

AndersonDarlingTest
AndersonDarlingTest[data]
Anderson–Darling検定を使い,data が正規分布に従っているかどうかを調べる.
AndersonDarlingTest[data,dist]
Anderson–Darling検定を使い,data が dist に従った分布かどうかを調べる.
AndersonDarlingTest[data,dist,"property"]
"property"の値を返す.
詳細とオプション


- AndersonDarlingTestは,data が分布 dist の母集団から取り出されたという帰無仮説
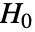 と,そうではないという対立仮説
と,そうではないという対立仮説 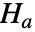 でAnderson–Darlingの適合度検定を行う.
でAnderson–Darlingの適合度検定を行う. - デフォルトで,確率値つまり
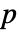 値が返される.
値が返される. - 小さい
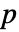 値は data が dist から来ている可能性が低いことを示す.
値は data が dist から来ている可能性が低いことを示す. - dist は,記号および数値の母数,またはデータ集合,を持つ任意の記号分布でよい.
- data は一変量{x1,x2,…}でも多変量{{x1,y1,…},{x2,y2,…},…}でもよい.
- Anderson–Darling検定はデータが連続分布のものであると仮定する.
- Anderson–Darling検定は事実上
![Expectation[((F^^(x)-F(x))^2)/(F(x) (1-F(x))),...]](Files/AndersonDarlingTest.ja/5.png "Expectation[((F^^(x)-F(x))^2)/(F(x) (1-F(x))),...]") に基づく検定統計を使う.ただし,
に基づく検定統計を使う.ただし,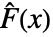 は data の経験的CDFであり
は data の経験的CDFであり 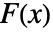 は dist のCDFである.
は dist のCDFである. - 一変量データについては,検定統計は
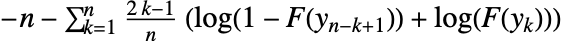 で与えられる.ただし,
で与えられる.ただし, はソートされたデータである.
はソートされたデータである. - 多変量検定については,一変量限界
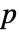 値の総和が使われる.総和は
値の総和が使われる.総和は 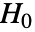 のもとでUniformSumDistributionに従うと想定される.
のもとでUniformSumDistributionに従うと想定される. - AndersonDarlingTest[data,dist,"HypothesisTestData"]はHypothesisTestDataオブジェクト htd を返す.これは htd["property"]として追加的な検定結果と特性の抽出に使うことができる.
- AndersonDarlingTest[data,dist,"property"]を使って直接"property"を与えることができる.
- 検定結果のレポートに関連する特性
-
"PValue" 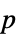 値
値"PValueTable" "PValue"のフォーマットされたバージョン "ShortTestConclusion" 検定結果の簡単な説明 "TestConclusion" 検定結果の説明 "TestData" 検定統計と 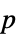 値
値"TestDataTable" "TestData"のフォーマットされたバージョン "TestStatistic" 検定統計 "TestStatisticTable" "TestStatistic"のフォーマットされたバージョン - 次の特性はどの検定が行われているかに依存しない.
- データ分布に関連する特性
-
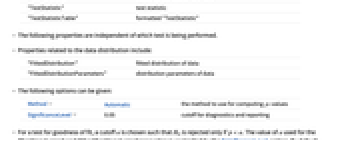
"FittedDistribution" データのフィットした分布 "FittedDistributionParameters" データの分布母数 - 使用可能なオプション
-
Method Automatic 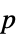 値を計算するメソッド
値を計算するメソッドSignificanceLevel 0.05 診断とレポートのための切捨て - 適合度検定では,
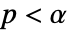 のときにのみ
のときにのみ 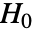 が棄却されるような切捨て
が棄却されるような切捨て 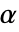 が選択される.特性"TestConclusion"および"ShortTestConclusion"で使われる
が選択される.特性"TestConclusion"および"ShortTestConclusion"で使われる 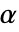 の値はSignificanceLevelオプションで制御される.デフォルトで,
の値はSignificanceLevelオプションで制御される.デフォルトで,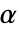 は0.05に設定されている.
は0.05に設定されている. - Method->"MonteCarlo"の設定では,入力
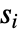 と同じ長さの
と同じ長さの 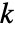 個のデータ集合が
個のデータ集合が 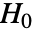 のもとにフィットされた分布を使って生成される.次に,AndersonDarlingTest[si,dist,"TestStatistic"]からのEmpiricalDistributionを使って
のもとにフィットされた分布を使って生成される.次に,AndersonDarlingTest[si,dist,"TestStatistic"]からのEmpiricalDistributionを使って 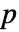 値が推定される.
値が推定される.
例題
すべて開く すべて閉じるスコープ (9)
検定 (6)
繰り返し特性を抽出するためにHypothesisTestDataオブジェクトを作成する:
オプション (4)
アプリケーション (4)
GammaDistribution[1,1/λ]がExponentialDistribution[λ]に等しいことを示すことができる.この結論はシミュレーションでサポートされる:
Anderson–Darling検定を行い,それぞれのデータ集合をその予測される ![]() の値でグループ分けする:
の値でグループ分けする:
基礎となる分布がUniformDistribution[{-4,4}]であり,検定サイズが0.05,サンプルサイズが6である場合に,Anderson–Darling検定の検出力を推定する:
3種のアヤメのそれぞれからの50のメンバーに対していくつかの測定を行う.setosa 種は簡単に見分けることができるが,残り2つの種である versicolor と virginica は混同されることが多いことが分かっている:
versicolor と virginica については同じ分布で,setosa は全く異なる:
以下のような花びらの長さの測定値が母集団について知られていると仮定する:
正規混合分布が花びらの長さの分布によくフィットしているようである:
特性と関係 (9)
デフォルトで一変量データはNormalDistributionと比べられる:
多変量データは,デフォルトでMultinormalDistributionと比べられる:
検定分布の母数は,指定されない場合にはデータから推測される:
母数が未知の場合,AndersonDarlingTestは可能であれば修正を適用する:
Anderson–Darling検定はNExpectationを使って定義することができる:
Anderson–Darling検定は,入力がTimeSeriesのときにのみ値に働く:
考えられる問題 (2)
Anderson–Darling検定は離散分布には使えない:
そのような場合にはモンテカルロ法またはPearsonChiSquareTestを使う:
母数がデータから推定される場合には,Anderson–Darling検定は,分布によっては有効ではないことがある:
テキスト
Wolfram Research (2010), AndersonDarlingTest, Wolfram言語関数, https://reference.wolfram.com/language/ref/AndersonDarlingTest.html.
CMS
Wolfram Language. 2010. "AndersonDarlingTest." Wolfram Language & System Documentation Center. Wolfram Research. https://reference.wolfram.com/language/ref/AndersonDarlingTest.html.
APA
Wolfram Language. (2010). AndersonDarlingTest. Wolfram Language & System Documentation Center. Retrieved from https://reference.wolfram.com/language/ref/AndersonDarlingTest.html