LogitModelFit[{{x1,y1},{x2,y2},…},{f1,f2,…},x]
构建形为 ![]() 的二项式逻辑回归模型,拟合每个 xi 的 yi.
的二项式逻辑回归模型,拟合每个 xi 的 yi.
LogitModelFit[data,{f1,…},{x1,x2,…}]
构建一个二项式逻辑回归模型,形式为 ![]() ,其中 fi 与变量 xk 相关.
,其中 fi 与变量 xk 相关.




LogitModelFit
LogitModelFit[{{x1,y1},{x2,y2},…},{f1,f2,…},x]
构建形为 ![]() 的二项式逻辑回归模型,拟合每个 xi 的 yi.
的二项式逻辑回归模型,拟合每个 xi 的 yi.
LogitModelFit[data,{f1,…},{x1,x2,…}]
构建一个二项式逻辑回归模型,形式为 ![]() ,其中 fi 与变量 xk 相关.
,其中 fi 与变量 xk 相关.
LogitModelFit[{m,v}]
从设计矩阵 m 和响应向量 v 构建一个二项式逻辑回归模型.
更多信息和选项


- LogitModelFit 尝试使用由逻辑 S 型函数组成的基函数的线性组合来对数据建模.
- LogitModelFit 通常在分类中使用,用来模拟概率值.
- LogitModelFit 给出形为
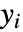 的通用线性模型,假定原始的
的通用线性模型,假定原始的  是概率为
是概率为 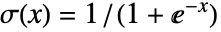 的伯努利试验的独立实现.
的伯努利试验的独立实现. - 函数
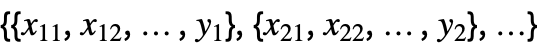 为 LogisticSigmoid.
为 LogisticSigmoid. - LogitModelFit 返回一个符号 FittedModel 对象,表示构建的逻辑模型. 模型的属性和诊断可以从 model["property"] 得到.
- LogitModelFit 在特定点 x1、… 的最佳拟合函数的值可以从 model[x1,…] 求出.
- data 的可能的形式为:
-
{y1,y2,…} 与形式 {{1,y1},{2,y2},…} 等价 {{x11,x12,…,y1},…} 独立值 xij 列表和响应 yi {{x11,x12,…}y1,…} 输入值和响应构成的规则列表 {{x11,x12,…},…}{y1,y2,…} 输入值列表和响应构成的规则 {{x11,…,y1,…},…}n 拟合矩阵的第 n 列 Tabular[…]name 拟合表格对象中名为 name 的列 - 在多元数据的情况下,如
,x_(12),... ,y_(1)},{x_(21),x_(22),... ,y_(2)},...}") ,坐标 xi1、xi2、… 的数量应等于变量 xi 的数量.
,坐标 xi1、xi2、… 的数量应等于变量 xi 的数量. - yi 的概率位于 0 和 1 之间.
- 另外,可用设计矩阵指定 data,不指定函数和变量:
-
{m,v} 设计矩阵 m 和响应向量 v - 在 LogitModelFit[{m,v}] 中,设计矩阵 m 根据在点 {{f1,f2,…},{f1,f2,…},…} 的基函数 fi 形成. 响应向量 v 是响应列表 {y1,y2,…}.
- 对于一个设计矩阵 m 和响应向量 v,模型是
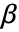 ,其中
,其中 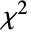 是估计参数的向量.
是估计参数的向量. - 当使用一个设计矩阵,基函数 fi 可以用形式 LogitModelFit[{m,v},{f1,f2,…}] 指定.
- LogitModelFit 等价于 GeneralizedLinearModelFit,其中 ExponentialFamily->"Binomial" 和 LinkFunction->Automatic.
- LogitModelFit 采用和 GeneralizedLinearModelFit 相同的选项,除了 ExponentialFamily 和 LinkFunction.
范例
打开所有单元 关闭所有单元范围 (13)
数据 (6)
属性 (7)
选项 (8)
属性和关系 (4)
GeneralizedLinearModelFit 中一个缺省的 "Binomial" 模型等价于 LogitModelFit 的模型:
ProbitModelFit 等价于有 "ProbitLink" 的一个 "Binomial" 模型:
LogitModelFit 假设二项分布响应:
NonlinearModelFit 通常假设分布响应:
LogitModelFit 会将 TimeSeries 的时间戳用作变量:
对于多路径 TemporalData,LogitModelFit 按路径分别处理:
文本
Wolfram Research (2008),LogitModelFit,Wolfram 语言函数,https://reference.wolfram.com/language/ref/LogitModelFit.html (更新于 2025 年).
CMS
Wolfram 语言. 2008. "LogitModelFit." Wolfram 语言与系统参考资料中心. Wolfram Research. 最新版本 2025. https://reference.wolfram.com/language/ref/LogitModelFit.html.
APA
Wolfram 语言. (2008). LogitModelFit. Wolfram 语言与系统参考资料中心. 追溯自 https://reference.wolfram.com/language/ref/LogitModelFit.html 年