"Autoencoder" (Machine Learning Method)
- Method for DimensionReduction, DimensionReduce, FeatureSpacePlot and FeatureSpacePlot3D.
- Reduce the dimension of data using an autoencoder neural net.
Details & Suboptions
- "Autoencoder" is a neural net–based dimensionality reduction method. The method learns a low-dimensional representation of data by learning to approximate the identity function using a deep network that has an information bottleneck.
- "Autoencoder" works for high-dimensional data (e.g. images), a large number of examples and noisy training sets; however, it is slow to train and can fail when the training set is small.
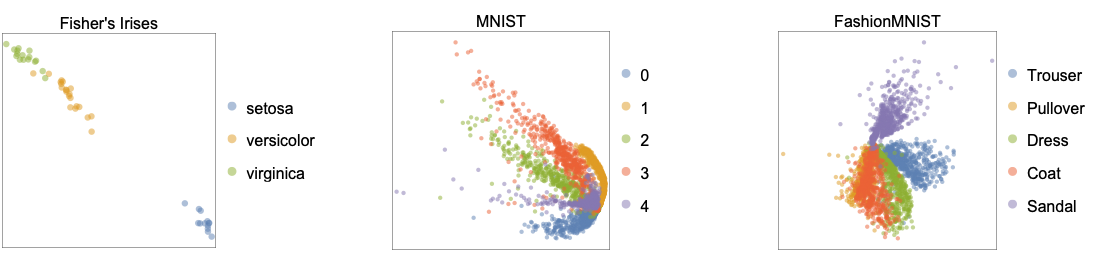
- The following feature-space plots (see FeatureSpacePlot) show two-dimensional embeddings learned by the "Autoencoder" method applied to the benchmarking datasets Fisher's Irises, MNIST and FashionMNIST:
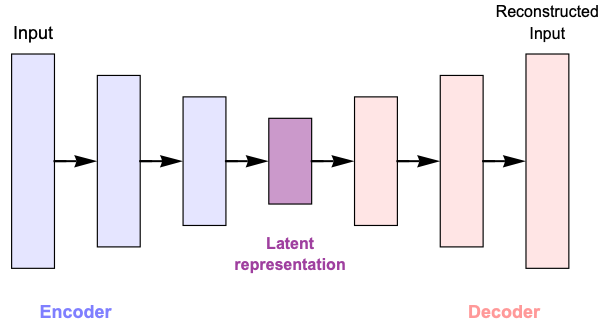
- The autoencoder network is made of an encoder net and a decoder net. The encoder net transforms the input data into a low-dimensional numeric representation (also called latent representation). The decoder attempts to reconstruct the original input from the latent representation:
- The encoder and decoder networks are trained together by minimizing the discrepancy between the original data and its reconstruction.
- The suboption "NetworkDepth" can be used to set the depth of encoder and decoder networks in order to control their capacity. Deeper networks allow the encoder to learn more complex patterns but will be more prone to overfitting. "NetworkDepth"1 is equivalent to performing "PrincipalComponentsAnalysis".
- The following suboptions can be given:
-
"NetworkDepth" Automatic depth of the encoder and decoder MaxTrainingRounds Automatic maximum number of rounds of training
Examples
open all close allBasic Examples (2)
Generate a dimension reducer from a high-dimensional random vector using the autoencoder method:
dr = DimensionReduction[RandomReal[{0, 3}, {1000, 10}], Method -> "Autoencoder"]Reduce new vectors using the trained autoencoder:
dr[RandomReal[{0, 3}, {2, 10}]]Reduce the dimension of some images using the autoencoder method:
fmnist = {[image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image]};
reduced = DimensionReduce[fmnist, 2, Method -> "Autoencoder"];Visualize the two-dimensional representation of images:
ListPlot[MapThread[Labeled[#1, #2]&, {reduced, fmnist}], ...]Scope (1)
Create training and test data consisting of two-dimensional numerical sequences of variable length:
SeedRandom[123];
m = 3000;
nvs = RandomSample[
Join[
RandomReal[-1, {m, 4, 2}],
RandomReal[1, {m, 2, 2}],
RandomReal[{2, 3}, {m, 3, 2}]
]
];
{nvs2tes, nvs2tra} = TakeDrop[nvs, Round[0.2 * m]];Train an autoencoder to find a dense three-dimensional representation of input sequences:
dr = DimensionReduction[nvs2tra, 3, Method -> "Autoencoder"]Visualize the similarity between different sequences of different lengths and bounds using the encoder:
f1 = ListPointPlot3D[Values[GroupBy[Thread[dr[nvs2tes] -> Length /@ nvs2tes], Last -> First]], ...];
f2 = ListPointPlot3D[dr[nvs2tes] -> MatrixForm /@ nvs2tes, ...];
Show[{f1, f2}]Generate new sequences from their encodings:
dr[dr[RandomSample[nvs2tes, 20]], "OriginalData"]Options (2)
MaxTrainingRounds (1)
NetworkDepth (1)
Obtain the MNIST dataset that contains training and test images:
SeedRandom[1234];
mtrain = Select[ResourceData["MNIST", "TrainingData"], (Last[#] < 5)&];
mtest = Select[RandomSample[ResourceData["MNIST", "TestData"], 2000], (Last[#] < 5)&];Train several autoencoders with different "NetworkDepth" to reduce the dimensions of the images:
drtab = Table[DimensionReduction[Keys@mtrain, Method -> {"Autoencoder", "NetworkDepth" -> n}], {n, 1, 4}];Visualize the two-dimensional representation of images for various network depths:
grouptest = KeySort@GroupBy[mtest, Last -> First];
GraphicsGrid[{Table[ListPlot[
Values[drtab[[i]] /@ grouptest],
...
],
{i, 4 }]}, ImageSize -> 500]Applications (2)
Data Reconstruction (1)
Load the Fashion MNIST training and test dataset:
ftrain = Keys@ResourceData["FashionMNIST", "TrainingData"];
ftest = Keys@ResourceData["FashionMNIST", "TestData"];Train an autoencoder to reduce the dimensions of the images:
dr = DimensionReduction[ftrain, FeatureExtractor -> "PixelVector", Method -> "Autoencoder" ]Use the reducer to reconstruct images from their encodings and compare with the original images:
SeedRandom[1234];
testimgs = RandomSample[ftest, 10];
GraphicsGrid[{testimgs,
dr[dr[testimgs], "OriginalData" ]}]Data Visulization (1)
Reduce the dimension of some images using the autoencoder method:
flowers = {[image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image], [image]};
reduced = DimensionReduce[flowers, 2, Method -> "Autoencoder"];Visualize the two-dimensional representation of images:
ListPlot[MapThread[Labeled[#1, #2]&, {reduced, flowers}]]