

GatedRecurrentLayer
表示一个可训练的循环层,接受一个向量序列,产生由大小为 n 的向量组成的序列.
GatedRecurrentLayer[n,opts]
包含初始权重和其他参数的选项.
更多信息和选项




- GatedRecurrentLayer[n] 表示采用表示向量序列的输入矩阵并输出相同长度序列的网络.
- 输入序列的每个元素是一个大小为 k 的向量,输出序列的每个元素是一个大小为 n 的向量.
- 在 NetGraph、NetChain 等中,输入向量的大小 k 通常自动推断得出.
- GatedRecurrentLayer[n] 所表示的网络的输入端口和输出端口为:
-
"Input" 由大小为 k 的向量组成的序列 "Output" 由大小为 n 的向量组成的序列 - 给定输入序列 {x1,x2,…,xn},GatedRecurrentLayer 利用下列循环关系式输出状态序列 {s1,s2,…,sn}:
-
输入门 it=LogisticSigmoid[Wix.xt+Wis.st-1+bi] 重置门 rt=LogisticSigmoid[Wrx.xt+Wrs.st-1+br] 记忆门 mt=Tanh[Wmx.xt+Wms.(rt* st-1)+bm] 状态 st=(1-it)*mt+it*st-1 - GatedRecurrentLayer 的上述定义基于由 Chung 等在 Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling, 2014 中描述的变量.
- GatedRecurrentLayer[n] 还有一个状态端口 "State",它是一个大小为 n 的向量.
- 在 NetGraph 中,可以使用形式为 src->NetPort[layer,"State"] 的连接提供 GatedRecurrentLayer 的状态的初始值,对应于循环关系式中的 s0. 缺省的初始值为零向量.
- 在 NetGraph 中,可以用形式为 NetPort[layer,"State"]->dst 的连接来获取 GatedRecurrentLayer 的状态的终值,它对应于循环关系中的 sT.
- NetStateObject 可以用来创建一个网络,该网络将记住当网络应用于输入时 GatedRecurrentLayer 的状态更新后的值.
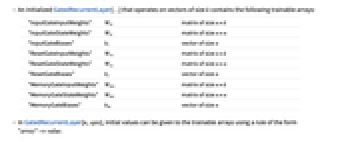
- 在大小为 k 的向量上操作的初始化过的 GatedRecurrentLayer[…] 含有下列可训练的数组:
-
"InputGateInputWeights" Wix 大小为 n×k 的矩阵 "InputGateStateWeights" Wis 大小为 n×n 的矩阵 "InputGateBiases" bi 大小为 n 的向量 "ResetGateInputWeights" Wrx 大小为 n×k 的矩阵 "ResetGateStateWeights" Wrs 大小为 n×n 的矩阵 "ResetGateBiases" br 大小为 n 的向量 "MemoryGateInputWeights" Wmx 大小为 n×k 的矩阵 "MemoryGateStateWeights" Wms 大小为 n×n 的矩阵 "MemoryGateBiases" bm 大小为 n 的向量 - 在 GatedRecurrentLayer[n,opts] 中,可以用形式为 "array"->value 的规则把初值赋给可训练数组.
- 可包括以下训练参数:
-
"Dropout" None dropout 规则,其中,根据概率将单元设为零 LearningRateMultipliers Automatic 可训练数组的学习率乘子 - 指定 "Dropout"->None 将禁止在训练时进行 dropout.
- 指定 "Dropout"->p 将以 dropout 概率 p 应用自动选择的 dropout 方法.
- 指定 "Dropout"->{"method1"->p1,"method2"->p2,…} 可用来按相应的 dropout 概率组合不同的 dropout 方法. 可能的方法包括:
-
"VariationalWeights" dropout 应用于权重矩阵(默认)之间的递归连接 "VariationalInput" 对来自输入的门贡献 (gate contribution) 应用 dropout,在序列中的每一步使用同样模式的单元 "VariationalState" 对来自前面状态的门贡献 (gate contribution) 应用 dropout,在序列中的每一步使用同样模式的单元 "StateUpdate" 在加到前面的状态之前,对状态更新向量应用 dropout,在序列中的每一步使用不同模式的单元 - dropout 方法 "VariationalInput" 和 "VariationalState" 是基于 Gal et al. 2016 方法,其中, "StateUpdate" 是基于 Semeniuta et al. 2016 方法,"VariationalWeights"是基于 Merity 等 2017 方法.
- GatedRecurrentLayer[n,"Input"->shape] 允许指定输入的形状. shape 的可能的形式为:
-
NetEncoder[…] 生成向量序列的编码器 {len,k} 由 len 个长度为 k 的向量组成的序列 {len,Automatic} 由 len 个向量组成的序列,其中向量的长度由推断而得 {"Varying",k} 不同数量的向量,每个向量的长度为 k {"Varying",Automatic} 不同数量的向量,每个向量的长度由推断而得 - 当 NumericArray 作为输入时,输出将是 NumericArray.
- Options[GatedRecurrentLayer] 给出构建网络层的默认选项列表. Options[GatedRecurrentLayer[…]] 给出在某些数据上运行网络层的默认选项列表.
- Information[GatedRecurrentLayer[…]] 给出关于网络层的报告.
- Information[GatedRecurrentLayer[…],prop] 给出 GatedRecurrentLayer[…] 的属性 prop 的值. 可能的属性与 NetGraph 相同.
范例
打开所有单元 关闭所有单元基本范例 (2)
创建一个 GatedRecurrentLayer,产生由长度为 3 的向量组成的序列:
创建一个随机初始化的 GatedRecurrentLayer,接受由长度为 2 的向量组成的序列,产生由长度为 3 的向量组成的序列:
范围 (5)
Arguments (1)
创建一个 GatedRecurrentLayer,生成长度为 3 的向量序列:
Ports (4)
创建一个随机初始化的 GatedRecurrentLayer,接受一个字符串, 产生由长度为 2 的向量组成的序列:
创建一个随机初始化的网络,接受由长度为 2 的向量组成的序列,产生一个长度为 3 的向量:
创建一个 NetGraph,允许设置 GatedRecurrentLayer 的初始状态:
创建一个 NetGraph,允许获取 GatedRecurrentLayer 的终态:
选项 (2)
"Dropout" (2)
创建一个 GatedRecurrentLayer,同时指定 dropout 方法:
创建一个随机初始化的、具有指定 dropout 概率的 GatedRecurrentLayer:
用 NetEvaluationMode 来强制 dropout 的训练行为:
应用 (2)
产生训练数据,由描述两位数相加及其相应数值结果的字符串组成:
使用堆叠的、读取输入字符串并预测数值结果的 GatedRecurrentLayer 层创建一个网络:
基于含有 x 和 y 的字符串创建训练数据,通过比较 x 和 y 的数量得出 Less、Greater 或 Equal. 训练数据由最长为 8 的所有可能的字符串组成:
创建含有 GatedRecurrentLayer 的网络,读入一个字符串,预测是 Less、Greater 还是 Equal:
属性和关系 (1)
NetStateObject 可用来创建一个能记住 GatedRecurrentLayer 的状态的网络:
每次计算都将改变储存在 NetStateObject 中的状态:
文本
Wolfram Research (2017),GatedRecurrentLayer,Wolfram 语言函数,https://reference.wolfram.com/language/ref/GatedRecurrentLayer.html.
CMS
Wolfram 语言. 2017. "GatedRecurrentLayer." Wolfram 语言与系统参考资料中心. Wolfram Research. https://reference.wolfram.com/language/ref/GatedRecurrentLayer.html.
APA
Wolfram 语言. (2017). GatedRecurrentLayer. Wolfram 语言与系统参考资料中心. 追溯自 https://reference.wolfram.com/language/ref/GatedRecurrentLayer.html 年