる.
オプション名
|
デフォルト値
| |
| "SingularityDepth" | Automatic | 特異点ハンドラを適用する前の再帰的二分法の数 |
| "SingularityHandler" | Automatic | 特異点ハンドラ |
"GlobalAdaptive"と"LocalAdaptive"の特異点ハンドラオプション
指定された積分領域の境界上に積分可能な特異点がある場合,収束が起る前はMaxRecursionまで簡単に二分法が繰り返される.この状況に対処するために,NIntegrateの適応型ストラテジーは変数変換(IMT,"DoubleExponential",SidiSin)を使い,積分収束あるいは特異点の次数を緩める領域変換(Duffyの座標)を高速化する.変数変換特異点ハンドラの理論的背景はオイラー・マクローリンの公式[DavRab84]に記載されている.
IMT変数変換の使用
IMT変数変換は,文献ではIMT公式[DavRab84][IriMorTak70]と呼ばれる,伊理・森口・高沢により提唱された求積法の変数変換である.IMT公式は,新しい被積分関数のすべての導関数が積分区間の終点で消失するように,独立変数を変換すると言う考えに基づいている.その後,台形則が新しい被積分関数に適用され,適切な条件下で確度の高い結果が達成される[IriMorTak70][Mori74].
NIntegrateの適応型ストラテジーではIMT変換だけを使用する.領域に特異点があると決まると,その被積分関数にIMT変換が適用される.積分は台形則ではなく,変換前に使われていたのと同じ規則で続行する("DoubleExponential"を使った特異点処理では台形積分則に切換えられる).
また,NIntegrateの適応型ストラテジーでは,変換された被積分関数がどちらか一方の端で消失する,もとのIMT変換の変形が使われる.
パラメータ a と p は調整パラメータと呼ばれる[MurIri82].
上のグラフから,変換されたサンプル点は0付近の方がずっと密であることが分かる.これは,被積分関数が0において特異であれば,より効率よく抽出されることを意味する.それは積分則サンプル点の大部分は,大きい被積分関数値を積分則の積分推定値に起因させるためである.
IMT変数変換が適用される領域の部分領域に適用される特異点ハンドラは他にはない.
IMT変換の例
しかしサンプル点のいくつかが特異な終点に近付きすぎているので,IMT変換により特異点と一致しているサンプル点には特に注意が必要である.NIntegrateは特異点における評価を無視する.詳細は「特異点の無視」を参照のこと.
二重指数関数型公式の使用
適応型ストラテジーでIMT変数変換が使用される場合,IMT変換された領域の積分則は変更されない.これとは対照的に,特異点を持つと想定されている領域に対して変数変換と異なる積分則の両方を使うことができる(これはIMT公式の姿勢である[DavRab84]).まったくそのようなことが二重指数関数型公式(二重指数関数型公式で台形則)が使用されたときに起る.
NIntegrateは一次元積分に対してのみ,特異点処理のために二重指数関数型公式を使うことができる.
一次元積分でのIMTと"DoubleExponential"と非特異点処理
どちらの特異点ハンドラ(IMTと"DoubleExponential")も多すぎる二分回数("SingularityDepth"で指定されたように)で得られた領域に適用される.
その2つの主な違いは,IMTは適用される領域の積分推定値を計算するために使われる積分則を変更しないと言うことである.IMTは変数変換に過ぎない.一方,"DoubleExponential"は変数変換および異なる積分則(台形則)の両方を使い,適用される領域上の積分推定値を計算する.換言すると,特異点ハンドラの"DoubleExponential"は二重指数関数型ストラテジーで説明してあるように,二重指数関数型公式に積分を委託する.
その結果,IMT特異点ハンドラが適用される領域は,まだ適応型積分ストラテジーによる二分法の対象となる.ゆえに,目標精度に到達するまで,最後の二分法の前に実行された被積分関数の評価は捨てられる.一方,"DoubleExponential"特異点ハンドラが適用される領域は二分されない."DoubleExponential"で使用される台形則は,各ステップでサンプル点が増加する領域上の積分推定値を計算し,前のステップからのサンプル点の被積分関数評価を完全に再利用する.
したがって,被積分関数が,終点が特異点である領域上で「非常に」解析的である(被積分関数および積分変数に関して導関数に急速あるいは突然の変化がない)場合,"DoubleExponential"特異点ハンドラはIMT特異点ハンドラよりもずっと速くなる.被積分関数が"DoubleExponential"特異点ハンドラに与えられた領域において解析的でない,あるいは被積分関数の二重変換の収束が遅すぎるという場合は,IMT特異点ハンドラに切り換えた方がよい.この切換えはオプション"SingularityHandler"をAutomaticに設定して行う.
以下の表では,異なる二分の深さにおいて適用されたIMT,"DoubleExponential",Automaticの特異点ハンドラを比較する.
IMT多次元特異点処理
IMT特異点ハンドラを多次元積分に使うと,特異点が軸のいずれかに沿っている場合だけ積分過程がスピードアップする.特異点が積分領域の角にある場合は,IMTを使うことは逆効果である.先に定義した関数NIntegrateProfileを次の例で使う.
多次元特異点処理のためのDuffyの座標
Duffyの座標は,いずれかの角に特異点を持つ正方形,立方体,超立方体上の被積分関数を線上の特異点を持つ被積分関数に変換する方法である.後者の方が積分しやすい場合がある.
NIntegrateのストラテジーである"GlobalAdaptive"と"LocalAdaptive"は積分領域の角だけでDuffyの座標を適用する.
ある点で多次元積分の特異点が発生すると,変数の結合により一次元積分で使用される特異点変数変換が逆効果になる.[Duffy82]でDuffyにより提唱された幾何学的性質を持つ変数変換は,積分領域の角にある特異点を,平面上の「柔らかい」特異点で置き換える変数の変更を行う.
![]() が積分の次元で
が積分の次元で ![]() ならば,Duffyの座標は次のタイプの特異点に適したものである(再び[Duffy82]を参照).
ならば,Duffyの座標は次のタイプの特異点に適したものである(再び[Duffy82]を参照).
を考えてみる.積分領域![]() が規則
が規則 ![]() で
で![]() に変更されると,そのヤコビアンは
に変更されると,そのヤコビアンは ![]() で積分は以下のようになる.
で積分は以下のようになる.
に等しい.この総和の第1積分は(9)のように変換される.しかし,2つ目は ![]() による
による![]() の
の![]() への変更にヤコビアン
への変更にヤコビアン![]() を持つ.これは項の打消しをもたらさない.積分の順序を変えてみる.
を持つ.これは項の打消しをもたらさない.積分の順序を変えてみる.
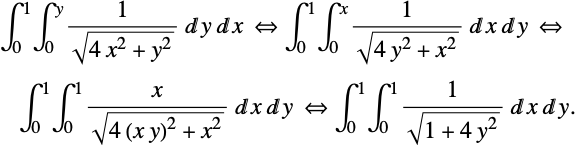
(方程式(3)の第2積分では,変数は置換される.これは数学的等価性を証明するために必要ではないが,積分を計算するときに速い.)
積分(11)は特異点のない積分として書き換えることができる.
積分変数が(12)で置換されないならば,積分(13)は以下のように書き換えられる.
これは,その被積分関数が単純にどちらの軸にも沿っていないので,より複雑な積分である.その結果前のものよりも計算が難しい.
NIntegrateは上の例で任意次元の手法の一般化を使っている([Duffy82]では三次元が記述されているだけである).一般化記述との例題実装を下に挙げる.
Duffyの座標ストラテジー
Duffyの座標が適用できる場合,実際の積分が始まる前にDuffyの座標の変化が起ると,数値積分の結果が速く得られる.しかし事前に変換を行うには,積分領域のどの角で特異点が発生するかが分かっていなければならない.NIntegrateの"DuffyCoordinates"ストラテジーはそのような事前積分変換を簡単にする.
オプション名
|
デフォルト値
| |
| Method | {"GlobalAdaptive","SingularityDepth"->∞} | Duffyの座標変換を適用した後に積分を行うストラテジー |
| "Corners" | All | Duffyの座標変換を適用する角を指定するベクトルあるいはベクトルのリスト.ベクトルの要素は0か1である.各ベクトルの長さは積分の次元に等しい |
"DuffyCoordinates"がまず行うのは,積分を単位超立方体(あるいは正方形か立方体)上にある積分に再スケールすることである.1つの角だけが指定されている場合,"DuffyCoordinates"は上で記述してあるようにDuffyの座標変換を適用する.2つ以上の角が指定してある場合は,前のステップの単位超立方体が,辺が1/2である隣接しない立方体に分割される.これらの隣接しない立方体上の積分を考えて見る.Duffyの座標変換は特異となるよう指定された頂点を持つ立方体に適用される.残りは単位立方体上の積分へと変換される.この時点ですべての積分は単位立方体である積分領域を持つので,それらは加算されその和は"DuffyCoordinates"に与えられるのと同じオプションであるMethodオプションを持つNIntegrateに与えられる.
"DuffyCoordinates"で使われる実際の積分は,NIntegrateと同じ引数を取るNIntegrate`DuffyCoordinatesIntegrandで得ることができる.
"DuffyCoordinates"は,「多次元特異点処理のためのDuffyの座標」に記述してある被積分関数のタイプで顕著なスピードの向上を引き起こすことがある.
Duffyの座標の一般化と例題実装
Duffyの座標の理論については,「多次元特異点処理のためのDuffyの座標」を参照のこと.
定理 1:![]() 次元の立方体は幾何学的に等価な
次元の立方体は幾何学的に等価な ![]() 個の互いに素な
個の互いに素な ![]() 次元角錐(規定が
次元角錐(規定が![]() 次元立方体で頂点が一致)に分割される.
次元立方体で頂点が一致)に分割される.
証明:立方体の辺の長さが![]() で,立方体が原点に頂点を持ち,他のすべての頂点の座標が
で,立方体が原点に頂点を持ち,他のすべての頂点の座標が![]() か
か![]() であるとする.
であるとする.![]() 次元の立方体の壁
次元の立方体の壁 ![]() (ここで
(ここで ![]() )を考える.その数は厳密に
)を考える.その数は厳密に ![]() であり,原点はそれに入っていない.
であり,原点はそれに入っていない.![]() 個の壁のそれぞれは原点を持つ角錐を形成する.これで定理は証明される.
個の壁のそれぞれは原点を持つ角錐を形成する.これで定理は証明される.
![]() 本の軸が
本の軸が ![]() と表される場合,壁
と表される場合,壁 ![]() で形成された角錐が
で形成された角錐が![]() と記述できるとする.
と記述できるとする.![]() を循環的に
を循環的に ![]() 回左に回転させた(つまりRotateLeftを
回左に回転させた(つまりRotateLeftを![]() に
に ![]() 回適用した)後に導出される置換を
回適用した)後に導出される置換を ![]() で表す.すると次の定理が成り立つ.
で表す.すると次の定理が成り立つ.
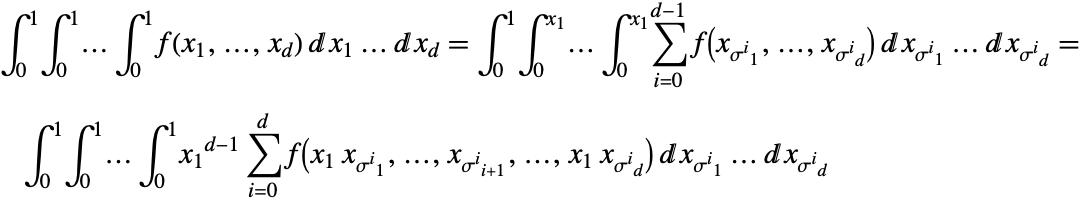
証明:最初の等式は定理1に従う.2つ目の等式は角錐を立方体に変換する変数の変化だけである.
特異点の無視
特異点処理の別の方法に,無視するということがある.NIntegrateは特異点と一致するサンプル点を無視する.
以下で分かるように,NIntegrateはデフォルトオプションでは1でサンプル点を持つ.
しかしNIntegrate[Log[(1-x)2],{x,0,2}]では,評価モニタは1であるサンプル点を選んでいない.
換言すると,1における特異点は無視される.特異点を無視することは特異なサンプル点でゼロである被積分関数を持つことに等しい.
特異点が変数範囲で指定されるならば,積分は簡単に積分される.次は,特異および非特異な範囲指定のNIntegrateに対するサンプル点の数と所要時間である.
特異点を無視することのもっと面白い例は,被積分関数の分母にベッセル関数を使ったものである.
結果はBesselJ[2,x]の零点を持つ特異点範囲指定のNIntegrateを使って検証することができる(BesselJZeroを参照).
言うまでもなく,最後の積分にはBesselJの零点の計算が必要であった.前者は全く被積分関数を解析しないでただ積分するだけである.
特異点を無視することは振動する被積分関数では有効でないかもしれない.
しかしながら,被積分関数がその特異点の近傍において単調ならば,つまり単調な積分可能関数によりマジョライズされるならば,特異点を無視することにより収束が達成できることを示すことができる.
特異点を無視することの理論的正当性と実践的な推薦は[DavRab65IS]および[DavRab84]を参照のこと.
自動特異点処理
一次元積分
オプション"SingularityHandler"が一次元積分に対してAutomaticに設定されている場合,分割の"SingularityDepth"の数により得られる領域には"DoubleExponential"が使われる.前述の通り,"DoubleExponential"特異点ハンドラがこの領域に対して動作する限り,領域はそれ以上分割されない."DoubleExponential"により計算される誤差推定値が二重指数関数型公式の理論により予言されるように進化しないならば,この領域に対する特異点処理はIMTに切り換えられる.
「収束率」で述べているように,次の誤差の依存性は二重指数関数的サンプル点の数について予想される.
ここで ![]() は正の定数である.それぞれ
は正の定数である.それぞれ ![]() 個と
個と ![]() 個(ここで
個(ここで ![]() )の数のサンプル点で作成された,2つの連続した二重指数関数型公式の計算の相対誤差
)の数のサンプル点で作成された,2つの連続した二重指数関数型公式の計算の相対誤差 ![]() と
と ![]() を考える.
を考える.![]() ,
,![]() ,
,![]() と仮定すると,以下が想定される.
と仮定すると,以下が想定される.
"DoubleExponential"からIMTへの切換えは,以下の場合に起る.
(i) 領域の誤差推定が領域の積分推定値の絶対値よりも大きい(よって相対誤差は![]() より小さくない)
より小さくない)
(iii) 二重指数関数型変換で計算された被積分関数の値がゆっくりとしか崩壊しない.
多次元積分
多次元積分でオプション"SingularityHandler"がAutomaticに設定されていると,"DuffyCoordinates"とIMTの両方が使われる.
"DuffyCoordinates"を適用するためには,領域は次の条件に合っていなければならない.
領域は各軸に沿った"SingularityDepth"数の二分(分割)で得られたものである
領域は初期積分領域の中のひとつの角である(指定された積分領域は,区分処理あるいはユーザ指定の特異点により積分領域に分割することができる)
IMTを適用するためには,領域は次の条件に合っていなければならない.
領域は,主に1つの軸に沿った"SingularityDepth"数の二分(分割)で得られたものである
領域は角の領域ではなく,初期積分領域のうちの1つの辺上にあるものである
換言すると,IMTは"SingularityDepth"数の分割で得られたが"DuffyCoordinates"自動適用の条件は満足しない領域に適用される.
IMTは,特異点がいずれかの軸に沿っている場合に効率的である.点の特異性に対してIMTを使うのは逆効果になり得る.
コーシーの主値積分
積分のコーシーの主値を評価するために,NIntegrateではストラテジーPrincipalValueが使われる.
NIntegrateのPrincipalValueでは,難しさのない領域を直接操作するためにMethodオプションで指定されたストラテジーが使われる.また,正・負の値の打消しを利用するためには,指定された特異点付近で値を対称に対にすることにより指定されたストラテジーが使われる.
オプション名
|
デフォルト値
| |
| Method | Automatic | 部分領域上の推定値を計算するために使われるメソッドの指定 |
| SingularPointIntegrationRadius | Automatic | 数ϵ1 あるいは,範囲指定の中の特異点 |
として評価される.ここでそれぞれの積分はMethod->methodspec としたNIntegrateを使って評価される.もしϵ が明示的に指定されていないならば,値は b-a と c-b の差分に基づいて選ばれる.オプションSingularPointIntegrationRadiusは特異点の数に等しい数のリストを取ることができる.公式の導出については[DavRab84]を参照のこと.
特異点は厳密に見付けなければならない.アルゴリズムは特異点の両側の点を対にするので,特異点の位置が少しでも異なると,極付近の相殺がうまくいかず,NIntegrateが収束しても結果は誤ったものとなり得る.
サンプル点の可視化
下の例では,サンプル点の可視化の方法を2つ示す.最初は使用されるサンプル点を示す.被積分関数は主値積分を実行するために変更しなければならないので,もとの被積分関数が評価される点を見た方がよいかもしれない.これは2つ目の例で示す.
二重指数関数型ストラテジー
二重指数関数型公式は変数変換の後に台形則を適用することからなる.二重指数関数型公式は1974年に森・高橋により提唱されたもので,いわゆるIMT公式およびTANH規則からアイディアを得たものである.この変換には「二重指数関数型」という名前が付いているが,これは被積分関数の変数が積分領域の最後に達すると,その導関数が二重関数的に減少するためである.
オプション名
|
デフォルト値
| |
| "ExtraPrecision" | 50 | 内部的に使用される最大追加精度 |
| "SymbolicProcessing" | Automatic | 記号的前処理を実行する秒数 |
二重指数関数型ストラテジーは,一次元積分にも多次元積分にも使える.多次元積分に適用されたときは,台形則のデカルト積が使われる.
に変換される.ここで![]() は有限,半無限(
は有限,半無限(![]() ),無限(
),無限(![]() )のどれでもよい.被積分関数
)のどれでもよい.被積分関数 ![]() は
は![]() において解析的でなければならず,1つあるいは両方の終点で特異点を持つことがある.
において解析的でなければならず,1つあるいは両方の終点で特異点を持つことがある.
変換された被積分関数は二重関数的に減少する.つまり![]() に近付くにつれ,
に近付くにつれ,![]()
![]() となるのである.
となるのである.
関数 ![]() は
は![]() において解析的である.解析的被積分関数の(14)のような積分では,台形則が最適な規則であることが知られている[Mori74].
において解析的である.解析的被積分関数の(14)のような積分では,台形則が最適な規則であることが知られている[Mori74].
(16)の項は,十分大きい![]() のときに二重指数関数的に衰退する.したがって,(17)の和は,総和に関与しないほど小さい項で切り取られる(局所的適応型ストラテジーでは(18)に類似した基準が使われる.次の「二重指数関数型積分法の例題実装」も参照のこと).
のときに二重指数関数的に衰退する.したがって,(17)の和は,総和に関与しないほど小さい項で切り取られる(局所的適応型ストラテジーでは(18)に類似した基準が使われる.次の「二重指数関数型積分法の例題実装」も参照のこと).
ストラテジー"DoubleExponential"では二重指数関数型公式が使われる.
"DoubleExponential"ストラテジーは解析的な被積分関数に最も効果的である.「二重指数関数型積分法とガウス積分法との比較」を参照のこと.
"DoubleExponential"では多重積分に二重指数関数型公式の直積が使われる.
他の直積型公式でそうであるように,"DoubleExponential"が3より大きい次元に使われると,組合せ的爆発により非常に遅くなる可能性がある.
二重指数関数型公式は適応型ストラテジーの特異点処理に使うことができる.詳細は「特異点処理」に記述してある.
MinRecursionとMaxRecursion
オプションMinRecursionは「MinRecursionとMaxRecursion」で記述してある"GlobalAdaptive"および"LocalAdaptive"に対して持つのと同じ意味と機能を持つ."DoubleExponential"のMaxRecursionは台形求積推定値が向上する回数を制限する.詳細は「二重指数関数型積分法の例題実装」を参照のこと.
二重指数関数型積分法とガウス積分法との比較
"DoubleExponential"ストラテジーは解析的な被積分関数に最も効果的である.例えば,以下の積分はガウス積分法(大域的適応型アルゴリズムを使う)よりも"DoubleExponential"で実行した方が3倍速い.
"DoubleExponential"は評価点の数に関して二重関数的に収束するので,目標精度を上げても"DoubleExponential"であまり効果が得られない.これを2つの積分 ![]() と
と ![]() で説明する.それぞれの表には誤差と評価回数が示してある.
で説明する.それぞれの表には誤差と評価回数が示してある.
一方,非解析的な被積分関数では"DoubleExponential"は非常に遅く,ガウス積分法を使う大域的適応型アルゴリズムは簡単に特異点を解決することができる.
さらに,"DoubleExponential"はほぼ非連続な導関数を持つ被積分関数,つまりあまり解析的でない被積分関数により遅くなる場合がある.
収束率
このセクションでは,使用される評価点の数 ![]() について二重指数関数型公式の漸近誤差が
について二重指数関数型公式の漸近誤差が
二重指数関数型積分法の例題実装
次に挙げるのは,有限領域変数変換の二重指数関数型積分法の例題実装である(上の変換(21)).
"Trapezoidal"ストラテジー
"Trapezoidal"ストラテジーは,積分区間が厳密に1周期である場合に,解析的な周期的被積分関数に最適な収束を与える.
オプション名
|
デフォルト値
| |
| "ExtraPrecision" | 50 | 内部的に使用される最大の追加精度 |
| "SymbolicProcessing" | Automatic | 記号的前処理を実行する秒数 |
"Trapezoidal"は"DoubleExponential"と同じオプションを取る.積分範囲が無限あるいは半無限の場合,"Trapezoidal"は"DoubleExponential"になる.
(台形則での)周期関数積分の理論的背景,例題,説明は[Weideman2002]を参照のこと.
例題の実装
振動ストラテジー
NIntegrateには振動積分のためのメソッドがいくつか含まれている.一次元および多次元の振動積分という大きいクラスには,積分則"LevinRule"が適用されれる.これは"GlobalAdaptive"等の適応型規則ベースのストラテジーとともに使われる.
NIntegrateにはある種の一次元振動積分に特化された積分ストラテジーもいくつか含まれている.通常,これらのアルゴリズムは,有限区間の積分か無限区間の積分のみに使われる.有限区間上の振動積分の場合,NIntegrateは被積分関数のチェビシェフ(Chebyshev)展開と大域的適応型積分ストラテジーを使う.無料区感上の振動積分の場合は,NIntegrateは修正二重指数アルゴリズム,あるいは被積分関数の零点間の区間上にある積分列での列総和加速を使う.
NIntegrateは自動的に振動(一次元)被積分関数を検出し,被積分関数の範囲に従ってどのストラテジーや規則を使えばよいか,また特定の振動形式を選ぶ.
ここで説明してある特化されたストラテジーにより扱われる積分は,以下の形式である.
これらの振動カーネル形式で,![]() ,
,![]() ,
,![]() は実定数,
は実定数,![]() は正の整数である.
は正の整数である.
その積分則で扱われる振動被積分関数のより一般的な形式の説明は,"LevinRule"を参照されたい.
有限領域振動積分
変形クレンショウ・カーチス則([PiesBrand75][PiesBrand84])は以下の形式
の有限領域一次元積分公式である.ここで ![]() ,
,![]() ,
,![]() ,
,![]() ,
,![]() は有限実数である.
は有限実数である.
変形クレンショウ・カーチス則はチェビシェフ多項式展開により1つの多項式で ![]() を近似する.これにより,計算が簡約化される.正弦関数および余弦関数を持つチェビシェフ多項式は直交であるためである.変形クレンショウ・カーチス則はストラテジー"GlobalAdaptive"で使われる.滑らかな
を近似する.これにより,計算が簡約化される.正弦関数および余弦関数を持つチェビシェフ多項式は直交であるためである.変形クレンショウ・カーチス則はストラテジー"GlobalAdaptive"で使われる.滑らかな ![]() では,変形クレンショウ・カーチス則は通常振動積分に対する他のアプローチ(Filonの求積法や被積分関数の零点間のマルチパネル積分)よりも優れている[KrUeb98].
では,変形クレンショウ・カーチス則は通常振動積分に対する他のアプローチ(Filonの求積法や被積分関数の零点間のマルチパネル積分)よりも優れている[KrUeb98].
変形クレンショウ・カーチス則は形式(1)の高度に振動する積分に非常に適している.例えば,変形クレンショウ・カーチス則では![]() と
と![]() の両方に対して使われる被積分関数の評価が100に満たない.
の両方に対して使われる被積分関数の評価が100に満たない.
一方,記号的前処理をしないと,デフォルトのNIntegrateメソッドであるガウス・クロンロッド則の"GlobalAdaptive"ストラテジーは,![]() に対して何千もの評価を使い,
に対して何千もの評価を使い,![]() は積分することができない.
は積分することができない.
外挿振動ストラテジー
NIntegrateの"ExtrapolatingOscillatory"ストラテジーは無限の一次元領域の振動積分に対するものである.このストラテジーは被積分関数の2つの連続する零点間の領域を持つ積分のそれぞれから構成される数列の総和に対して数列の収束加速法を使用する.
オプション名
|
デフォルト値
| |
| Method | GlobalAdaptive | 零点間の積分をするために使われる積分ストラテジーであり,ExtrapolatingOscillatoryが失敗したときに使われる |
| "SymbolicProcessing" | Automatic | 記号的処理を実行する秒数 |
を考える.関数 ![]() は振動カーネルであり,関数
は振動カーネルであり,関数 ![]() は滑らかである.
は滑らかである.![]() を積分の下限(有限)から列挙された
を積分の下限(有限)から列挙された ![]() の零点であるとする.つまり,不等式
の零点であるとする.つまり,不等式 ![]() が成り立つということである.もし積分(23)が収束するならば,数列
が成り立つということである.もし積分(23)が収束するならば,数列
の部分和である.数列(25)の極限のよい推定値は,収束加速法を介してその数列の比較的少ない要素を使って計算することができることが多い.
"ExtrapolatingOscillatory"ストラテジーでは,(26)の積分に対してウィンの外挿法のNSumが使われる.(27)のそれぞれの積分は,振動法なしのNIntegrateで計算される.
"ExtrapolatingOscillatory"ストラテジーは![]() ,
,![]() ,
,![]() ,
,![]() ,
,![]() ,
,![]() ,
,![]() ,
,![]() (ここで
(ここで ![]() ,
,![]() ,
,![]() ,
,![]() は実数定数)のいずれかの形式である(28)の振動カーネル
は実数定数)のいずれかの形式である(28)の振動カーネル![]() にそのアルゴリズムを適用する.
にそのアルゴリズムを適用する.
例題の実装
以下の例題の実装は,"ExtrapolatingOscillatory"ストラテジーがどのように動作するかを示す.
二重指数関数型振動積分
ストラテジー"DoubleExponentialOscillatory"は,![]() ,
,![]() ,
,![]() (
(![]() は積分変数で
は積分変数で ![]() ,
,![]() ,
,![]() は定数)のいずれかの形式の被積分関数を持つ一次元無限領域上でゆっくりと減衰する振動積分のためのものである.
は定数)のいずれかの形式の被積分関数を持つ一次元無限領域上でゆっくりと減衰する振動積分のためのものである.
オプション名
|
デフォルト値
| |
| Method | None | "DoubleExponentialOscillatory"が失敗したときに使用される積分ストラテジー |
| "TuningParameters" | Automatic | 誤差推定の調整パラメータ |
| "SymbolicProcessing" | Automatic | 記号的処理を実行する秒数 |
"DoubleExponentialOscillatory"のオプション
"DoubleExponentialOscillatory"はストラテジー"DoubleExponential"に基づくものであるが,"DoubleExponentialOscillatory"は積分区間の終点に二重指数関数的に達する変換を使用する代りに,![]() および
および![]() の零点に二重指数関数的に達する変換を使用する.このアルゴリズムの理論的基礎および特性は[OouraMori91],[OouraMori99],[MoriOoura93]で説明されている."DoubleExponentialOscillatory"の実装には,[OouraMori99]の公式および積分器設計が使われる.
の零点に二重指数関数的に達する変換を使用する.このアルゴリズムの理論的基礎および特性は[OouraMori91],[OouraMori99],[MoriOoura93]で説明されている."DoubleExponentialOscillatory"の実装には,[OouraMori99]の公式および積分器設計が使われる.
"DoubleExponentialOscillatory"のアルゴリズムは,正弦積分
を満足するよう選ばれる([OouraMori99]より抜粋).
を得る.ω が正弦項でなくなっていることに注意されたい.等しいメッシュサイズ ![]() の台形公式を(31)に適用すると
の台形公式を(31)に適用すると
を満足するように選ばれる.被積分関数は(32)から分かるように,大きい負の ![]() において二重指数関数的に減衰する.「二重指数関数型ストラテジー」セクションの(33)である二重指数関数型変換も,大きい正の
において二重指数関数的に減衰する.「二重指数関数型ストラテジー」セクションの(33)である二重指数関数型変換も,大きい正の ![]() において被積分関数を二重指数関数的に減衰させるが,変換(34)は大きい正の
において被積分関数を二重指数関数的に減衰させるが,変換(34)は大きい正の ![]() で被積分関数を減衰させない.その代りにサンプル点が大きい正の
で被積分関数を減衰させない.その代りにサンプル点が大きい正の ![]() において
において![]() の零点に二重指数関数的に近付かせる.さらに
の零点に二重指数関数的に近付かせる.さらに
である.[OouraMori99]で説明されているように,![]() はそのいずれの零点付近でも線形なので,
はそのいずれの零点付近でも線形なので,![]() が
が![]() の零点に近付くにつれて被積分関数は二重指数関数的に減少する.これが(35)が二重指数関数型公式と考えられる理由である.
の零点に近付くにつれて被積分関数は二重指数関数的に減少する.これが(35)が二重指数関数型公式と考えられる理由である.
を満足すると仮定されている.[OouraMori99]では,![]() に提案された値は
に提案された値は![]() である.
である.
![]() 公式は進行形にすることができないので,"DoubleExponentialOscillatory"は([OouraMori99]で提唱されているように),異なる
公式は進行形にすることができないので,"DoubleExponentialOscillatory"は([OouraMori99]で提唱されているように),異なる ![]() で
で![]() から
から![]() までの積分推定を行う.所望の相対誤差が
までの積分推定を行う.所望の相対誤差が ![]() ならば,積分ステップは以下のようになる.
ならば,積分ステップは以下のようになる.
となるような ![]() を選び,
を選び,![]() で(36)を計算する.その結果を
で(36)を計算する.その結果を ![]() とする.
とする.
2. 次に ![]() と設定し,
と設定し,![]() で(37)を計算する.その結果を
で(37)を計算する.その結果を ![]() とする.最初の積分ステップ
とする.最初の積分ステップ ![]() の相対誤差は
の相対誤差は ![]() と仮定される.(38)より
と仮定される.(38)より ![]() となるので,
となるので,
(ここで ![]() は耐性係数であり,デフォルトは
は耐性係数であり,デフォルトは![]() )を満足するならば,"DoubleExponentialOscillatory"は結果
)を満足するならば,"DoubleExponentialOscillatory"は結果 ![]() で終了する.
で終了する.
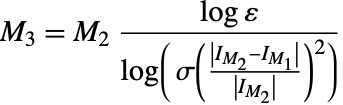
が成り立てば,"DoubleExponentialOscillatory"は結果 ![]() で終了する.
で終了する.
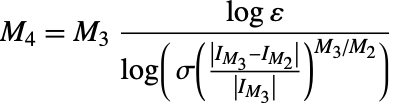
な成り立たないならば,"DoubleExponentialOscillatory"はメッセージNIntegrate::deonconを出力する."DoubleExponentialOscillatory"メソッドオプションの値がNoneならば,![]() が返される.そうでない場合は,"DoubleExponentialOscillatory"は"DoubleExponentialOscillatory"メソッドオプションで呼ばれたNIntegrateの結果を返す.
が返される.そうでない場合は,"DoubleExponentialOscillatory"は"DoubleExponentialOscillatory"メソッドオプションで呼ばれたNIntegrateの結果を返す.
一般化積分
発散フーリエ型積分に対する"DoubleExponentialOscillatory"の属性についての詳細は[MoriOoura93]に記載されている.
代数的でない被乗数
単純モンテカルロストラテジーと準モンテカルロストラテジー
単純モンテカルロ法は,積分領域に一様に分布した乱数点上で被積分関数値を平均することにより,指定された積分を推定する.点の数は,推定された標準偏差が指定された目標精度あるいは目標確度を満足するほど小さくなるまで増加される.モンテカルロ法で一様分布した乱数点ではなく,均等分布で確定的に生成された点の列が使われる場合,それは準モンテカルロ法と呼ばれる.
オプション名
|
デフォルト値
| |
| Method | "MonteCarloRule" | モンテカルロ法の指定 |
| MaxPoints | 50000 | サンプル点の最大数 |
| "RandomSeed" | Automatic | 乱数生成器をリセットする種 |
| "Partitioning" | 1 | 各軸に沿った積分領域の分割 |
| "SymbolicProcessing" | 0 | 記号的前処理を行う秒数 |
モンテカルロ法[KrUeb98]では,![]() 次元積分
次元積分 ![]() は次の期待(平均)値として解釈される.
は次の期待(平均)値として解釈される.
ここで ![]() は,
は,![]() に対する一様分布,つまり確率密度vol(V)-1Boole(x∈V)の分布について,確率変数として解釈された関数
に対する一様分布,つまり確率密度vol(V)-1Boole(x∈V)の分布について,確率変数として解釈された関数 ![]() の平均値(期待値)である.領域
の平均値(期待値)である.領域 ![]() の特性関数はBoole(x∈V)で表され,
の特性関数はBoole(x∈V)で表され,![]() の体積は
の体積は![]() で表される.
で表される.
単純モンテカルロ法の積分値は積分則"MonteCarloRule"で生成される.積分値と誤差推定値の公式は「NIntegrateの積分則」の「MonteCarloRule」に示してある.
を考えてみる.もとの積分領域![]() が互いに素な部分領域の集合
が互いに素な部分領域の集合![]() ,
,![]() に分割されるならば,積分推定値は
に分割されるならば,積分推定値は
となる.それぞれの部分領域で使用されるサンプル点の数は異なる場合があるが,モンテカルロ法では,すべての ![]() は等しい(
は等しい(![]() ).
).
分割![]() は層化と呼ばれ,各
は層化と呼ばれ,各![]() は層と呼ばれる.層化は「単純モンテカルロ推定値の向上」のために使うことができる(「適応型モンテカルロ法」では再帰的層化が使われる).
は層と呼ばれる.層化は「単純モンテカルロ推定値の向上」のために使うことができる(「適応型モンテカルロ法」では再帰的層化が使われる).
AccuracyGoalとPrecisionGoal
AccuracyGoalとPrecisionGoalのデフォルト値は,NIntegrateのモンテカルロ法が使われるときはそれぞれInfinityと2である.
MaxPoints
オプションMaxPointsは,積分のモンテカルロ指定値を計算するために使われる(擬似)乱数のサンプル点の最大数を指定する.
"RandomSeed"
オプション"RandomSeed"の値は,積分点を生成するために使われる乱数生成器に種を蒔くために使われる.この点においては,モンテカルロ法で"RandomSeed"を使うことはSeedRandomおよびRandomRealを使うことに似ている.
"RandomSeed"を使うことにより,モンテカルロ積分の結果は再生することができる.次の2つの結果は同一である.
層化抽出法の単純モンテカルロ積分
層化抽出法のモンテカルロ積分では,領域をいくつかの部分領域に分割し,それぞれの部分領域に別々に単純モンテカルロ推定法を適用する.
期待(平均)値公式である「単純モンテカルロストラテジーと準モンテカルロストラテジー」の最初の方程式(44)から,以下が求められる.
領域 ![]() が2つの半領域
が2つの半領域 ![]() と
と ![]() に二分されるものとする.
に二分されるものとする.![]() は
は ![]() 上の
上の ![]() の期待値,
の期待値,![]() は
は ![]() 上の
上の ![]() の分散とする.定理[PrFlTeuk92]より
の分散とする.定理[PrFlTeuk92]より
が成り立つ.層化抽出法は単純モンテカルロのサンプリングの分散より大きいことの決してない分散を与える.
"MonteCarlo"ストラテジーに対して層を指定する方法が2つある.ひとつは変数範囲指定における「特異」点を指定するというもので,もうひとつはメソッドサブオプション"Partitioning"を使うというものである.
"Partitioning"に,整数変数の数に等しい長さ ![]() の整数のリスト
の整数のリスト![]() を与えると,積分領域の各次元
を与えると,積分領域の各次元 ![]() は
は ![]() 個の等しい部分に分割される.もし"Partitioning"に整数
個の等しい部分に分割される.もし"Partitioning"に整数 ![]() を与えると,すべての次元が
を与えると,すべての次元が ![]() 個の等しい部分に分割される.
個の等しい部分に分割される.
層化抽出法の単純モンテカルロ積分は,積分変数の範囲が中間の特異点で与えられると指定することができる.
層化抽出法は,単純モンテカルロ積分推定の効率を向上させる.層の数が ![]() ならば,層化抽出法のモンテカルロ推定値の標準偏差は,単純モンテカルロ法による積分値の標準偏差の
ならば,層化抽出法のモンテカルロ推定値の標準偏差は,単純モンテカルロ法による積分値の標準偏差の![]() 分の1である(次の例題を参照).
分の1である(次の例題を参照).
層化抽出法によるモンテカルロ積分の収束のスピードアップ
次の例題は,層の数が ![]() ならば,層化抽出法による積分値の標準偏差は,単純モンテカルロ法の積分値の標準偏差の
ならば,層化抽出法による積分値の標準偏差は,単純モンテカルロ法の積分値の標準偏差の ![]() 分の1であることを示している.
分の1であることを示している.
大域的適応型モンテカルロストラテジーと準モンテカルロストラテジー
大域的適応型モンテカルロストラテジーと準モンテカルロストラテジーは,最大分散推定値で部分領域を再帰的に半分に二分し,それぞれの半分について積分推定と分散推定を計算する.
オプション名
|
デフォルト値
| |
| Method | MonteCarloRule | MonteCarloRule指定 |
| "Partitioning" | Automatic | それぞれの軸に沿った積分領域の初期分割 |
| "BisectionDithering" | 0 | 二分割軸に平行の領域側の真ん中からのオフセット |
| "MaxPoints" | Automatic | 使用する(擬似)乱数サンプル点の最大数 |
| "RandomSeed" | Automatic | (擬似)乱数サンプル点を生成するために使われる乱数の種 |
適応型(準)モンテカルロは,それぞれの部分領域で単純(準)モンテカルロ推定値を使用する.
部分領域二分のプロセスと後続する二重積分は大域的分散を減少させると期待され,これは再帰的層化抽出法と呼ばれる.これは,領域が互いに素な部分領域に分割されるならば,その領域上の確率変数の分散はそれぞれの部分領域上の確率変数の分散の和以上であるという定理に動機付けられている(「単純モンテカルロストラテジーと準モンテカルロストラテジー」の「層化抽出法の単純モンテカルロ積分」を参照のこと).
大域的適応型モンテカルロストラテジー"AdaptiveMonteCarlo"は"GlobalAdaptive"に類似している.しかし以下のような重要な違いがある.
1. "AdaptiveMonteCarlo"は特異点平坦化を使わないし,遅い収束およびノイズのある積分の検出器も持たない.
2. "AdaptiveMonteCarlo"は二分次元をランダムに選ぶ.異なる座標の不規則な分離を避けるために,次元は,他の次元が二分に選ばれたときだけ繰り返される.
3. "AdaptiveMonteCarlo"は真ん中から離れた部分領域を二分するよう調整することができる.詳細は"BisectionDithering"を参照のこと.
MinRecursionとMaxRecursion
適応型モンテカルロ法のオプションMinRecursionとMaxRecursionは"GlobalAdaptive"に対するのと同じ意味と機能を持つ.詳細は「MinRecursionとMaxRecursion」を参照のこと.
"Partitioning"
"AdaptiveMonteCarlo"のオプション"Partitioning"は積分の初期の層化を提供する.これは"MonteCarlo"ストラテジーの"Partitioning"と同じ意味と機能を持つ.
"BisectionDithering"
積分に,領域の真ん中に重要な部分を置く特別な対称性がある場合,二分を真ん中から少し離して行った方がよい.オプション"BisectionDithering"->dith の値は,分割次元側の分割分数が![]() ではなく
ではなく![]() におけるものであることを指定する.dith の符号は,ランダムに変化される."BisectionDithering"に与えられるデフォルト値は
におけるものであることを指定する.dith の符号は,ランダムに変化される."BisectionDithering"に与えられるデフォルト値は![]() である.dith に許される値は区間
である.dith に許される値は区間![]() の中の実数である.
の中の実数である.
二分割線の選択
多次元積分の場合,適応型モンテカルロアルゴリズムは2つの方法で積分領域の分割軸を選択する.1つは無作為抽出であり,もうひとつは各半分の積分推定値の分散を最小化することによる方法である.軸の選択は"MonteCarloRule"の責務となっている.
例題:単純モンテカルロとの比較
一般に,"AdaptiveMonteCarlo"ストラテジーは"MonteCarlo"のパフォーマンスに勝る.ここでは例題を使ってそれを示す.
以下のプロファイルから,"AdaptiveMonteCarlo"は単純"MonteCarlo"ストラテジーの約3分の1のサンプル点を使うことが分かる.
"MultiPeriodic"
"MultiPeriodic"ストラテジーはすべての積分を単位立方上の積分に変換し,その被積分関数をそれぞれの積分変数について1周期となるように期分けする.異なる変数には異なる期分け関数を適用するか,何も適用しない."MultiPeriodic"は12以下の次元の積分に有効である.もし"MultiPeriodic"に高次元の積分が与えられると,"MonteCarlo"ストラテジーが使われる.
オプション名
|
デフォルト値
| |
| "Transformation" | SidiSin | 被積分関数に適用される期分け変換 |
| "MinPoints" | 0 | サンプル点の最少数 |
| "MaxPoints" | 105 | サンプル点の最大数 |
| "SymbolicProcessing" | Automatic | 記号的前処理に使われる秒数 |
"MultiPeriodic"はストラテジー"Trapezoidal"の多次元一般化と見ることができる.これは準モンテカルロ法とも見ることができる.
"MultiPeriodic"では格子の積分則が使われる.[SloanJoe94]と[KrUeb98]を参照のこと.
ここで![]() ,
,![]() における積分格子は,加算減算のもとで閉じられ,
における積分格子は,加算減算のもとで閉じられ,![]() を含む
を含む![]() の離散部分集合と理解される.格子積分則[SloanJoe94]は,以下の形式
の離散部分集合と理解される.格子積分則[SloanJoe94]は,以下の形式
の規則であり,ここで![]() はすべて
はすべて![]() に含まれる積分格子の点である.
に含まれる積分格子の点である.
"MultiPeriodic"が呼ばれると,![]() 次元積分のオプション"Transformation"は,対応する変数を変換するために使われる1引数関数のリスト
次元積分のオプション"Transformation"は,対応する変数を変換するために使われる1引数関数のリスト![]() を取る.もし"Transformation"に
を取る.もし"Transformation"に ![]() より小さい長さ
より小さい長さ ![]() のリストが与えられると,最後の関数
のリストが与えられると,最後の関数 ![]() が最後の
が最後の ![]() 積分変数に対して使われる.もし"Transformation"に関数が与えられると,すべての変数を変換するためにその関数が使われる.
積分変数に対して使われる.もし"Transformation"に関数が与えられると,すべての変数を変換するためにその関数が使われる.
![]() が積分の次元であるとする.
が積分の次元であるとする.![]() ならば,"MultiPeriodic"は期分け変換を適用した後で"Trapezoidal"を呼び出す.
ならば,"MultiPeriodic"は期分け変換を適用した後で"Trapezoidal"を呼び出す.![]() より大きい次元では,期分け変換を適用せずに"MonteCarlo"が呼ばれる."MultiPeriodic"は
より大きい次元では,期分け変換を適用せずに"MonteCarlo"が呼ばれる."MultiPeriodic"は![]() に対していわゆる
に対していわゆる![]() のコピールールを使用する.それぞれの
のコピールールを使用する.それぞれの![]() に対して,"MultiPeriodic"は積分推定値のシーケンスを計算するために使われるコピールールの集合がある.これより少ない点の規則が先に使われる.規則の誤差推定値が目標精度を満足した場合,あるいはシーケンスの中の2つの異なる積分推定値が目標精度を満足した場合,積分は終了する.
に対して,"MultiPeriodic"は積分推定値のシーケンスを計算するために使われるコピールールの集合がある.これより少ない点の規則が先に使われる.規則の誤差推定値が目標精度を満足した場合,あるいはシーケンスの中の2つの異なる積分推定値が目標精度を満足した場合,積分は終了する.
"MultidimensionalRule"との比較
一般に"MultiPeriodic"は"MultidimensionalRule"を使った"GlobalAdaptive"よりも遅い.低精度で高次元積分を計算するために,"MultiPeriodic"は結果をより速く出すことがある.
プリプロセッサ
すべてのストラテジーの機能は,積分の記号的前処理から拡張される.プリプロセッサは積分を他のストラテジー(プリプロセッサを含む)に委託するストラテジーとして見ることができる.
"SymbolicPiecewiseSubdivision"
"SymbolicPiecewiseSubdivision"は,区分的被積分関数を持つ積分を,それぞれの互いに素な積分領域において被積分関数が区分的でない積分に分割するプリプロセッサである.
オプション名
|
デフォルト値
| |
| Method | Automatic | 積分が渡される積分ストラテジーあるいはプリプロセッサ |
| "ExpandSpecialPiecewise" | True | どの区分関数を拡張するか |
| TimeConstraint | 5 | 区分的部分分割を試みる最大秒数 |
| "MaxPiecewiseCases" | 100 | 区分的プリプロセッサが返すことのできる部分領域の最大数 |
| "SymbolicProcessing" | Automatic | 記号的前処理を行う秒数 |
"SymbolicPiecewiseSubdivision"のオプション
このチュートリアルの最初で述べたように,NIntegrateはそれぞれ異なる被積分関数を持つ互いに素な領域を持つ積分を同時に実行することができる.したがって,"SymbolicPiecewiseSubdivision"を使った前処理の後,積分はNIntegrateに特異点指定のある領域が与えられたかのように続行される(これは同じ被積分関数を持つ互いに素な領域の積分を指定することと見ることができる).例えば,"GlobalAdaptive"ストラテジーは二分による最大誤差を持つ領域の積分推定値を向上させようとし,どの被積分関数に対応するかにかかわらす,最大誤差領域を選ぶ.
"ExpandSpecialPiecewise"
ある特定の区分関数上だけで区分的に展開した方がよい場合がある.このような場合は,オプション"ExpandSpecialPiecewise"にその区分的展開を実行する関数のリストを与えることができる.
"EvenOddSubdivision"
"EvenOddSubdivision"は,領域が原点を中心に対称であり,被積分関数が偶関数または奇関数となっている場合に,積分領域を減少させるプリプロセッサである.奇関数の積分の収束はデフォルトで検証される.
オプション名
|
デフォルト値
| |
| Method | Automatic | 積分が渡される積分ストラテジーあるいはプリプロセッサ |
| VerifyConvergence | Automatic | 奇関数の積分が検出されたときに,収束を検証する |
| "SymbolicProcessing" | Automatic | 記号的前処理を実行する秒数 |
被積分関数が偶関数であり,積分領域が原点を中心として対称な場合,積分は積分領域の一部だけで積分し,対応する因子で乗算することにより計算することができる.
変換定理
プリプロセッサ"EvenOddSubdivision"は次の定理に基づいている.
換言すると,![]() の範囲は原点を中心として対称であり,変数
の範囲は原点を中心として対称であり,変数 ![]() の境界は
の境界は ![]() についての偶関数である.
についての偶関数である.
に等しい.これは被積分関数が ![]() について偶関数,つまり以下の場合である.
について偶関数,つまり以下の場合である.
b) 積分は,被積分関数が ![]() について奇関数の場合,つまり下の場合に
について奇関数の場合,つまり下の場合に![]() に等しい.
に等しい.
定理を例示するために,積分 ![]() を考えてみる.これは
を考えてみる.これは ![]() に対して対称であり,
に対して対称であり,![]() の被積分関数と境界は
の被積分関数と境界は ![]() に関して偶関数である.
に関して偶関数である.
![]() の境界が
の境界が ![]() に関して偶関数でないならば,
に関して偶関数でないならば,![]() に対する対称性は壊れる.例えば,積分
に対する対称性は壊れる.例えば,積分 ![]() にはNIntegrateが使える対称性はない.
にはNIntegrateが使える対称性はない.
"VerifyConvergence"
"OscillatorySelection"
"OscillatorySelection"は一次元振動積分の効率的な評価のために特化されたアルゴリズムを選ぶプリプロセッサである.
それぞれの積分範囲上で"OscillatorySelection"は,被積分関数がフーリエの有限範囲型,フーリエの無限範囲型("DoubleExponentialOscillatory"を参照),ベッセルの無限範囲型("ExtrapolatingOscillatory"を参照),レビン型("LevinRule"を参照)のいずれか,ある9いはどの特殊な振動型でもないかを検出する.
オプション名
|
デフォルト名
| |
| "BesselInfiniteRangeMethod" | Automatic | 無限範囲のベッセル積分に対する方法 |
| "FourierFiniteRangeMethod" | Automatic | 有限範囲のフーリエ積分に対する方法 |
| "FourierInfiniteRangeMethod" | Automatic | 無限範囲のフーリエ積分に対する方法 |
| "LevinMethod" | Automatic | レビン型の振動積分に対する方法 |
| Method | "GlobalAdaptive" | 非振動積分に対する方法 |
| "TermwiseOscillatory" | False | 総和の中の項を別々に処理するかどうか |
| "SymbolicProcessing" | 5 | 記号処理を行う秒数 |

プリプロセッサ"OscillatorySelection"は"SymbolicPiecewiseSubdivision"プリプロセッサの内的出力と動作するよう設計されている."OscillatorySelection"自体は原点を含む,または拡張・変換が必要な振動カーネルを持つ振動積分を,振動アルゴリズムが設計された形式に分割する.
| x∈(-∞,0] | "BesselInfiniteRangeMethod" |
| x∈[0,20] | "FourierFiniteRangeMethod" |
| x∈[30,∞) | "FourierInfiniteRangeMethod" |
| x∈[20,30] | Method |
オプション"FourierFiniteRangeMethod"に対する値Automaticは,オプションMethodにより指定される積分ストラテジーが"GlobalAdaptive"か"LocalAdaptive"のいずれかであれば,そのストラテジーが有限領域のフーリエ積分に使われ,そうでなければ"GlobalAdaptive"が使われることを意味している.
特定の振動メソッドの適用が特定のタイプの振動積分に要求されている場合,"OscillatorySelection"の対応するオプションを変更するか,NIntegrateのMethodオプションをプリプロセッサの"OscillatorySelection"なしで使うかしなければならない.
"UnitCubeRescaling"
"UnitCubeRescaling"は,積分領域を単位立方あるいは超立方に変換するプリプロセッサである.もとの被積分関数の変数が置き換えられると,結果は変換のヤコビアンで乗算される.
オプション名
|
デフォルト値
| |
| "FunctionalRangesOnly" | True | どの領域を単位立方に変換するか |
| Method | "GlobalAdaptive" | 積分が渡される積分ストラテジーあるいはプリプロセッサ |
| "SymbolicProcessing" | Automatic | 記号的処理を行う秒数 |
を超立方![]() 上の積分に変換する.
上の積分に変換する.![]() と
と ![]() が有限で
が有限で ![]() が区分的連続関数であるとすると,"UnitCubeRescaling"により使われる変換は
が区分的連続関数であるとすると,"UnitCubeRescaling"により使われる変換は
である.![]() 番目の軸に対して,
番目の軸に対して,![]() と
と ![]() のうちの一方もしくは両方が無限ならば,(46)の
のうちの一方もしくは両方が無限ならば,(46)の ![]() に対する公式は
に対する公式は![]() を
を![]() にマップする非アフィン変換である.NIntegrateは次の変換を使用する.
にマップする非アフィン変換である.NIntegrateは次の変換を使用する.
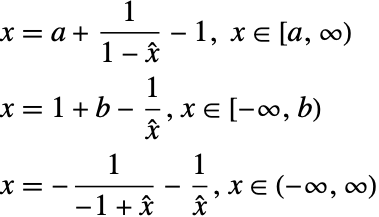
積分領域の境界が定数(有限・無限)ならば,"UnitCubeRescaling"を適用することで,被積分関数はより複雑になる.NIntegrateには効率的なアフィンと無限内部変数変換があるため,積分プロセスは遅くなる.積分領域境界のいくつかが関数ならば,"UnitCubeRescaling"を適用することで積分は速くなる.それは,積分変数を含む計算が被積分関数が評価されたときしか実行されないからである.このようなパフォーマンスについての考えがあるため,"UnitCubeRescaling"にはオプション"FunctionalRangesOnly"があるのである."FunctionalRangesOnly"がTrueに設定されると,再スケールは多次元関数範囲にだけ適用される.
例題の実装
"UnitCubeRescaling"で使用される変換プロセスは関数FRangesToCubeで実装される以下のものと同じである(「Duffyの座標の一般化と例題実装」でも定義してある).
変換(49)のそれぞれの変換はRescaleで実行することができる.
指定の軸 ![]() について,軸
について,軸![]() に対してすでに導出されている変換規則は,
に対してすでに導出されている変換規則は,![]() 番目の軸に沿った境界線を再スケールする前にもとの境界線に適用する必要がある.
番目の軸に沿った境界線を再スケールする前にもとの境界線に適用する必要がある.
"SymbolicPreprocessing"
"SymbolicPreprocessing"は他のプリプロセッサのオンとオフを簡約するために作られた合成プリプロセッサである.
オプション名
|
デフォルト値
| |
| Method | Automatic | 積分が渡される積分ストラテジーあるいはプリプロセッサ |
| "SymbolicPiecewiseSubdivision" | True | 区分的部分分割 |
| "EvenOddSubdivision" | True | 偶・奇部分分割 |
| "OscillatorySelection" | True | 振動関数での積の検出 |
| "UnitCubeRescaling" | Automatic | 単位超立方の再スケール |
| "SymbolicProcessing" | Automatic | 記号処理を行う秒数 |
"UnitCubeRescaling"がAutomaticに設定されると,それは多次元関数範囲にのみ適用される.