

ClusteringMeasurements
ClusteringMeasurements[{{e1,e2,…},…},meas]
returns the measurement meas for the clustered examples ei.
ClusteringMeasurements[clusters,gt,meas]
assumes the ground truth clustering gt.
Details and Options
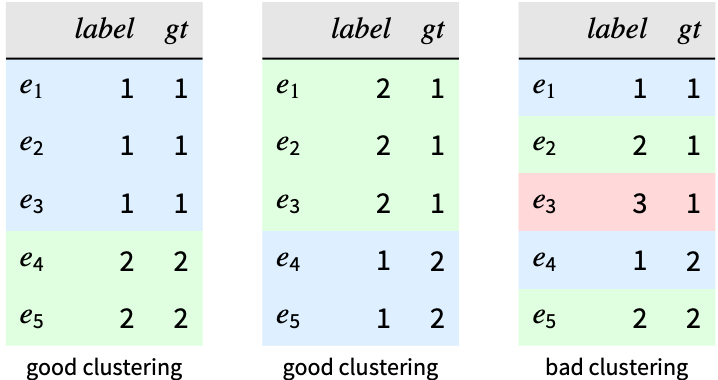
- ClusteringMeasurements is used to analyze the result of a clustering process. It can work with the clustered data alone or by comparing it with ground truth information.
- Possible clustering specification clusters include:
-
{{e1,e2,…},…} a list of clustered examples <l1{e1,e2,…},…> an association of clustered examples with label li {e1l1,e2l2,…} a list of examples and their correspondent cluster labels {e1,e2,…}{l1,l2,…} two separate lists for examples and labels {e1,e2,…}cfun an implicit classification via ClassifierFunction - Possible ground truth specifications gt include:
-
{{e1,e2,…},…} a list of example clusters <l1{e1,e2,…},…> an association of example lists labeled by cluster {e1l1,e2l2,…} list of examples and their correspondent cluster {e1,e2,…}{l1,l2,…} separate lists for examples and clusters {l1,l2,…} a list with cluster labels for each example - The measurements meas can have the form:
-
"Summary" a summary table of measurements "name" a specific measurement "name" {"name1","name2",…} a list of measuremetns All all possible measurements "Properties" a list of possible measurement names - Measurements can be divided in internals and externals.
- Internal measurements generally assume that good clusters have high separation and low dispersion.
- Common separation definitions (intercluster distances):
- Common dispersion definitions (intracluster distances):
- The notations 〈ei〉 and 〈e〉 represent the average over a cluster and over the whole dataset.
- Supported internal measurements meas include:
-
"CalinskiHarabasz" ratio between average separation and average centroid dispersion (maximize) "DaviesBouldin" average maximal ratio of the sum of centroid dispersions over centroid separation for a cluster pair (minimize) "Dunn" ratio of smallest minimal separation to dataset maximal dispersion (maximize) "RSquared" ratio of mean average dispersion to dataset centroid dispersion (elbow) "Silhouette" average difference between intercluster distance and intercluster distance for the next nearest cluster (maximize) "StandardDeviation" mean average dispersion (elbow) - Internal measurements that return a result per cluster or per example include:
-
"DaviesBouldinScore" maximal cluster similarity "RSquaredScore" ratio between cluster and overall dataset dispersion "SilhouetteScore" difference between intercluster distance and intercluster distance for the next nearest cluster "SilhouetteScoreList" per example slihouette value "StandardDeviationScore" average dispersion - External measurements compare the cluster assignment of an example ei with its ground truth value gt.
- Supported external measurements include:
-
"Purity" fraction of examples with the commonest ground truth assignment in their cluster (maximize) "Rand" fraction of (ei,ej) pairs that correctly share or do not share the same ground truth assignment (maximize) - External measurements that return a result per cluster or per example include:
-
"PurityScore" largest fraction of examples sharing the same ground truth assignment in each cluster "RandScore" fraction of (ei,ej) pairs that correctly share or do not share the same ground truth assignment in each cluster - ClusteringMeasurements[…,{"prop1","prop2",…}] can be used to compute multiple properties.
- ClusteringMeasurements supports the following options:
-
DistanceFunction Automatic the distance function to use FeatureExtractor Identity how to extract features from the examples - By default, the following distance functions are used for different types of elements:
-
EuclideanDistance numeric data ImageDistance images JaccardDissimilarity Boolean data EditDistance text and nominal sequences Abs[DateDifference[#1,#2]]& dates and times ColorDistance colors GeoDistance geospatial data Boole[SameQ[#1,#2]]& nominal data HammingDistance nominal vector data WarpingDistance numerical sequences
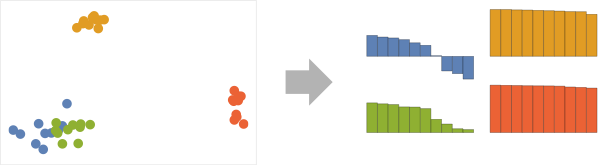
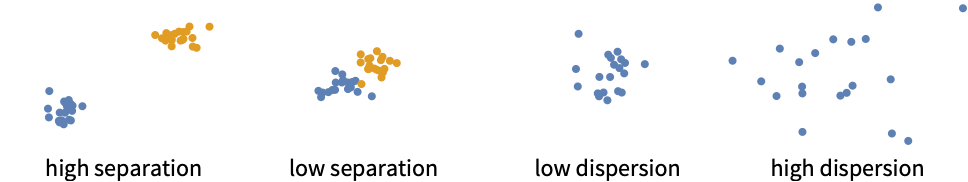
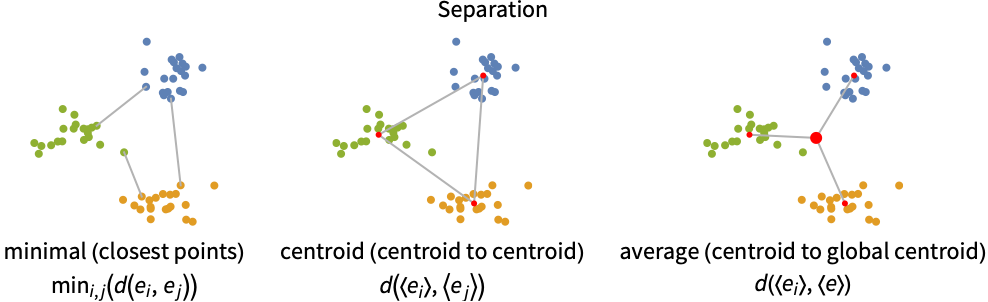
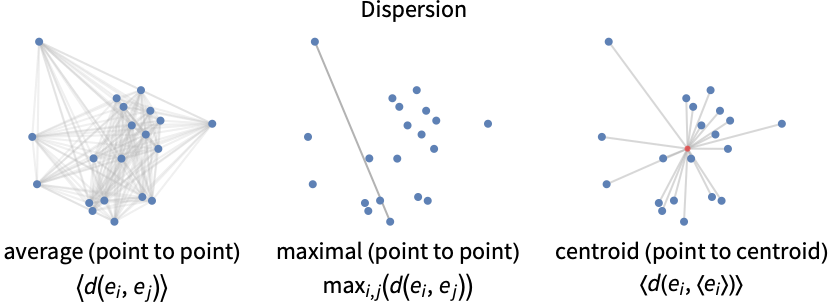
Examples
open all close allBasic Examples (2)
Get a summary of the clustering measurements:
ClusteringMeasurements[{{{0.79, 0.56}, {0.71, 0.48}}, {{0.48, 0.033}, {0.66, -0.18}, {0.71, -0.021}}, {{-0.88, 0.12}, {-0.90, 0.092}}}, "Summary"]Compute the silhouette score for a group of clusters:
ClusteringMeasurements[<|"A" -> {RGBColor[0.876608492574193, 0.9473400809250909, 0.25067253612711804], RGBColor[0.9272661633421619, 0.9363261805264331, 0.32353349989516933], RGBColor[0.8243947208728843, 0.9364356599106853, 0.435400674336722], RGBColor[0.9057946589188117, 0.9381773467978105, 0.016447357477133107]}, "B" -> {RGBColor[0.5219642502018771, 0.5017220835545622, 0.9175588985597154], RGBColor[0.08280489339492836, 0.41421577414235555, 0.9357625935021598], RGBColor[0.21636803014287387, 0.23382792797523244, 0.5159899501126328], RGBColor[0.40815049823996064, 0.5740819900353236, 0.9231104239323873], RGBColor[0.08642430807107115, 0.281127551566819, 0.6649469000247543], RGBColor[0.3506031248835497, 0.42471407043932174, 0.8278435761417782], RGBColor[0.16525562567118945, 0.5125318540604438, 0.8296464274479893]}, "C" -> {RGBColor[0.08622342695413243, 0.71879922942928, 0.765413236947557], RGBColor[0.4238352228971154, 0.6931876506845667, 0.7117293054980371], RGBColor[0.4712616494486832, 0.8178536200085944, 0.8565962988336242], RGBColor[0.1496529618394109, 0.701645179917191, 0.7804714896485088], RGBColor[0.6973467249643173, 0.8294373633128278, 0.8957452203075256], RGBColor[0.7093533212993834, 0.8150926594568284, 0.7811722698229906], RGBColor[0.04515994704540893, 0.935387695243086, 0.21554127051988736], RGBColor[0.1505455345874276, 0.9945961988546483, 0.47401708153690225]}|>, "SilhouetteScore"]Visualize the scores in a bar chart:
BarChart[%, ChartLabels -> Automatic]Compute and chart the silhouette score for individual examples:
ClusteringMeasurements[{{RGBColor[0.876608492574193, 0.9473400809250909, 0.25067253612711804], RGBColor[0.9272661633421619, 0.9363261805264331, 0.32353349989516933], RGBColor[0.8243947208728843, 0.9364356599106853, 0.435400674336722], RGBColor[0.9057946589188117, 0.9381773467978105, 0.016447357477133107]}, {RGBColor[0.5219642502018771, 0.5017220835545622, 0.9175588985597154], RGBColor[0.08280489339492836, 0.41421577414235555, 0.9357625935021598], RGBColor[0.21636803014287387, 0.23382792797523244, 0.5159899501126328], RGBColor[0.40815049823996064, 0.5740819900353236, 0.9231104239323873], RGBColor[0.08642430807107115, 0.281127551566819, 0.6649469000247543], RGBColor[0.3506031248835497, 0.42471407043932174, 0.8278435761417782], RGBColor[0.16525562567118945, 0.5125318540604438, 0.8296464274479893]}, {RGBColor[0.08622342695413243, 0.71879922942928, 0.765413236947557], RGBColor[0.4238352228971154, 0.6931876506845667, 0.7117293054980371], RGBColor[0.4712616494486832, 0.8178536200085944, 0.8565962988336242], RGBColor[0.1496529618394109, 0.701645179917191, 0.7804714896485088], RGBColor[0.6973467249643173, 0.8294373633128278, 0.8957452203075256], RGBColor[0.7093533212993834, 0.8150926594568284, 0.7811722698229906], RGBColor[0.04515994704540893, 0.935387695243086, 0.21554127051988736], RGBColor[0.1505455345874276, 0.9945961988546483, 0.47401708153690225]}}, "SilhouetteScoreList"]BarChart[%, ChartStyle -> {ColorData[96], None}]Scope (9)
Data Formats (5)
Specify the clusters explicitly in a list:
ClusteringMeasurements[{{{0.79, 0.56}, {0.71, 0.48}}, {{0.48, 0.033}, {0.66, -0.18}, {0.71, -0.021}}, {{-0.88, 0.12}, {-0.90, 0.092}}}, "DaviesBouldin"]Specify the clusters explicitly in an association:
ClusteringMeasurements[<|1 -> {{0.79, 0.56}, {0.71, 0.48}}, 2 -> {{0.48, 0.033}, {0.66, -0.18}, {0.71, -0.021}}, 3 -> {{-0.88, 0.12}, {-0.9, 0.092}}|>, "DaviesBouldin"]Specify the clusters by a list of rules between examples and assignments:
ClusteringMeasurements[{{0.79, 0.56} -> 1, {0.71, 0.48} -> 1, {0.48, 0.033} -> 2, {0.66, -0.18} -> 2, {0.71, -0.021} -> 2, {-0.88, 0.12} -> 3, {-0.9, 0.092} -> 3}, "DaviesBouldin"]Specify the clusters by a rule between examples and assignments:
ClusteringMeasurements[{{0.79, 0.56}, {0.71, 0.48}, {0.48, 0.033}, {0.66, -0.18}, {0.71, -0.021}, {-0.88, 0.12}, {-0.9, 0.092}} -> {1, 1, 2, 2, 2, 3, 3}, "DaviesBouldin"]Specify the clusters by a rule between examples and a ClassifierFunction[…]:
data = {{0.79, 0.56}, {0.71, 0.48}, {0.48, 0.033}, {0.66, -0.18}, {0.71, -0.021}, {-0.88, 0.12}, {-0.9, 0.092}};cfun = ClusterClassify[data]ClusteringMeasurements[data -> cfun, "DaviesBouldin"]Measurements (4)
Compute a clustering property:
ClusteringMeasurements[{{RGBColor[0.876608492574193, 0.9473400809250909, 0.25067253612711804], RGBColor[0.9272661633421619, 0.9363261805264331, 0.32353349989516933], RGBColor[0.8243947208728843, 0.9364356599106853, 0.435400674336722]}, {RGBColor[0.5219642502018771, 0.5017220835545622, 0.9175588985597154], RGBColor[0.08280489339492836, 0.41421577414235555, 0.9357625935021598], RGBColor[0.21636803014287387, 0.23382792797523244, 0.5159899501126328], RGBColor[0.40815049823996064, 0.5740819900353236, 0.9231104239323873]}, {RGBColor[0.08622342695413243, 0.71879922942928, 0.765413236947557], RGBColor[0.4238352228971154, 0.6931876506845667, 0.7117293054980371], RGBColor[0.1496529618394109, 0.701645179917191, 0.7804714896485088]}, {RGBColor[0.3779129543048858, 0.9299217761823355, 0.05300428332934981], RGBColor[0.47933167047242464, 0.8484812906095962, 0.25070732863307543], RGBColor[0.2639731675000303, 0.8447135871358933, 0.17741459618375854], RGBColor[0.10553834214315283, 0.7432472973816968, 0.23144281661937094]}, {RGBColor[0.12261520318947783, 0.02938259624263395, 0.1917186445336998]}}, "Dunn"]ClusteringMeasurements[{{RGBColor[0.876608492574193, 0.9473400809250909, 0.25067253612711804], RGBColor[0.9272661633421619, 0.9363261805264331, 0.32353349989516933], RGBColor[0.8243947208728843, 0.9364356599106853, 0.435400674336722]}, {RGBColor[0.5219642502018771, 0.5017220835545622, 0.9175588985597154], RGBColor[0.08280489339492836, 0.41421577414235555, 0.9357625935021598], RGBColor[0.21636803014287387, 0.23382792797523244, 0.5159899501126328], RGBColor[0.40815049823996064, 0.5740819900353236, 0.9231104239323873]}, {RGBColor[0.08622342695413243, 0.71879922942928, 0.765413236947557], RGBColor[0.4238352228971154, 0.6931876506845667, 0.7117293054980371], RGBColor[0.1496529618394109, 0.701645179917191, 0.7804714896485088]}, {RGBColor[0.3779129543048858, 0.9299217761823355, 0.05300428332934981], RGBColor[0.47933167047242464, 0.8484812906095962, 0.25070732863307543], RGBColor[0.2639731675000303, 0.8447135871358933, 0.17741459618375854], RGBColor[0.10553834214315283, 0.7432472973816968, 0.23144281661937094]}, {RGBColor[0.12261520318947783, 0.02938259624263395, 0.1917186445336998]}}, {"Dunn", "RSquared"}]Compute a summary of the global measurements:
ClusteringMeasurements[{{RGBColor[0.876608492574193, 0.9473400809250909, 0.25067253612711804], RGBColor[0.9272661633421619, 0.9363261805264331, 0.32353349989516933], RGBColor[0.8243947208728843, 0.9364356599106853, 0.435400674336722]}, {RGBColor[0.5219642502018771, 0.5017220835545622, 0.9175588985597154], RGBColor[0.08280489339492836, 0.41421577414235555, 0.9357625935021598], RGBColor[0.21636803014287387, 0.23382792797523244, 0.5159899501126328], RGBColor[0.40815049823996064, 0.5740819900353236, 0.9231104239323873]}, {RGBColor[0.08622342695413243, 0.71879922942928, 0.765413236947557], RGBColor[0.4238352228971154, 0.6931876506845667, 0.7117293054980371], RGBColor[0.1496529618394109, 0.701645179917191, 0.7804714896485088]}, {RGBColor[0.3779129543048858, 0.9299217761823355, 0.05300428332934981], RGBColor[0.47933167047242464, 0.8484812906095962, 0.25070732863307543], RGBColor[0.2639731675000303, 0.8447135871358933, 0.17741459618375854], RGBColor[0.10553834214315283, 0.7432472973816968, 0.23144281661937094]}, {RGBColor[0.12261520318947783, 0.02938259624263395, 0.1917186445336998]}}, "Summary"]Get a list of available properties:
ClusteringMeasurements[{{RGBColor[0.876608492574193, 0.9473400809250909, 0.25067253612711804], RGBColor[0.9272661633421619, 0.9363261805264331, 0.32353349989516933], RGBColor[0.8243947208728843, 0.9364356599106853, 0.435400674336722]}, {RGBColor[0.5219642502018771, 0.5017220835545622, 0.9175588985597154], RGBColor[0.08280489339492836, 0.41421577414235555, 0.9357625935021598], RGBColor[0.21636803014287387, 0.23382792797523244, 0.5159899501126328], RGBColor[0.40815049823996064, 0.5740819900353236, 0.9231104239323873]}, {RGBColor[0.08622342695413243, 0.71879922942928, 0.765413236947557], RGBColor[0.4238352228971154, 0.6931876506845667, 0.7117293054980371], RGBColor[0.1496529618394109, 0.701645179917191, 0.7804714896485088]}, {RGBColor[0.3779129543048858, 0.9299217761823355, 0.05300428332934981], RGBColor[0.47933167047242464, 0.8484812906095962, 0.25070732863307543], RGBColor[0.2639731675000303, 0.8447135871358933, 0.17741459618375854], RGBColor[0.10553834214315283, 0.7432472973816968, 0.23144281661937094]}, {RGBColor[0.12261520318947783, 0.02938259624263395, 0.1917186445336998]}}, "Properties"]Get a list of available properties when a ground truth is specified:
ClusteringMeasurements[{{RGBColor[0.876608492574193, 0.9473400809250909, 0.25067253612711804], RGBColor[0.9272661633421619, 0.9363261805264331, 0.32353349989516933], RGBColor[0.8243947208728843, 0.9364356599106853, 0.435400674336722]}, {RGBColor[0.5219642502018771, 0.5017220835545622, 0.9175588985597154], RGBColor[0.08280489339492836, 0.41421577414235555, 0.9357625935021598], RGBColor[0.21636803014287387, 0.23382792797523244, 0.5159899501126328], RGBColor[0.40815049823996064, 0.5740819900353236, 0.9231104239323873]}, {RGBColor[0.08622342695413243, 0.71879922942928, 0.765413236947557], RGBColor[0.4238352228971154, 0.6931876506845667, 0.7117293054980371], RGBColor[0.1496529618394109, 0.701645179917191, 0.7804714896485088]}, {RGBColor[0.3779129543048858, 0.9299217761823355, 0.05300428332934981], RGBColor[0.47933167047242464, 0.8484812906095962, 0.25070732863307543], RGBColor[0.2639731675000303, 0.8447135871358933, 0.17741459618375854], RGBColor[0.10553834214315283, 0.7432472973816968, 0.23144281661937094]}, {RGBColor[0.12261520318947783, 0.02938259624263395, 0.1917186445336998]}}, <|1 -> {RGBColor[0.876608492574193, 0.9473400809250909, 0.25067253612711804], RGBColor[0.9272661633421619, 0.9363261805264331, 0.32353349989516933], RGBColor[0.8243947208728843, 0.9364356599106853, 0.435400674336722]}, 2 -> {RGBColor[0.5219642502018771, 0.5017220835545622, 0.9175588985597154], RGBColor[0.08280489339492836, 0.41421577414235555, 0.9357625935021598], RGBColor[0.40815049823996064, 0.5740819900353236, 0.9231104239323873]}, 3 -> {RGBColor[0.08622342695413243, 0.71879922942928, 0.765413236947557], RGBColor[0.4238352228971154, 0.6931876506845667, 0.7117293054980371], RGBColor[0.1496529618394109, 0.701645179917191, 0.7804714896485088]}, 4 -> {RGBColor[0.3779129543048858, 0.9299217761823355, 0.05300428332934981], RGBColor[0.47933167047242464, 0.8484812906095962, 0.25070732863307543], RGBColor[0.2639731675000303, 0.8447135871358933, 0.17741459618375854], RGBColor[0.10553834214315283, 0.7432472973816968, 0.23144281661937094]}, 5 -> {RGBColor[0.12261520318947783, 0.02938259624263395, 0.1917186445336998], RGBColor[0.21636803014287387, 0.23382792797523244, 0.5159899501126328]}|>, "Properties"]Options (2)
DistanceFunction (1)
FeatureExtractor (1)
Specify a custom feature extractor to pre-process the examples:
extractor = NetDrop[NetModel["ShuffleNet-V2 Trained on ImageNet Competition Data"], -2];ClusteringMeasurements[{{[image], [image], [image]}, {[image], [image], [image]}}, "Dunn", FeatureExtractor -> extractor]Applications (2)
Find the optimal cluster number on a synthetic dataset:
SeedRandom[1234];clusters = Map[m RandomVariate[MultinormalDistribution[m, .01IdentityMatrix[2]], 20], RandomReal[{-1, 1}, {5, 2}]];ListPlot[clusters, PlotTheme -> "Minimal"]Combine the different groups in a random permutation:
data = RandomSample@Catenate[clusters];Compute the k-mean clustering for different values of k:
groupings = Table[FindClusters[data, n, Method -> "KMeans"], {n, 1, 10}];Measure the Dunn index of each set of clusters:
ClusteringMeasurements[#, "Dunn"]& /@ groupingsThe optimal clustering is at 5 clusters:
ListPlot[%, Filling -> Bottom]The clustering process was able to recover all the original groups:
ListPlot[groupings[[5]], PlotTheme -> "Minimal"]Visualize the Silhouette score for each point in a clustering:
SeedRandom[2345];data = Catenate@Map[m RandomVariate[MultinormalDistribution[m, .01IdentityMatrix[2]], 20], RandomReal[{-1, 1}, {5, 2}]];Compute the k-mean clustering a given k:
FindClusters[data, 4, Method -> "KMeans"]//ShortVisualize the Silhouette score:
BarChart[ClusteringMeasurements[%, "SilhouetteScoreList"], ChartStyle -> {ColorData[97], None}]Compute the k-mean clustering for different values of k:
groupings = Table[FindClusters[data, n, Method -> "KMeans"], {n, {3, 4, 5, 6, 7}}];Plot each set of clusters with the correspondent Silhouette profile:
Table[
GraphicsRow[{
ListPlot[groupings[[i]], PlotTheme -> "Minimal", PlotStyle -> PointSize[Medium]],
BarChart[ReverseSort /@ ClusteringMeasurements[groupings[[i]], "SilhouetteScoreList"], ChartStyle -> {ColorData[97], None}, PlotRange -> {-.5, 1}]}, ImageSize -> Medium],
{i, 1, Length[groupings], 1}]Possible Issues (1)
External measurements require a ground truth specification:
ClusteringMeasurements[{{RGBColor[0.876608492574193, 0.9473400809250909, 0.25067253612711804], RGBColor[0.9272661633421619, 0.9363261805264331, 0.32353349989516933], RGBColor[0.8243947208728843, 0.9364356599106853, 0.435400674336722]}, {RGBColor[0.5219642502018771, 0.5017220835545622, 0.9175588985597154], RGBColor[0.08280489339492836, 0.41421577414235555, 0.9357625935021598], RGBColor[0.21636803014287387, 0.23382792797523244, 0.5159899501126328]}, {RGBColor[0.40815049823996064, 0.5740819900353236, 0.9231104239323873], RGBColor[0.08622342695413243, 0.71879922942928, 0.765413236947557], RGBColor[0.4238352228971154, 0.6931876506845667, 0.7117293054980371]}}, "Purity"]ClusteringMeasurements[{{RGBColor[0.876608492574193, 0.9473400809250909, 0.25067253612711804], RGBColor[0.9272661633421619, 0.9363261805264331, 0.32353349989516933], RGBColor[0.8243947208728843, 0.9364356599106853, 0.435400674336722]}, {RGBColor[0.5219642502018771, 0.5017220835545622, 0.9175588985597154], RGBColor[0.08280489339492836, 0.41421577414235555, 0.9357625935021598], RGBColor[0.21636803014287387, 0.23382792797523244, 0.5159899501126328]}, {RGBColor[0.40815049823996064, 0.5740819900353236, 0.9231104239323873], RGBColor[0.08622342695413243, 0.71879922942928, 0.765413236947557], RGBColor[0.4238352228971154, 0.6931876506845667, 0.7117293054980371]}}, {{RGBColor[0.876608492574193, 0.9473400809250909, 0.25067253612711804], RGBColor[0.9272661633421619, 0.9363261805264331, 0.32353349989516933], RGBColor[0.8243947208728843, 0.9364356599106853, 0.435400674336722]}, {RGBColor[0.5219642502018771, 0.5017220835545622, 0.9175588985597154], RGBColor[0.08280489339492836, 0.41421577414235555, 0.9357625935021598], RGBColor[0.21636803014287387, 0.23382792797523244, 0.5159899501126328], RGBColor[0.40815049823996064, 0.5740819900353236, 0.9231104239323873]}, {RGBColor[0.08622342695413243, 0.71879922942928, 0.765413236947557], RGBColor[0.4238352228971154, 0.6931876506845667, 0.7117293054980371]}}, "Purity"]Interactive Examples (1)
Cluster a list of points interactively measuring the Calinski–Harabasz index:
Manipulate[
Show[
ListPlot[groups = Values@KeySort@GroupBy[{...}, Nearest[pt -> Automatic]], PlotTheme -> "NoAxes", PlotLabel -> StringForm["Calinski-Harabasz Index: ``", ClusteringMeasurements[groups, "CalinskiHarabasz"]]],
VoronoiMesh[pt, 2{{-1, 1}, {-1, 1}}, PlotTheme -> "Lines", MeshCellStyle -> {1} -> Gray],
PlotRange -> {{-1, 1}, {-1, 1}}, ImageSize -> Medium, Frame -> True
],
{{pt, .3{{-1, 0}, {0, -1}, {1, 1}}}, Locator, LocatorAutoCreate -> 2},
{groups, ControlType -> None}, AppearanceElements -> None
]Text
Wolfram Research (2022), ClusteringMeasurements, Wolfram Language function, https://reference.wolfram.com/language/ref/ClusteringMeasurements.html.
CMS
Wolfram Language. 2022. "ClusteringMeasurements." Wolfram Language & System Documentation Center. Wolfram Research. https://reference.wolfram.com/language/ref/ClusteringMeasurements.html.
APA
Wolfram Language. (2022). ClusteringMeasurements. Wolfram Language & System Documentation Center. Retrieved from https://reference.wolfram.com/language/ref/ClusteringMeasurements.html