CSV (.csv)
背景

-
- MIME 类型:text/comma-separated-values,text/csv
- CSV 表格数据格式.
- 按行来存储数值和文本信息,使用逗号分隔字段.
- 通常作为交换格式用于电子表格应用程序.
- CSV 是 Comma-Separated Values(逗号分隔的值)的缩写.
- 纯文本格式.
- 与 TSV 类似.
- 支持 RFC 4180.
Import 与 Export

- Import["file.csv"] 返回包含字符串和数字的列表的列表,表示存储在文件中的行与列.
- Import["file.csv",elem] 从一个 CSV 文件中导入指定的参数.
- Import["file.csv",{elem,subelem1,…}] 导入子参数 subelemi,对于导入部分数据非常有用.
- 导入格式可以用 Import["file","CSV"] 或 Import["file",{"CSV",elem,…}] 指定.
- Export["file.csv",expr] 从 expr 创建一个 CSV 文件.
- 支持 expr 的表达式包括:
-
{v1,v2,…} 单列数据 {{v11,v12,…},{v21,v22,…},…} 数据的列表行 array 例如 SparseArray、QuantityArray 等的数组 tseries 一个 TimeSeries、EventSeries 或一个 TemporalData 对象 Dataset[…] 一个数据集 - 请到以下参考页面了解完整的基本信息:
-
Import, Export 从文件导入或导出到文件 CloudImport, CloudExport 从云对象导入或导出到云对象 ImportString, ExportString 从字符串导入或导出到字符串 ImportByteArray, ExportByteArray 从字节数组导入或导出到字节数组
Import 参数

- Import 通用参数:
-
"Elements" 该文件可用的参数和选项列表 "Summary" 文件摘要 "Rules" 所有可用参数的规则列表 - 表示数据的参数:
-
"Data" 二维数组 "Grid" 将数据作为 Grid 对象表格 "RawData" 字符串的二维数组 "Dataset" 将数据作为 Dataset - 默认情况下,Import 与 Export 使用"Data"参数.
- 导入部分数据的子参数,任何数据表示参数 elem 可以使用 {elem, rows, cols} 格式指定行列,其中 rows 和 cols 可为以下任意:
-
n 第 n 行或列 -n 从结尾计算 n;;m 从 n 到 m n;;m;;s 从 n 到 m,步长为 s {n1,n2,…} 指定行或列 ni - 元数据参数:
-
"Dimensions" 行数列表和最大列数 "MaxColumnCount" 最大列数 "RowCount" 行数
选项

- Import 与 Export 选项:
-
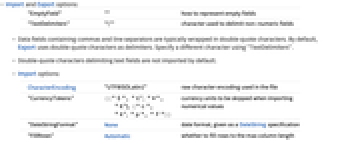
"EmptyField" "" 如何表示空白字段 "TextDelimiters" "\"" 用于分割非数值字段的字符 - 包含逗号和分隔符的数据字段,通常用引号字符套嵌. 默认情况下,Export 将双引号字符作为分隔符. 用 "TextDelimiters" 指定不同字符.
- 默认情况下,并不导入双引号字符分隔的文本字段.
- Import 选项:
-
CharacterEncoding "UTF8ISOLatin1" 文件中使用的原始字符编码 "CurrencyTokens" {{"$", "  ", "
", " ", "
", " "}, {"c", "
"}, {"c", " ", "p", "F"}}
", "p", "F"}}当导入数值值时会跳过货币单位 "DateStringFormat" None 日期格式,按 DateString 规范给出 "FillRows" Automatic 是否填满行最大化列长 "HeaderLines" 0 在文件开头跳过的行数 "IgnoreEmptyLines" False 是否忽略空白行 "NumberPoint" "." 小数点字符串 "Numeric" Automatic 如果可以,是否将数据字段导入为数字 "SkipLines" 0 在文件开头跳过的行数 - 默认情况下,Import 试图将数据解释为 "UTF8" 编码文本. 如果文件中任何储存序列不能用 "UTF8" 表示,Import 将使用 "ISOLatin1" 代替.
- 用 CharacterEncoding -> Automatic, Import 尝试推断文件中的字符编码.
- "HeaderLines" 和 "SkipLines" 的可能设置为:
-
n 跳过的 n 行或作为 Dataset 开头使用 {rows,cols} 跳过的行和列或作为开头使用 - Import 将表格输入转换为由 "DateStringFormat" 指定格式的 DateObject.
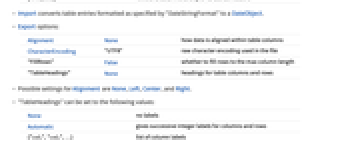
- Export 选项:
-
Alignment None 数据与表格列的对齐方式 CharacterEncoding "UTF8" 文件中使用的原始字符编码 "FillRows" False 是否填满行最大化列长 "TableHeadings" None 表格列和行的标头 - Alignment 可用设置为 None、Left、Center 和 Right.
- "TableHeadings" 可以设置为以下值:
-
None 没有标签 Automatic 对列和行给出连续的整数标签 {"col1","col2",…} 列标签列表 {rhead,chead} 指定行和列的单独标签 - Export 使用运行 Wolfram 语言的计算机系统的常用规范编码行分隔字符.
范例
打开所有单元关闭所有单元基本范例 (3)
范围 (4)
导入参数 (17)
导入选项 (10)
CharacterEncoding (1)
字符串编码可通过 $CharacterEncodings 设定为人任意值:
"CurrencyTokens" (1)
用 "CurrencyTokens"->None 包括所有货币符号:
"DateStringFormat" (1)
使用指定数据格式将数据转换为 DateObject:
"Numeric" (1)
用 "Numeric"->True 解释数字:
"SkipLines" (1)
导出选项 (7)
CharacterEncoding (1)
字符串编码可通过 $CharacterEncodings 设定为任意值:
"FillRows" (1)
使用 "FillRows"->False 来保持行的长度: