

KuiperTest
KuiperTest[data]
tests whether data is normally distributed using the Kuiper test.
KuiperTest[data,dist]
tests whether data is distributed according to dist using the Kuiper test.
KuiperTest[data,dist,"property"]
returns the value of "property".
Details and Options
- KuiperTest performs the Kuiper goodness-of-fit test with null hypothesis
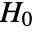 that data was drawn from a population with distribution dist and alternative hypothesis
that data was drawn from a population with distribution dist and alternative hypothesis 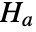 that it was not.
that it was not. - By default a probability value or
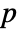 -value is returned.
-value is returned. - A small
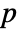 -value suggests that it is unlikely that the data came from dist.
-value suggests that it is unlikely that the data came from dist. - The dist can be any symbolic distribution with numeric and symbolic parameters or a dataset.
- The data can be univariate {x1,x2,…} or multivariate {{x1,y1,…},{x2,y2,…},…}.
- The Kuiper test assumes that the data came from a continuous distribution.
- The Kuiper test effectively uses a test statistic based on
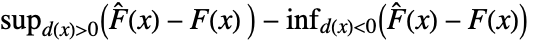 where
where 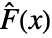 is the empirical CDF of data and
is the empirical CDF of data and 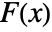 is the CDF of dist.
is the CDF of dist. - For multivariate tests, the sum of the univariate marginal
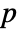 -values is used and is assumed to follow a UniformSumDistribution under
-values is used and is assumed to follow a UniformSumDistribution under 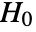 .
. - KuiperTest[data,dist,"HypothesisTestData"] returns a HypothesisTestData object htd that can be used to extract additional test results and properties using the form htd["property"].
- KuiperTest[data,dist,"property"] can be used to directly give the value of "property".
- Properties related to the reporting of test results include:
-
"PValue" 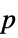 -value
-value"PValueTable" formatted version of "PValue" "ShortTestConclusion" a short description of the conclusion of a test "TestConclusion" a description of the conclusion of a test "TestData" test statistic and 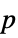 -value
-value"TestDataTable" formatted version of "TestData" "TestStatistic" test statistic "TestStatisticTable" formatted "TestStatistic" - The following properties are independent of which test is being performed.
- Properties related to the data distribution include:
-
"FittedDistribution" fitted distribution of data "FittedDistributionParameters" distribution parameters of data - The following options can be given:
-
Method Automatic the method to use for computing 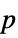 -values
-valuesSignificanceLevel 0.05 cutoff for diagnostics and reporting - For a test for goodness-of-fit, a cutoff
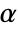 is chosen such that
is chosen such that 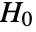 is rejected only if
is rejected only if 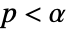 . The value of
. The value of 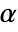 used for the "TestConclusion" and "ShortTestConclusion" properties is controlled by the SignificanceLevel option. By default
used for the "TestConclusion" and "ShortTestConclusion" properties is controlled by the SignificanceLevel option. By default 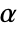 is set to 0.05.
is set to 0.05. - With the setting Method->"MonteCarlo",
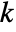 datasets of the same length as the input
datasets of the same length as the input 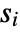 are generated under
are generated under 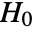 using the fitted distribution. The EmpiricalDistribution from KuiperTest[si,dist,"TestStatistic"] is then used to estimate the
using the fitted distribution. The EmpiricalDistribution from KuiperTest[si,dist,"TestStatistic"] is then used to estimate the 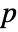 -value.
-value.
Examples
open all close allBasic Examples (4)
Perform a Kuiper test for normality:
data = RandomVariate[NormalDistribution[], 10^4];KuiperTest[data]Test the fit of some data to a particular distribution:
data = RandomVariate[LaplaceDistribution[1, 2], 10^3];KuiperTest[data, LaplaceDistribution[1, 2]]Compare the distributions of two datasets:
data1 = RandomVariate[NormalDistribution[], 100];data2 = RandomVariate[NormalDistribution[], 150];KuiperTest[data1, data2]Extract the test statistic from a Kuiper test:
data = RandomVariate[NormalDistribution[], 10^3];KuiperTest[data, NormalDistribution[], "TestStatistic"]Scope (9)
Testing (6)
Perform a Kuiper test for normality:
data1 = RandomVariate[NormalDistribution[], 10^4];
data2 = RandomVariate[StudentTDistribution[3], 10^4];The ![]() -value for the normal data is large compared to the
-value for the normal data is large compared to the ![]() -value for the non-normal data:
-value for the non-normal data:
KuiperTest[data1]KuiperTest[data2]Test the goodness-of-fit to a particular distribution:
data1 = RandomVariate[NormalDistribution[], 10^3];
data2 = RandomVariate[CauchyDistribution[0, 1], 10^3];KuiperTest[data1, CauchyDistribution[0, 1]]KuiperTest[data2, CauchyDistribution[0, 1]]Compare the distributions of two datasets:
data1 = RandomVariate[NormalDistribution[], 10^3];
data2 = RandomVariate[NormalDistribution[], 10^3];KuiperTest[data1, data2]The two datasets do not have the same distribution:
data3 = RandomVariate[NormalDistribution[0, 1.25], 10^3];KuiperTest[data1, data3]Test for multivariate normality:
data1 = RandomVariate[BinormalDistribution[.5], 10^3];
data2 = RandomVariate[LaplaceDistribution[1, 2], {10^3, 2}];KuiperTest[data1]KuiperTest[data2]Test for goodness-of-fit to any multivariate distribution:
data1 = RandomVariate[BinormalDistribution[.5], 10^3];
data2 = RandomVariate[𝒹 = LaplaceDistribution[1, 2], {10^3, 2}];𝒟 = ProductDistribution[𝒹, 𝒹];KuiperTest[data1, 𝒟]KuiperTest[data2, 𝒟]Create a HypothesisTestData object for repeated property extraction:
data = RandomVariate[NormalDistribution[], 10^5];ℋ = KuiperTest[data, Automatic, "HypothesisTestData"]The properties available for extraction:
ℋ["Properties"]Reporting (3)
Tabulate the results of the Kuiper test:
data = RandomVariate[NormalDistribution[], 100];ℋ = KuiperTest[data, Automatic, "HypothesisTestData"];ℋ["TestDataTable"]ℋ["PValueTable"]ℋ["TestStatisticTable"]Retrieve the entries from a Kuiper test table for custom reporting:
data1 = RandomVariate[NormalDistribution[], 100];
data2 = RandomVariate[NormalDistribution[], 100];ℋ1 = KuiperTest[data1, Automatic, "TestData"]ℋ2 = KuiperTest[data2, Automatic, "TestData"]BarChart[{Labeled[ℋ1, "Set 1"], Labeled[ℋ2, "Set 2"]}, ChartLabels -> {"SubscriptBox[D, n]", "p‐value"}]Report test conclusions using "ShortTestConclusion" and "TestConclusion":
data = BlockRandom[SeedRandom[1];RandomVariate[ParetoDistribution[1.05, 2], 100]];ℋ = KuiperTest[data, ParetoDistribution[1, 2], "HypothesisTestData"];ℋ["ShortTestConclusion"]ℋ["TestConclusion"]//TraditionalFormThe conclusion may differ at a different significance level:
ℋ = KuiperTest[data, ParetoDistribution[1, 2], "HypothesisTestData", SignificanceLevel -> .001];ℋ["ShortTestConclusion"]ℋ["TestConclusion"]//TraditionalFormOptions (3)
Method (3)
Use Monte Carlo-based methods for a computation formula:
data = RandomVariate[NormalDistribution[], 100];KuiperTest[data, NormalDistribution[], Method -> "MonteCarlo"]KuiperTest[data, NormalDistribution[], Method -> Automatic]Set the number of samples to use for Monte Carlo-based methods:
data = RandomVariate[NormalDistribution[], 100];pts = Table[{i, KuiperTest[data, NormalDistribution[], Method -> {"MonteCarlo", "MonteCarloSamples" -> i}]}, {i, Range[5, 250, 15]}];The Monte Carlo estimate converges to the true ![]() -value with increasing samples:
-value with increasing samples:
pval = KuiperTest[data, NormalDistribution[]];Show[ListLinePlot[pts, PlotRange -> {0, 1}, FrameLabel -> {"Samples", "P-Value"}, Frame -> True, AxesOrigin -> {0, 0}], Graphics[{Dashed, Line[{{0, pval}, {250, pval}}]}]]Set the random seed used in Monte Carlo-based methods:
data = RandomVariate[NormalDistribution[], 100];pts = Table[{i, KuiperTest[data, NormalDistribution[], Method -> {"MonteCarlo", "RandomSeed" -> i, "MonteCarloSamples" -> 50}]}, {i, Range[1, 10]}];The seed affects the state of the generator and has some effect on the resulting ![]() -value:
-value:
pval = KuiperTest[data, NormalDistribution[]];Show[ListLinePlot[pts, PlotRange -> {Min[pts[[All, 2]]], Max[pts[[All, 2]]]}, FrameLabel -> {"Seed", "P-Value"}, Frame -> True, AxesOrigin -> {0, 0}], Graphics[{Dashed, Line[{{0, pval}, {100, pval}}]}]]Applications (2)
A power curve for the Kuiper test:
data = Table[RandomVariate[UniformDistribution[{-4, 4}], {500, i}], {i, n = {5, 7, 10, 15, 20, 25, 30}}];ℋ = Table[KuiperTest[data[[i, j]], NormalDistribution[]], {i, Length[data]}, {j, Length[data[[i]]]}];pC = Interpolation[Transpose[{n, Table[Probability[x ≤ 0.05, xi], {i, ℋ}]}], InterpolationOrder -> 1];Visualize the approximate power curve:
Plot[pC[x], {x, 5, 30}, PlotRange -> {0, 1}, Ticks -> {n, Automatic}, AxesOrigin -> {0, 0}]Estimate the power of the Kuiper test when the underlying distribution is a UniformDistribution[{-4,4}], the test size is 0.05, and the sample size is 12:
pC[12.]Spatial signs transform bivariate data to points on a unit circle and are often used in tests of location. The null hypothesis can be tested by determining whether the spatial signs are significantly clustered:
data1 = RandomVariate[MultinormalDistribution[{0, 0}, IdentityMatrix[2]], 100];
data2 = RandomVariate[MultinormalDistribution[{2, 1}, IdentityMatrix[2]], 100];SpatialSign[d_] := With[{norm = Norm[d]}, If[norm == 0, ConstantArray[0, Length[d]], (d/norm)]]Clustering occurs for nonzero mean vectors:
{ListPlot[SpatialSign /@ data1, AspectRatio -> 1, PlotRange -> {{-1, 1}, {-1, 1}}, ImageSize -> Small], ListPlot[SpatialSign /@ data2, AspectRatio -> 1, PlotRange -> {{-1, 1}, {-1, 1}}, ImageSize -> Small]}A bivariate test for location using spatial signs and Kuiper's test:
KuiperLocationTest[data_, mu0_] := KuiperTest[ArcSin[(SpatialSign /@ Transpose[Transpose[data] - mu0])[[All, 2]]], UniformDistribution[{-(π/2), (π/2)}], "TestDataTable"]{Mean[data1], Mean[data2]}The test does not reject when the mean is close to the null value:
{KuiperLocationTest[data1, {0, 0}], KuiperLocationTest[data2, {2, 1}]}The test rejects the null hypothesis when the mean is not close to the null value:
{KuiperLocationTest[data1, {1, 1}], KuiperLocationTest[data2, {1, 2}]}Properties & Relations (7)
By default, univariate data is compared to a NormalDistribution:
data = RandomVariate[NormalDistribution[2, 3], 10^4];ℋ = KuiperTest[data, Automatic, "HypothesisTestData"];ℋ["TestDataTable"]The parameters have been estimated from the data:
ℋ["FittedDistribution"]Multivariate data is compared to a MultinormalDistribution by default:
data = RandomVariate[MultinormalDistribution[{1, 2, 3}, IdentityMatrix[3]], 1000];ℋ = KuiperTest[data, Automatic, "HypothesisTestData"];ℋ["TestDataTable"]ℋ["FittedDistribution"]//TraditionalFormThe parameters of the test distribution are estimated from the data if not specified:
data = RandomVariate[NormalDistribution[1, 2], 1000];KuiperTest[data, NormalDistribution[μ, σ], "FittedDistribution"]Specified parameters are not estimated:
KuiperTest[data, NormalDistribution[μ, 2], "FittedDistribution"]KuiperTest[data, NormalDistribution[1, 2], "FittedDistribution"]Maximum-likelihood estimates are used for unspecified parameters of the test distribution:
data = RandomVariate[ExponentialDistribution[3], 10^3];ℋ = KuiperTest[data, ExponentialDistribution[λ], "FittedDistribution"]KuiperTest[data, ExponentialDistribution[λ]]If the parameters are unknown, KuiperTest applies a correction when possible:
data = RandomVariate[NormalDistribution[3, 4], 10^4];est = EstimatedDistribution[data, NormalDistribution[μ, σ]]The parameters are estimated but no correction is applied:
KuiperTest[data, est]ℋ = KuiperTest[data, NormalDistribution[μ, σ], "HypothesisTestData"];The fitted distribution is the same as before and the ![]() -value is corrected:
-value is corrected:
ℋ["FittedDistribution"]ℋ["PValue"]Independent marginal densities are assumed in tests for multivariate goodness-of-fit:
data = RandomVariate[MultinormalDistribution[{0, 0}, {{0.118, 0.252}, {0.252, 0.665}}], 100];KuiperTest[data, MultinormalDistribution[{0, 0}, {{0.118, 0.252}, {0.252, 0.665}}], "TestStatistic"]The test statistic is identical when independence is assumed:
KuiperTest[data, MultinormalDistribution[{0, 0}, {{0.118, 0}, {0, 0.665}}], "TestStatistic"]The Kuiper test works with the values only when the input is a TimeSeries:
ts = TemporalData[TimeSeries, {{{1.224578634529677, 0.47929635789978015, 0.6572781300178168,
0.21496048742669355, 0.7299608014554928, -0.2495111111278263, -1.3286551762002712,
0.552725018274874, 0.19272112205837066, 1.1809144012420882, -1.1671 ... 40938613662046, 1.052394590214582, 0.9345044123980388, 0.38537803109557855,
-0.48660931166089394, -0.71203560340161}}, {{0, 100, 1}}, 1, {"Continuous", 1},
{"Discrete", 1}, 1, {ValueDimensions -> 1, ResamplingMethod -> None}}, False, 10.1];KuiperTest[ts]KuiperTest[ts["Values"]]Possible Issues (3)
The Kuiper test is not intended for discrete distributions:
data = RandomVariate[PoissonDistribution[30], 35];KuiperTest[data, PoissonDistribution[30]]The test tends to be quite conservative:
sim = RandomVariate[PoissonDistribution[30], {500, 35}];p = Quiet[KuiperTest[#, PoissonDistribution[30]]]& /@ sim;Show[ListLinePlot[Table[{α, Probability[pv ≤ α, pvp]}, {α, .01, 1, .01}]], Plot[x, {x, 0, 1}, PlotStyle -> Dashed]]Use Monte Carlo methods or PearsonChiSquareTest in these cases:
KuiperTest[data, PoissonDistribution[30], Method -> "MonteCarlo"]PearsonChiSquareTest[data, PoissonDistribution[30]]The Kuiper test is not valid for some distributions when parameters have been estimated from the data:
data = RandomVariate[BetaDistribution[1, 2], 100];KuiperTest[data, BetaDistribution[1, b]]Provide parameter values if they are known:
KuiperTest[data, BetaDistribution[1, 2]]Alternatively, use Monte Carlo methods to approximate the ![]() -value:
-value:
KuiperTest[data, BetaDistribution[1, b], Method -> "MonteCarlo"]data = RandomVariate[NormalDistribution[], 1000];KuiperTest[Join[data, {First[data]}]]PearsonChiSquareTest[Join[data, {First[data]}]]Differences may be more apparent with larger numbers of ties:
KuiperTest[Join[data, data]]PearsonChiSquareTest[Join[data, data]]Neat Examples (1)
Compute the statistic when the null hypothesis ![]() is true:
is true:
data = RandomVariate[NormalDistribution[], {250, 100}];T1 = KuiperTest[#, NormalDistribution[], "TestStatistic"]& /@ data;The test statistic given a particular alternative:
T2 = KuiperTest[#, LaplaceDistribution[1, 2], "TestStatistic"]& /@ data;Compare the distributions of the test statistics:
SmoothHistogram[{T1, T2}, Filling -> Axis, PlotLegends -> {"SubscriptBox[H, 0] is True", "SubscriptBox[H, 0] is False"}, PlotStyle -> Thick]Text
Wolfram Research (2010), KuiperTest, Wolfram Language function, https://reference.wolfram.com/language/ref/KuiperTest.html.
CMS
Wolfram Language. 2010. "KuiperTest." Wolfram Language & System Documentation Center. Wolfram Research. https://reference.wolfram.com/language/ref/KuiperTest.html.
APA
Wolfram Language. (2010). KuiperTest. Wolfram Language & System Documentation Center. Retrieved from https://reference.wolfram.com/language/ref/KuiperTest.html