"DBSCAN" (机器学习方法)
"DBSCAN" (机器学习方法)
- 用于 FindClusters、ClusterClassify 和 ClusteringComponents 的方法.
- 使用基于密度的含噪应用空间聚类(DBSCAN)将数据划分为相似元素的聚类.
详细信息和子选项
- "DBSCAN"(基于密度的含噪应用空间聚类)是一种基于密度的聚类方法,其中使用基于邻居的方法来估计密度. "DBSCAN" 适应于任意形状和大小的簇,但要求簇具有相似的密度.
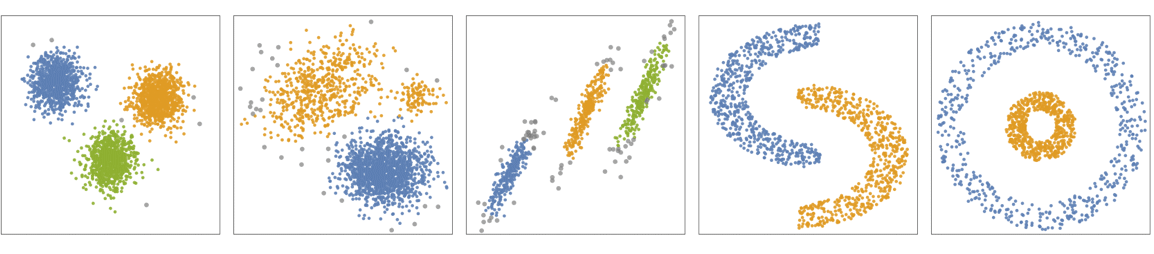
- 下图显示了应用于玩具数据集的 "DBSCAN" 方法的结果(黑点表示异常值):
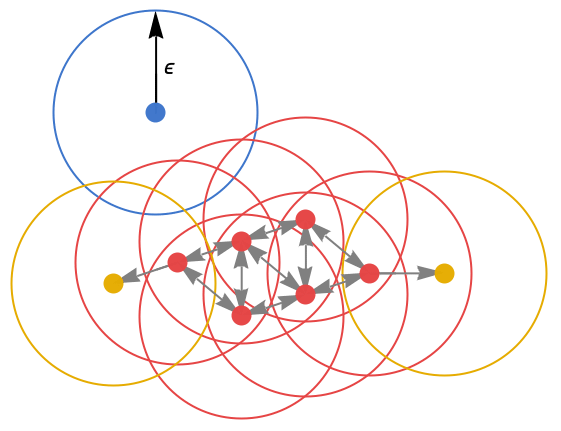
- "DBSCAN" 将“核心点”定义为在 ϵ 半径球内具有超过 k 个邻居的数据点(即高密度区域中的数据点). 然后,相互之间距离小于 ϵ 的核心点定义一个簇. 此外,任何与核心点距离小于 ϵ 的点都属于核心点的簇. 任何不靠近核心点的点都被认为是噪声.
- 这导致每个簇在其核心处包含一个或多个核心点,在其“边缘”处包含一些非核心点. 总的来说,"DBSCAN" 将簇定义为相连的高密度区域. 下图中,核心点为红色,边缘点为黄色,噪声点为蓝色:
- 在 ClusteringComponents 和 ClusterClassify 中,噪声点被标记为 Missing["Anomalous"].
- 在 FindClusters 中,噪声点作为一个簇返回.
- 选项 DistanceFunction 可用于定义要使用的距离.
- 可以给出以下子选项:
-
"NeighborhoodRadius" Automatic 半径 ϵ "NeighborsNumber" Automatic 邻居数量 k "DropAnomalousValues" False 是否丢弃异常值
范例
打开所有单元 关闭所有单元基本范例 (3)
使用 "DBSCAN" 方法在颜色列表上训练 ClassifierFunction:
范围 (2)
使用 "DBSCAN" 方法训练 ClassifierFunction:
使用 "DBSCAN" 方法训练 ClassifierFunction:
噪声点标记为 Missing["Anomalous"]:
选项 (7)
"NeighborhoodRadius" (2)
"NeighborsNumber" (3)
通过指定 "NeighborsNumber" 子选项查找簇:
通过改变 "NeighborsNumber" 使用 "DBSCAN" 方法绘制 data 的不同聚类:
Define a set of two-dimensional data points, characterized by four somewhat nebulous clusters:
Plot clusters in data using the "DBSCAN" method:
Plot different clusterings of data using the "DBSCAN" method by varying the "NeighborsNumber":
"DropAnomalousValues" (1)
训练 ClassifierFunction,将异常值标记为 Missing["Anomalous"]:
使用经过训练的 ClassifierFunction 来识别异常值:
通过删除异常值和寻找新的簇分配来训练 ClassifierFunction: