Numerical Nonlinear Local Optimization
| Introduction | Examples of FindMinimum |
| The FindMinimum Function | Numerical Algorithms for Constrained Local Optimization |
Introduction
Numerical algorithms for constrained nonlinear optimization can be broadly categorized into gradient-based methods and direct search methods. Gradient search methods use first derivatives (gradients) or second derivatives (Hessians) information. Examples are the sequential quadratic programming (SQP) method, the augmented Lagrangian method, and the (nonlinear) interior point method. Direct search methods do not use derivative information. Examples are Nelder–Mead, genetic algorithm and differential evolution, and simulated annealing. Direct search methods tend to converge more slowly, but can be more tolerant to the presence of noise in the function and constraints.
Typically, algorithms only build up a local model of the problems. Furthermore, to ensure convergence of the iterative process, many such algorithms insist on a certain decrease of the objective function or of a merit function that is a combination of the objective and constraints. Such algorithms will, if convergent, only find the local optimum, and are called local optimization algorithms. In the Wolfram Language local optimization problems can be solved using FindMinimum.
Global optimization algorithms, on the other hand, attempt to find the global optimum, typically by allowing decrease as well as increase of the objective/merit function. Such algorithms are usually computationally more expensive. Global optimization problems can be solved exactly using Minimize or numerically using NMinimize.
Minimize[{x - y, -3 x^2 + 2 x y - y^2 ≥ -1}, {x, y}]NMinimize[{x - y, -3 x^2 + 2 x y - y^2 ≥ -1}, {x, y}]FindMinimum[{x - y, -3 x^2 + 2 x y - y^2 ≥ -1}, {x, y}]The FindMinimum Function
FindMinimum solves local unconstrained and constrained optimization problems. This document only covers the constrained optimization case. See "Unconstrained Optimization" for details of FindMinimum for unconstrained optimization.
FindMinimum[{-(100/(x - 1)^2 + (y - 1)^2 + 1) - (200/(x + 1)^2 + (y + 2)^2 + 1), x^2 + y^2 > 3 }, {x, y}]FindMinimum[{-(100/(x - 1)^2 + (y - 1)^2 + 1) - (200/(x + 1)^2 + (y + 2)^2 + 1), x^2 + y^2 > 3 }, {{x, 2}, y}]The previous solution point is actually a local minimum. FindMinimum only attempts to find a local minimum.
ContourPlot[-(100/(x - 1)^2 + (y - 1)^2 + 1) - (200/(x + 1)^2 + (y + 2)^2 + 1), {x, -3, 2}, {y, -3, 2}, RegionFunction -> (#1 ^ 2 + #2 ^ 2 > 3&), Contours -> 10, Epilog -> ({Red, PointSize[.02], Text["global minimum", {-.995, -2.092}], Point[{-.995, -1.992}], Text["local minimum", {0.5304, 1.2191}], Point[{1.2304, 1.2191}]}), ContourLabels -> True]Show[{Plot3D[-(100/(x - 1)^2 + (y - 1)^2 + 1) - (200/(x + 1)^2 + (y + 2)^2 + 1), {x, -4, 3}, {y, -4, 3}, RegionFunction -> (#1 ^ 2 + #2 ^ 2 > 3&), PlotRange -> All], Graphics3D[{Red, PointSize[.02], Text["Global minimum", {-.995, -2.092, -230}], Point[{-.995, -2.092, -207}], Text["Local minimum", {0.5304, 1.2191, -93.4}], Point[{1.23, 1.22, -103.}]}]}]Options for FindMinimum
FindMinimum accepts these options.
option name | default value | |
| AccuracyGoal | Automatic | the accuracy sought |
| Compiled | Automatic | whether the function and constraints should automatically be compiled |
| EvaluationMonitor | None | expression to evaluate whenever f is evaluated |
| Gradient | Automatic | the list of gradient functions {D[f,x],D[f,y],…} |
| MaxIterations | Automatic | maximum number of iterations to use |
| Method | Automatic | method to use |
| PrecisionGoal | Automatic | the precision sought |
| StepMonitor | None | expression to evaluate whenever a step is taken |
| WorkingPrecision | MachinePrecision | the precision used in internal computations |
Options of the FindMinimum function.
The Method option specifies the method to use to solve the optimization problem. Currently, the only method available for constrained optimization is the interior point algorithm.
FindMinimum[{x^2 + y^2, (x - 1)^2 + 2(y - 1)^2 > 5}, {x, y}, Method -> "InteriorPoint"]MaxIterations specifies the maximum number of iterations that should be used. When machine precision is used for constrained optimization, the default MaxIterations->500 is used.
When StepMonitor is specified, it is evaluated once every iterative step in the interior point algorithm. On the other hand, EvaluationMonitor, when specified, is evaluated every time a function or an equality or inequality constraint is evaluated.
pts = Reap[sol = FindMinimum[{-(100/(x - 1)^2 + (y - 1)^2 + 1) - (200/(x + 1)^2 + (y + 2)^2 + 1), x^2 + y^2 > 3 }, {{x, 1.5}, {y, -1}}, MaxIterations -> 10, StepMonitor :> (Sow[{x, y}])];]; solContourPlot[-(100/(x - 1)^2 + (y - 1)^2 + 1) - (200/(x + 1)^2 + (y + 2)^2 + 1), {x, -3, 3}, {y, -4, 2}, RegionFunction -> (#1 ^ 2 + #2 ^ 2 > 3&), Contours -> 10, Epilog -> ({Red, PointSize[.01], Line[pts[[2, 1]]], Yellow, Point /@ pts[[2, 1]], Blue, PointSize[.02], Point[pts[[2, 1, 1]]]}), ContourLabels -> True]WorkingPrecision->prec specifies that all the calculation in FindMinimum is to be carried out at precision prec. By default, prec=MachinePrecision. If prec>MachinePrecision, a fixed precision of prec is used through the computation.
AccuracyGoal and PrecisionGoal options are used in the following way. By default, AccuracyGoal->Automatic, and is set to prec/3. By default, PrecisionGoal->Automatic and is set to -Infinity. AccuracyGoal->ga is the same as AccuracyGoal->{-Infinity,ga}.
Suppose AccuracyGoal->{a,ga} and PrecisionGoal->p, then FindMinimum attempts to drive the residual, which is a combination of the feasibility and the satisfaction of the Karush–Kuhn–Tucker (KKT) and complementary conditions, to be less than or equal to tol=10-ga. In addition, it requires the difference between the current and next iterative point, x and x+, to satisfy ![]() , before terminating.
, before terminating.
sol = FindMinimum[{-(100 / ((x - 1) ^ 2 + (y - 1) ^ 2 + 1)) - 200 / ((x + 1) ^ 2 + (y + 2) ^ 2 + 1), x ^ 2 + y ^ 2 > 3}, {{x, 3 / 2}, {y, -1}}, WorkingPrecision -> 100, Method -> "InteriorPoint"]solExact = Minimize[{-(100/(x - 1)^2 + (y - 1)^2 + 1) - (200/(x + 1)^2 + (y + 2)^2 + 1), x^2 + y^2 > 3 }, {x, y}];sol[[1]] - solExact[[1]]Examples of FindMinimum
Finding a Global Minimum
If a global minimum is needed, NMinimize or Minimize should be used. However since each run of FindMinimum tends to be faster than NMinimize or Minimize, sometimes it may be more efficient to use FindMinimum, particularly for relatively large problems with a few local minima. FindMinimum attempts to find a local minimum, therefore it will terminate if a local minimum is found.
Plot[Sin[x] + .5 x, {x, -10, 10}]FindMinimum[{Sin[x] + .5 x, -10 <= x <= 10}, {x}]FindMinimum[{Sin[x] + .5 x, -10 <= x <= 10}, {{x, -5}}]FindMinimum[{Sin[x] + .5 x, -10 <= x <= 10 && x < -5}, {x}]SeedRandom[7919];
Table[FindMinimum[{Sin[x] + .5 x, -10 <= x <= 10}, {{x, RandomReal[{-10, 10}]}}], {10}]NMinimize[{Sin[x] + .5 x, -10 <= x <= 10}, {x}, Method -> {"RandomSearch", "PostProcess" -> "InteriorPoint"}]Solving Minimax Problems
The minimax (also known as minmax) problem is that of finding the minimum value of a function defined as the maximum of several functions, that is,
While this problem can often be solved using general constrained optimization technique, it is more reliably solved by reformulating the problem into one with smooth objective function. Specifically, the minimax problem can be converted into the following
and solved using either FindMinimum or NMinimize.
(*FindMinMax[{Max[{f1,f2,..}],constraints},vars]*)
SetAttributes[FindMinMax, HoldAll];
FindMinMax[{f_Max, cons_}, vars_, opts___ ? OptionQ] := With[{res = iFindMinMax[{f, cons}, vars, opts]}, res /; ListQ[res]];
iFindMinMax[{ff_Max, cons_}, vars_, opts___ ? OptionQ] := Module[{z, res, f = List @@ ff},
res = FindMinimum[{z, (And @@ cons) && (And @@ Thread[z >= f])}, Append[Flatten[{vars}, 1], z], opts]; If[ListQ[res], {z /. res[[2]], Thread[vars -> (vars /. res[[2]])]}]];FindMinMax[{Max[{x ^ 2, (x - 1) ^ 2}], {}}, {x, y}]FindMinMax[{Max[{Abs[2 x ^ 2 + y ^ 2 - 48 x - 40 y + 304], Abs[-x ^ 2 - 3 y ^ 2], Abs[x + 3 y - 18], Abs[-x - y], Abs[ x + y - 8]}], {}}, {x, y}]ContourPlot[Max[{Abs[2 x ^ 2 + y ^ 2 - 48 x - 40 y + 304], Abs[-x ^ 2 - 3 y ^ 2], Abs[x + 3 y - 18], Abs[-x - y], Abs[ x + y - 8]}], {x, 3, 7}, {y, 1, 3}, Contours -> 40, Epilog -> {Red, PointSize[0.02], Point[{4.93, 2.08}]}]FindMinMax[{Max[{Abs[2 x ^ 2 + y ^ 2 - 48 x - 40 y + 304], Abs[-x ^ 2 - 3 y ^ 2], Abs[x + 3 y - 18], Abs[-x - y], Abs[ x + y - 8]}], {(x - 6) ^ 2 + (y - 1) ^ 2 ≤ 1}}, {x, y}]ContourPlot[Max[{Abs[2 x ^ 2 + y ^ 2 - 48 x - 40 y + 304], Abs[-x ^ 2 - 3 y ^ 2], Abs[x + 3 y - 18], Abs[-x - y], Abs[ x + y - 8]}], {x, 3, 7}, {y, 0, 3}, RegionFunction -> (((#1 - 6) ^ 2 + (#2 - 1) ^ 2 <= 1)&), Contours -> 40, Epilog -> {Red, PointSize[0.02], Point[{5.34, 1.75}]}]Multiobjective Optimization: Goal Programming
Multiobjective programming involves minimizing several objective functions, subject to constraints. Since a solution that minimizes one function often does not minimize the others at the same time, there is usually no unique optimal solution.
Sometimes the decision maker has in mind a goal for each objective. In that case the so-called goal programming technique can be applied.
There are a number of variants of how to model a goal-programming problem. One variant is to order the objective functions based on priority, and seek to minimize the deviation of the most important objective function from its goal first, before attempting to minimize the deviations of the less important objective functions from their goals. This is called lexicographic or preemptive goal programming.
In the second variant, the weighted sum of the deviation is minimized. Specifically, the following constrained minimization problem is to be solved.
Here ![]() stands for the positive part of the real number
stands for the positive part of the real number ![]() . The weights
. The weights ![]() reflect the relative importance, and normalize the deviation to take into account the relative scales and units. Possible values for the weights are the inverse of the goals to be attained. The previous problem can be reformulated to one that is easier to solve.
reflect the relative importance, and normalize the deviation to take into account the relative scales and units. Possible values for the weights are the inverse of the goals to be attained. The previous problem can be reformulated to one that is easier to solve.
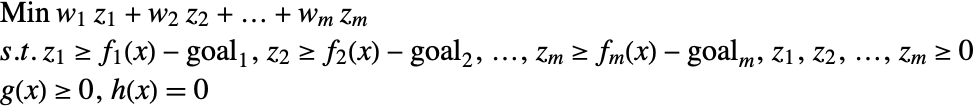
The third variant, Chebyshev goal programming, minimizes the maximum deviation, rather than the sum of the deviations. This balances the deviation of different objective functions. Specifically, the following constrained minimization problem is to be solved.
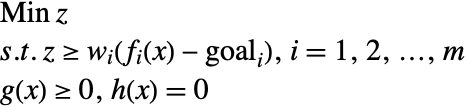
(* GoalProgrammingWeightedAverage[{{{f1,goal1,weight1},...},cons},vars]]*)
GoalProgrammingWeightedAverage[{fg : {{_, _}..}, cons_}, vars_, opts___ ? OptionQ] := With[
{res = Catch[iGoalProgrammingWeightedAverage[{Map[(Append@@#&), Thread[{fg, ConstantArray[1, {Length[fg]}]}]], cons}, vars]]},
res /; ListQ[res]
];
GoalProgrammingWeightedAverage[{fg : {{_, _, _}..}, cons_}, vars_, opts___ ? OptionQ] := With[
{res = Catch[iGoalProgrammingWeightedAverage[{fg, cons}, vars]]},
res /; ListQ[res]
];
iGoalProgrammingWeightedAverage[{fg : {{_, _, _}..}, cons_}, vars_, opts___ ? OptionQ] := Module[
{fs, goals, zs, z, res, ws},
{fs, goals, ws} = Transpose[fg];
If[!VectorQ[ws, (# >= 0&)], Throw[$Failed]];
If[!VectorQ[goals, ((NumericQ[#] && Head[#] =!= Complex)&)], Throw[$Failed]];
zs = Array[z, Length[fs]];
res = FindMinimum[{ws.zs, (And@@Flatten[{cons}, 1]) && (And@@Thread[zs ≥ 0]) && (And@@Thread[zs ≥ fs - goals ])}, Join[Flatten[{vars}, 1], zs], opts];
If[ListQ[res], {fs /. res[[2]], Thread[vars -> (vars /. res[[2]])]}]
];(* syntax GoalAttainment[{{{f1,goal1,weight1},...},cons},vars]]*)
GoalProgrammingChebyshev[{fg : {{_, _}..}, cons_}, vars_, opts___ ? OptionQ] := With[
{res = Catch[iGoalProgrammingChebyshev[{Map[(Append@@#&), Thread[{fg, ConstantArray[1, {Length[fg]}]}]], cons}, vars]]},
res /; ListQ[res]
];
GoalProgrammingChebyshev[{fg : {{_, _, _}..}, cons_}, vars_, opts___ ? OptionQ] := With[
{res = Catch[iGoalProgrammingChebyshev[{fg, cons}, vars]]},
res /; ListQ[res]
];
iGoalProgrammingChebyshev[{fg : {{_, _, _}..}, cons_}, vars_, opts___ ? OptionQ] := Module[
{fs, goals, y, res, ws},
{fs, goals, ws} = Transpose[fg];
If[!VectorQ[ws, (# >= 0&)], Throw[$Failed]];
If[!VectorQ[goals, ((NumericQ[#] && Head[#] =!= Complex)&)], Throw[$Failed]];
res = FindMinimum[{y, (And@@Flatten[{cons}, 1]) && (And@@Thread[y ≥ ws * (fs - goals) ])}, Append[Flatten[{vars}, 1], y], opts];
If[ListQ[res], {fs /. res[[2]], Thread[vars -> (vars /. res[[2]])]}]
];res1 = GoalProgrammingWeightedAverage[{{{x ^ 2 + y ^ 2, 0}, {4(x - 2) ^ 2 + 4(y - 2) ^ 2, 0}}, y - x == -4}, {x, y}]res2 = GoalProgrammingChebyshev[{{{x ^ 2 + y ^ 2, 0}, {4(x - 2) ^ 2 + 4(y - 2) ^ 2, 0}}, y - x == -4}, {x, y}]g1 = ContourPlot[x ^ 2 + y ^ 2, {x, 2, 6}, {y, -1, 2}, ContourShading -> False, ContourStyle -> Blue, ContourLabels -> Automatic];
g2 = ContourPlot[4(x - 2) ^ 2 + 4(y - 2) ^ 2, {x, 2, 6}, {y, -1, 2}, ContourShading -> False, ContourStyle -> Red, ContourLabels -> Automatic];
Show[{g1, g2}, Epilog -> {Line[{{3, -1}, {6, 2}}], PointSize[0.02], Yellow, Point[{x, y} /. res1[[2]]], Green, Point[{x, y} /. res2[[2]]]}]An Application Example: Portfolio Optimization
A powerful tool in managing investments is to spread the risk by investing in assets that have few or no correlations. For example, if asset A goes up 20% one year and is down 10% the next, asset B goes down 10% one year and is up 20% the next, and up years for A are down years for B, then holding both in equal amounts would result in a 10% increase every year, without any risk. In reality such assets are rarely available, but the concept remains a useful one.
In this example, the aim is to find the optimal asset allocation so as to minimize the risk, and achieve a preset level of return by investing in a spread of stocks, bonds, and gold.
Here are the historical returns of various assets between 1973 and 1994. For example, in 1973, S&P 500 lost 1-0.852=14.8%, while gold appreciated by 67.7%.
| "3m Tbill" | "long Tbond" | "SP500" | "Wilt.5000" | "Corp. Bond" | "NASDQ" | "EAFE" | "Gold" | |
| 1973 | 1.075` | 0.942` | 0.852` | 0.815` | 0.698` | 1.023` | 0.851` | 1.677` |
| 1974 | 1.084` | 1.02` | 0.735` | 0.716` | 0.662` | 1.002` | 0.768` | 1.722` |
| 1975 | 1.061` | 1.056` | 1.371` | 1.385` | 1.318` | 0.123` | 1.354` | 0.76` |
| 1976 | 1.052` | 1.175` | 1.236` | 1.266` | 1.28` | 1.156` | 1.025` | 0.96` |
| 1977 | 1.055` | 1.002` | 0.926` | 0.974` | 1.093` | 1.03` | 1.181` | 1.2` |
| 1978 | 1.077` | 0.982` | 1.064` | 1.093` | 1.146` | 1.012` | 1.326` | 1.295` |
| 1979 | 1.109` | 0.978` | 1.184` | 1.256` | 1.307` | 1.023` | 1.048` | 2.212` |
| 1980 | 1.127` | 0.947` | 1.323` | 1.337` | 1.367` | 1.031` | 1.226` | 1.296` |
| 1981 | 1.156` | 1.003` | 0.949` | 0.963` | 0.99` | 1.073` | 0.977` | 0.688` |
| 1982 | 1.117` | 1.465` | 1.215` | 1.187` | 1.213` | 1.311` | 0.981` | 1.084` |
| 1983 | 1.092` | 0.985` | 1.224` | 1.235` | 1.217` | 1.08` | 1.237` | 0.872` |
| 1984 | 1.103` | 1.159` | 1.061` | 1.03` | 0.903` | 1.15` | 1.074` | 0.825` |
| 1985 | 1.08` | 1.366` | 1.316` | 1.326` | 1.333` | 1.213` | 1.562` | 1.006` |
| 1986 | 1.063` | 1.309` | 1.186` | 1.161` | 1.086` | 1.156` | 1.694` | 1.216` |
| 1987 | 1.061` | 0.925` | 1.052` | 1.023` | 0.959` | 1.023` | 1.246` | 1.244` |
| 1988 | 1.071` | 1.086` | 1.165` | 1.179` | 1.165` | 1.076` | 1.283` | 0.861` |
| 1989 | 1.087` | 1.212` | 1.316` | 1.292` | 1.204` | 1.142` | 1.105` | 0.977` |
| 1990 | 1.08` | 1.054` | 0.968` | 0.938` | 0.83` | 1.083` | 0.766` | 0.922` |
| 1991 | 1.057` | 1.193` | 1.304` | 1.342` | 1.594` | 1.161` | 1.121` | 0.958` |
| 1992 | 1.036` | 1.079` | 1.076` | 1.09` | 1.174` | 1.076` | 0.878` | 0.926` |
| 1993 | 1.031` | 1.217` | 1.1` | 1.113` | 1.162` | 1.11` | 1.326` | 1.146` |
| 1994 | 1.045` | 0.889` | 1.012` | 0.999` | 0.968` | 0.965` | 1.078` | 0.99` |
| average | 1.078 | 1.093 | 1.120 | 1.124 | 1.121 | 1.046 | 1.141 | 1.130 |
R = {{1.075, 1.084, 1.061, 1.052, 1.055, 1.077, 1.109, 1.127, 1.156, 1.117, 1.092, 1.103, 1.08, 1.063, 1.061, 1.071, 1.087, 1.08, 1.057, 1.036, 1.031, 1.045}, {0.942, 1.02, 1.056, 1.175, 1.002, 0.982, 0.978, 0.947, 1.003, 1.465, 0.985, 1.159, 1.366, 1.309, 0.925, 1.086, 1.212, 1.054, 1.193, 1.079, 1.217, 0.889}, {0.852, 0.735, 1.371, 1.236, 0.926, 1.064, 1.184, 1.323, 0.949, 1.215, 1.224, 1.061, 1.316, 1.186, 1.052, 1.165, 1.316, 0.968, 1.304, 1.076, 1.1, 1.012}, {0.815, 0.716, 1.385, 1.266, 0.974, 1.093, 1.256, 1.337, 0.963, 1.187, 1.235, 1.03, 1.326, 1.161, 1.023, 1.179, 1.292, 0.938, 1.342, 1.09, 1.113, 0.999}, {0.698, 0.662, 1.318, 1.28, 1.093, 1.146, 1.307, 1.367, 0.99, 1.213, 1.217, 0.903, 1.333, 1.086, 0.959, 1.165, 1.204, 0.83, 1.594, 1.174, 1.162, 0.968}, {1.023, 1.002, 0.123, 1.156, 1.03, 1.012, 1.023, 1.031, 1.073, 1.311, 1.08, 1.15, 1.213, 1.156, 1.023, 1.076, 1.142, 1.083, 1.161, 1.076, 1.11, 0.965}, {0.851, 0.768, 1.354, 1.025, 1.181, 1.326, 1.048, 1.226, 0.977, 0.981, 1.237, 1.074, 1.562, 1.694, 1.246, 1.283, 1.105, 0.766, 1.121, 0.878, 1.326, 1.078}, {1.677, 1.722, 0.76, 0.96, 1.2, 1.295, 2.212, 1.296, 0.688, 1.084, 0.872, 0.825, 1.006, 1.216, 1.244, 0.861, 0.977, 0.922, 0.958, 0.926, 1.146, 0.99}};{n, nyear} = Dimensions[R];ER = Mean[Transpose@R]Covariants = Covariance[Transpose[R]];vars = Map[Subscript[x, #]&, {"3m T-bill", "long T-bond", "SP500", "Wiltshire 5000", "Corporate Bond", "NASDQ", "EAFE", "Gold"}];
vars = Map[Subscript[x, #]&, {"3m T-bill", "long T-bond", "SP500", "Wiltshire 5000", "Corporate Bond", "NASDQ", "EAFE", "Gold"}];
FindMinimum[{
vars.Covariants.vars, Total[vars] == 1 && vars.ER ≥ 1.12 && Apply[And, Thread[Greater[vars, 0]]]}, vars]vars = Map[Subscript[x, #]&, {"3m T-bill", "long T-bond", "SP500", "Wiltshire 5000", "Corporate Bond", "NASDQ", "EAFE", "Gold"}];
FindMinimum[{
vars.Covariants.vars, Total[vars] == 1 && vars.ER ≥ 1.10 && Apply[And, Thread[Greater[vars, 0]]]}, vars]Limitations of the Interior Point Method
The implementation of the interior point method in FindMinimum requires first and second derivatives of the objective and constraints. Symbolic derivatives are first attempted, and if they fail, finite difference will be used to calculate the derivatives. If the function or constraints are not smooth, particularly if the first derivative at the optimal point is not continuous, the interior point method may experience difficulty in converging.
FindMinimum[{Abs[x ^ 2 - 3], 0 ≤ x ≤ 5}, {x}, Method -> "InteriorPoint"]FindMinimum[{Abs[x ^ 2 - 3]}, {x}, Method -> "Newton"]Numerical Algorithms for Constrained Local Optimization
The Interior Point Algorithm
The interior point algorithm solves a constrained optimization by combining constraints and the objective function through the use of the barrier function. Specifically, the general constrained optimization problem is first converted to the standard form
and ![]() . The non-negative constraints are then replaced by adding a barrier term to the objective function
. The non-negative constraints are then replaced by adding a barrier term to the objective function
The necessary KKT condition (assuming, for example, that the gradient of ![]() is linearly independent) is
is linearly independent) is
where ![]() is of dimension
is of dimension ![]() ×
×![]() and
and ![]() is a dual variable. The preceding can be written as:
is a dual variable. The preceding can be written as:
where ![]() is a diagonal matrix, with the diagonal element
is a diagonal matrix, with the diagonal element ![]() of
of ![]() if
if ![]() , or
, or ![]() and
and ![]() is a vector of 1s and
is a vector of 1s and ![]() . Introducing variable
. Introducing variable ![]() , the preceding system can be rewritten as:
, the preceding system can be rewritten as:
and ![]() is a diagonal matrix with diagonal elements
is a diagonal matrix with diagonal elements ![]() . This nonlinear system can be solved with Newton's method. Let
. This nonlinear system can be solved with Newton's method. Let ![]() and
and ![]() ; the Jacobi matrix of system (1) is
; the Jacobi matrix of system (1) is
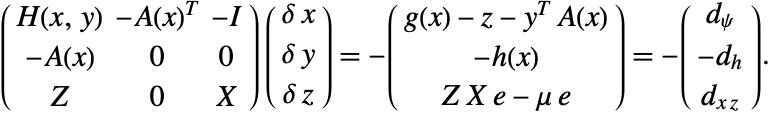
Thus the nonlinear constrained problem can be solved iteratively by
with the search direction ![]() given by solving the previous Jacobi system (2).
given by solving the previous Jacobi system (2).
To ensure convergence, you need to have some measure of success. One way of doing this is to use a merit function, such as the following augmented Lagrangian merit function.
Augmented Lagrangian Merit Function
This defines an augmented Lagrangian merit function
Here ![]() is the barrier parameter and
is the barrier parameter and ![]() a penalty parameter. It can be proved that if the matrix
a penalty parameter. It can be proved that if the matrix ![]() is positive definite, then either the search direction given by (3) is a descent direction for the above merit function (4), or
is positive definite, then either the search direction given by (3) is a descent direction for the above merit function (4), or ![]() satisfied the KKT condition (5). A line search is performed along the search direction, with the initial step length chosen to be as close to 1 as possible, while maintaining the positive constraints. A backtracking procedure is then used until the Armijo condition is satisfied on the merit function,
satisfied the KKT condition (5). A line search is performed along the search direction, with the initial step length chosen to be as close to 1 as possible, while maintaining the positive constraints. A backtracking procedure is then used until the Armijo condition is satisfied on the merit function, ![]() with
with ![]() .
.
Convergence Tolerance
The convergence criterion for the interior point algorithm is
with tol set, by default, to 10-MachinePrecision/3.