"KMeans" (机器学习方法)
"KMeans" (机器学习方法)
- FindClusters、ClusterClassify 和 ClusteringComponents 的方法.
- 使用
 均值聚类算法将数据划分为相似元素的指定的
均值聚类算法将数据划分为相似元素的指定的  个簇.
个簇.
详细信息和子选项
- "KMeans" 是一种经典、简单、基于质心的聚类方法. "KMeans" 适用于集群具有相似大小并且围绕其质心局部且各向同性分布的情况. 当聚类大小迥异、各向异性、相互交织或存在异常值时,"KMeans" 很可能会给出较差的结果.
- 以下各图显示了 "KMeans" 方法应用于玩具数据集的结果:
-

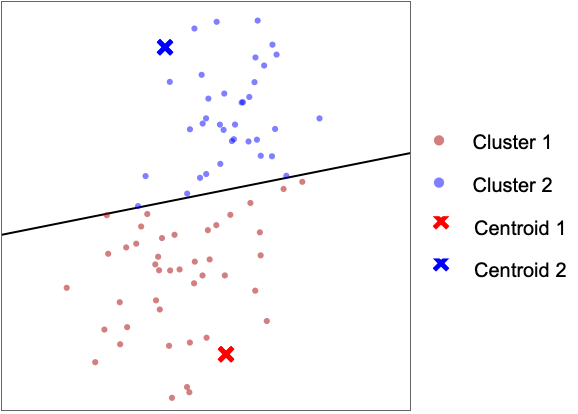
- "KMeans" 方法旨在找到定义 k 个簇的 k 个质心. 每个数据点都分配给距它最近的质心. 分配给给定质心的全体点形成一个簇.
- 寻找 k 个最佳质心的过程是迭代式的. 首先使用随机质心并将每个点分配给距它最近的质心:
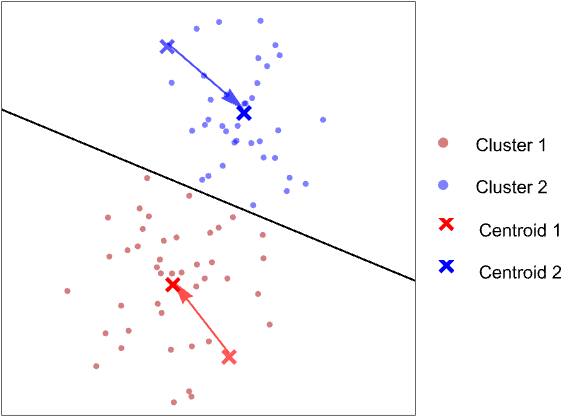
- 一旦所有簇均被定义,每个簇的平均值就变成了一个新的质心:
- 不断重复此过程,直到簇保持不变. 这个迭代过程有时被称为硬期望最大化(“hard EM”,即 hard Expectation Maximization).
- "KMeans" 方法类似于具有球形协方差的 "GaussianMixture"(即所有簇都是各向同性并且大小相同).
- 由于初始质心是随机选择的,因此每次运算的结果可能会有所不同.
- 子选项 "InitialCentroids" 可用于将初始质心指定为数据点列表.
- 可以给出以下子选项:
-
"InitialCentroids" Automatic 初始质心列表
范例
打开所有单元 关闭所有单元基本范例 (3)
FindClusters[{1, 2, 10, 12, 3, 1, 13, 25}, 4, Method -> "KMeans"]data = Join[RandomReal[1, {100, 2}], RandomReal[{-3, -.1}, {100, 2}], RandomReal[{-3, -0.1}, {100, 2}], RandomReal[{1, 3}, {100, 2}]];
ListPlot[data]ListPlot[FindClusters[data, 3, Method -> "KMeans"]]在一个字符串列表上训练 ClassifierFunction:
string = {"c", "a", "b", "xxx", "xxx2xx", "xxxxx", "uuuuu4u", "u5uuuuu"};
c = ClusterClassify[string, 3, Method -> "KMeans"]components = c[string]
GatherBy[string, c]选项 (3)
DistanceFunction (1)
"InitialCentroids" (2)
colors = RandomColor[100]使用 "KMeans" 方法在不指定质心初始配置的情况下对颜色进行聚类:
FindClusters[colors, 4, Method -> "KMeans"]FindClusters[colors, 3, Method -> {"KMeans", "InitialCentroids" -> {RGBColor[0.08509910562814116, 0.2392990464510818, 0.995197105413417], RGBColor[0.7194874746578643, 0.8141965369852671, 0.7566048068843456], RGBColor[0.904015286667484, 0.19694494526282913, 0.18860612169002278]} }]SeedRandom[123]
data = Join[RandomReal[1, {100, 2}], RandomReal[{-3, -.1}, {100, 2}], RandomReal[{-3, -0.1}, {100, 2}], RandomReal[{1, 3}, {100, 2}]];
ListPlot[data]Find different clusterings of data using the "KMeans" method by varying the "InitialCentroids":
{p1, p2, p3} = {{-1, -1}, {1, 0}, {2, 2}};
{q1, q2, q3} = RandomReal[-2, {3, 2}];
Grid[{Table[ListPlot[FindClusters[data, 3, Method -> {"KMeans", "InitialCentroids" -> s}]], {s, {{p1, p2, p3}, {q1, q2, q3}}}]}, Frame -> All]可能存在的问题 (1)
circle[r_, theta_] := {r Sin[theta], r Cos[theta]};
{train, test} = With[{
rot = RotationTransform[π, {0, 0}],
tra = TranslationTransform[{1, 2.5}], pts = circle@@@RandomVariate[UniformDistribution[{{2, 3}, {0, Pi}}], 2000]},
TakeDrop[RandomSample@Join[tra[rot[pts]], pts], 2000]
];
ListPlot[{train, test}, PlotRange -> All, AspectRatio -> 1, PlotStyle -> Directive[ PointSize[0.013], Opacity[0.7]], Frame -> True, Axes -> False]使用 "KMeans" 为两个聚类训练 ClassifierFunction 并在测试集中找到聚类:
ncls = 2;
cl = ClusterClassify[train, ncls, Method -> "KMeans"]
decision = cl[test];可视化聚类表明 "KMeans" 在相互交织的聚类上表现不佳:
fcl = ListPlot[Pick[test, decision, #]& /@ Range[ncls], PlotStyle -> Directive[PointSize[0.025], Opacity[0.7]], AspectRatio -> 1, Frame -> True, Axes -> False]