CategoricalDistribution
CategoricalDistribution[{c1,c2,…}]
在 c1、c2 等类别上表现均匀范畴分布.
CategoricalDistribution[{c1,c2,…},{w1,w2,…}]
在权重为 wi 的类别 ci 上表现范畴分布.
CategoricalDistribution[{{a1,a2,…},{b1,b2,…},…}]
在域 {a1,a2,…}×{b1,b2,…}×… 上表现多变量均匀范畴分布.
CategoricalDistribution[domain,weights]
用数组 weights 定义域中每个元素的概率.
更多信息和选项


- 范畴分布是一个离散分布,它的域由无序类别(如:"A"、"B"、"C")组成,通常用于对事物的有限集合进行概率测度.
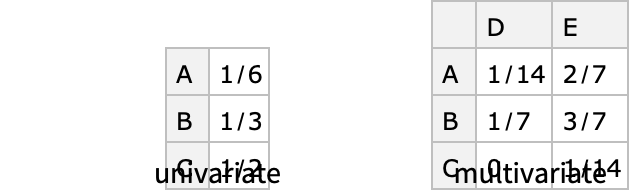
- 范畴分布可以有一个或多个变量. 列联表显示了域中每个元素的概率:
- CategoricalDistribution[…] 可用于诸如 RandomVariate、PDF、Probability 和 Expectation 之类的函数中.
- CategoricalDistribution[…] 不是数字分布:不能对其使用诸如 Mean 或 CDF 之类的函数.
- 在 CategoricalDistribution[domain,weights] 中,数组 weights 的维度必须与 domain 中定义的每个变量的类别数匹配.
- 可用 SparseArray[…] 形式给出数组 weights.
- 定义了权重的情况下,权重将被规范化为概率.
- CategoricalDistribution[{c1w1,c2w2,…}] 可用于定义类别 ci 和权重 wi.
- CategoricalDistribution[{{c11,c12,…}w1,elem2w2,…}] 可用于定义多元域元素 elemi(类的列表)及其权重 wi. 省略的元素默认权重为 0.
- 在 CategoricalDistribution[{elem1w1,elem2w2,…, _val}] 中,省略元素的权重为 val.
- CategoricalDistribution[domain,{elem1w1,elem2w2,…}] 可用于指定分布域和域中某些元素的概率.
- Information[CategoricalDistribution[…]] 给出有关该分布的报告.
- CategoricalDistribution 的 Information 包括以下属性:
-
"Categories" 分布类别列表 "Dimension" 变量的个数 "DomainElements" 域中的所有元素 "DomainSize" 域中元素的个数 "Entropy" 精确熵 "NEntropy" 近似熵 "Probabilities" 概率关联 "ProbabilityArray" 概率数组 "ProbabilityPlot" 概率函数可视化 "ProbabilityTable" Dataset 中的概率 "Properties" 所有可用属性 "TopProbabilities" 概率最高的元素的列表 "TopProbabilities"n 概率最高的 n 个元素
范例
打开所有单元关闭所有单元范围 (15)
单变量定义 (4)
多变量定义 (4)
信息 (2)
符号权重 (2)
域外行为 (1)
概率和期望 (2)
与使用 MarginalDistribution 计算相同概率所得到的结果进行比较:
用 Expectation 计算熵:
与 Information 给出的熵相比较:
用 NExpectation 计算熵:
应用 (2)
文本
Wolfram Research (2020),CategoricalDistribution,Wolfram 语言函数,https://reference.wolfram.com/language/ref/CategoricalDistribution.html.
CMS
Wolfram 语言. 2020. "CategoricalDistribution." Wolfram 语言与系统参考资料中心. Wolfram Research. https://reference.wolfram.com/language/ref/CategoricalDistribution.html.
APA
Wolfram 语言. (2020). CategoricalDistribution. Wolfram 语言与系统参考资料中心. 追溯自 https://reference.wolfram.com/language/ref/CategoricalDistribution.html 年