"SpanningTree" (机器学习方法)
- 用于 FindClusters、ClusterClassify 和 ClusteringComponents 的方法.
- 使用 "SpanningTree" 聚类算法将数据划分为相似元素的聚类.
Details & Suboptions
- "SpanningTree" 是一种基于邻域的聚类方法. "SpanningTree" 适用于任意形状和大小的聚类;但是,当聚类密度不同或连接松散时,它可能会失败.
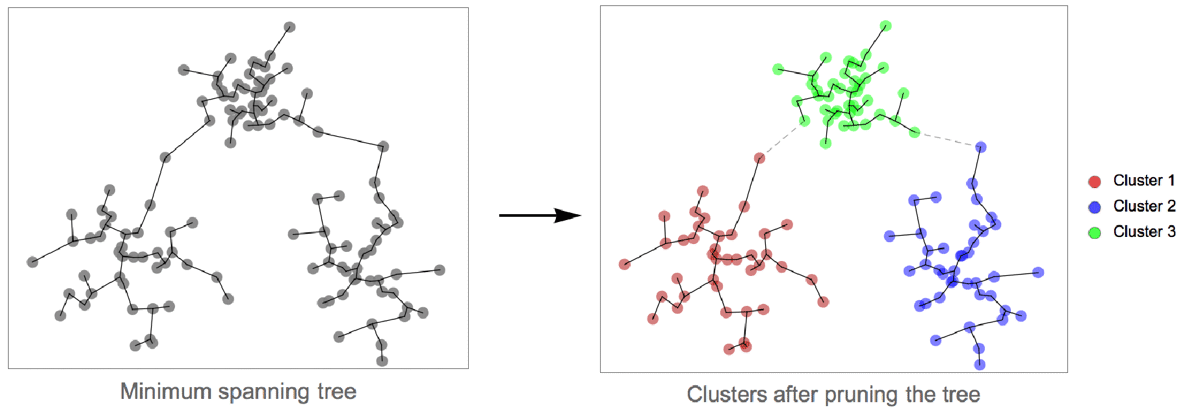
- 下图展示了将 "SpanningTree" 方法应用于玩具数据集的结果:
-

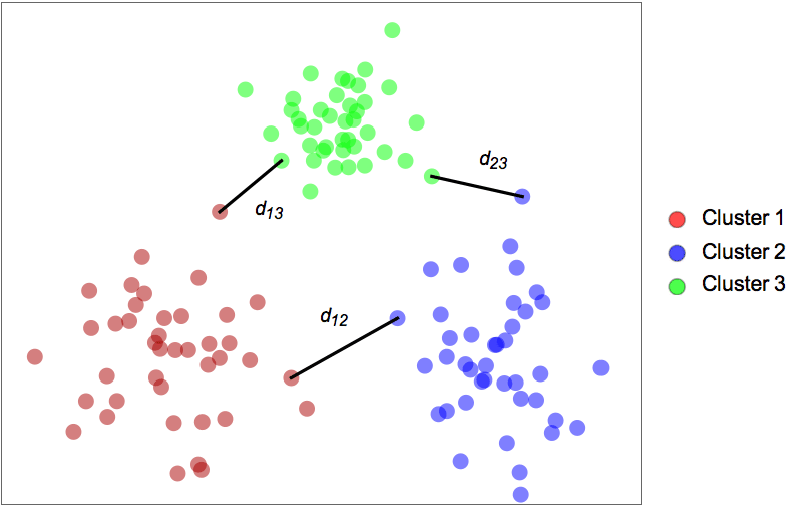
- 该算法找到相邻聚类之间距离最远的聚类集合. 两个相邻聚类 i 和 j 之间的距离 dij 定义为它们最近点之间的距离:
- 从形式上讲,"SpanningTree" 方法构造数据点的最小跨度树(使用距离作为图权重). 然后修剪树的最长边. 每个连通分量对应一个聚类. 当达到指定的聚类数时,修剪将停止. 如果未指定聚类数,则当所有边都短于给定阈值时,修剪将停止.
- 选项 DistanceFunction 可用于定义要使用的距离.
- 可以给出以下子选项:
-
"MaxEdgeLength" Automatic 修剪长度阈值
范例
打开所有单元关闭所有单元基本范例 (3)
使用 "SpanningTree" 方法训练 ClassifierFunction:
范围 (2)
使用 ClusteringComponents 查找聚类索引:
使用 "SpanningTree" 训练 ClassifierFunction 并找到测试集中的聚类: