

AndersonDarlingTest
AndersonDarlingTest[data]
tests whether data is normally distributed using the Anderson–Darling test.
AndersonDarlingTest[data,dist]
tests whether data is distributed according to dist using the Anderson–Darling test.
AndersonDarlingTest[data,dist,"property"]
returns the value of "property".
Details and Options
- AndersonDarlingTest performs the Anderson–Darling goodness-of-fit test with null hypothesis
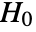 that data was drawn from a population with distribution dist, and alternative hypothesis
that data was drawn from a population with distribution dist, and alternative hypothesis 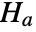 that it was not.
that it was not. - By default, a probability value or
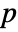 -value is returned.
-value is returned. - A small
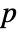 -value suggests that it is unlikely that the data came from dist.
-value suggests that it is unlikely that the data came from dist. - The dist can be any symbolic distribution with numeric and symbolic parameters or a dataset.
- The data can be univariate {x1,x2,…} or multivariate {{x1,y1,…},{x2,y2,…},…}.
- The Anderson–Darling test assumes that the data came from a continuous distribution.
- The Anderson–Darling test effectively uses a test statistic based on
![Expectation[((F^^(x)-F(x))^2)/(F(x) (1-F(x))),...]](Files/AndersonDarlingTest.en/5.png "Expectation[((F^^(x)-F(x))^2)/(F(x) (1-F(x))),...]") where
where 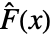 is the empirical CDF of data and
is the empirical CDF of data and 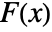 is the CDF of dist.
is the CDF of dist. - For univariate data, the test statistic is given by
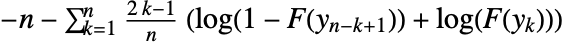 , where
, where  is the sorted data.
is the sorted data. - For multivariate tests, the sum of the univariate marginal
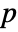 -values is used and is assumed to follow a UniformSumDistribution under
-values is used and is assumed to follow a UniformSumDistribution under 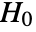 .
. - AndersonDarlingTest[data,dist,"HypothesisTestData"] returns a HypothesisTestData object htd that can be used to extract additional test results and properties using the form htd["property"].
- AndersonDarlingTest[data,dist,"property"] can be used to directly give the value of "property".
- Properties related to the reporting of test results include:
-
"PValue" 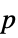 -value
-value"PValueTable" formatted version of "PValue" "ShortTestConclusion" a short description of the conclusion of a test "TestConclusion" a description of the conclusion of a test "TestData" test statistic and 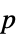 -value
-value"TestDataTable" formatted version of "TestData" "TestStatistic" test statistic "TestStatisticTable" formatted "TestStatistic" - The following properties are independent of which test is being performed.
- Properties related to the data distribution include:
-
"FittedDistribution" fitted distribution of data "FittedDistributionParameters" distribution parameters of data - The following options can be given:
-
Method Automatic the method to use for computing 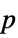 -values
-valuesSignificanceLevel 0.05 cutoff for diagnostics and reporting - For a test for goodness of fit, a cutoff
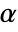 is chosen such that
is chosen such that 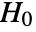 is rejected only if
is rejected only if 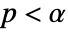 . The value of
. The value of 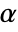 used for the "TestConclusion" and "ShortTestConclusion" properties is controlled by the SignificanceLevel option. By default,
used for the "TestConclusion" and "ShortTestConclusion" properties is controlled by the SignificanceLevel option. By default, 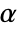 is set to 0.05.
is set to 0.05. - With the setting Method->"MonteCarlo",
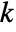 datasets of the same length as the input
datasets of the same length as the input 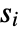 are generated under
are generated under 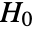 using the fitted distribution. The EmpiricalDistribution from AndersonDarlingTest[si,dist,"TestStatistic"] is then used to estimate the
using the fitted distribution. The EmpiricalDistribution from AndersonDarlingTest[si,dist,"TestStatistic"] is then used to estimate the 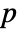 -value.
-value.
Examples
open all close allBasic Examples (3)
Perform an Anderson–Darling test for normality:
data = RandomVariate[NormalDistribution[], 10^3];AndersonDarlingTest[data]Show[SmoothHistogram[data, PlotStyle -> {Dashed, Red}], Plot[PDF[NormalDistribution[], x], {x, -4, 4}]]Test the fit of some data to a particular distribution:
data = RandomVariate[PowerDistribution[1, 2], 10^4];AndersonDarlingTest[data, PowerDistribution[1, 2]]Show[Histogram[data, Automatic, "PDF"], Plot[PDF[PowerDistribution[1, 2], x], {x, 0, 1}, PlotStyle -> Thick, PlotRange -> All]]Compare the distributions of two datasets:
data1 = RandomVariate[NormalDistribution[], 100];data2 = RandomVariate[NormalDistribution[.1, 1], 150];AndersonDarlingTest[data1, data2]SmoothHistogram[{data1, data2}]Scope (9)
Testing (6)
Perform an Anderson–Darling test for normality:
data1 = RandomVariate[NormalDistribution[], 10^4];
data2 = RandomVariate[StudentTDistribution[3], 10^4];The ![]() -value for the normal data is large compared to the
-value for the normal data is large compared to the ![]() -value for the non-normal data:
-value for the non-normal data:
AndersonDarlingTest[data1]AndersonDarlingTest[data2]Test the goodness of fit for a particular distribution:
data1 = RandomVariate[NormalDistribution[], 10^3];
data2 = RandomVariate[CauchyDistribution[0, 1], 10^3];AndersonDarlingTest[data1, CauchyDistribution[0, 1]]AndersonDarlingTest[data2, CauchyDistribution[0, 1]]Compare the distributions of two datasets:
data1 = RandomVariate[NormalDistribution[], 10^3];
data2 = RandomVariate[NormalDistribution[], 10^3];AndersonDarlingTest[data1, data2]data3 = RandomVariate[NormalDistribution[0, 1.25], 10^3];AndersonDarlingTest[data1, data3]Test for multivariate normality:
data1 = RandomVariate[BinormalDistribution[.5], 10^3];
data2 = RandomVariate[LaplaceDistribution[1, 2], {10^3, 2}];AndersonDarlingTest[data1]AndersonDarlingTest[data2]Test for goodness of fit to any multivariate distribution:
data1 = RandomVariate[BinormalDistribution[.5], 10^3];
data2 = RandomVariate[𝒹 = LaplaceDistribution[1, 2], {10^3, 2}];𝒟 = ProductDistribution[𝒹, 𝒹];AndersonDarlingTest[data1, 𝒟]AndersonDarlingTest[data2, 𝒟]Create a HypothesisTestData object for repeated property extraction:
data = RandomVariate[NormalDistribution[], 10^5];ℋ = AndersonDarlingTest[data, Automatic, "HypothesisTestData"]The properties available for extraction:
ℋ["Properties"]Reporting (3)
Tabulate the results of the Anderson–Darling test:
data = RandomVariate[NormalDistribution[], 100];ℋ = AndersonDarlingTest[data, Automatic, "HypothesisTestData"];ℋ["TestDataTable"]ℋ["PValueTable"]ℋ["TestStatisticTable"]Retrieve the entries from an Anderson–Darling test table for custom reporting:
data1 = RandomVariate[NormalDistribution[], 100];
data2 = RandomVariate[NormalDistribution[], 100];ℋ1 = AndersonDarlingTest[data1, Automatic, "TestData"]ℋ2 = AndersonDarlingTest[data2, Automatic, "TestData"]BarChart[{Labeled[ℋ1, "Set 1"], Labeled[ℋ2, "Set 2"]}, ChartLabels -> {"SuperscriptBox[A, 2]", "p‐value"}]Report test conclusions using "ShortTestConclusion" and "TestConclusion":
data = BlockRandom[SeedRandom[1];RandomVariate[ParetoDistribution[1.05, 2], 100]];ℋ = AndersonDarlingTest[data, ParetoDistribution[1, 2], "HypothesisTestData"];ℋ["ShortTestConclusion"]ℋ["TestConclusion"]//TraditionalFormThe conclusion may differ at a different significance level:
ℋ = AndersonDarlingTest[data, ParetoDistribution[1, 2], "HypothesisTestData", SignificanceLevel -> .001];ℋ["ShortTestConclusion"]ℋ["TestConclusion"]//TraditionalFormOptions (4)
Method (3)
Use Monte Carlo-based methods for a computation formula:
data = RandomVariate[NormalDistribution[], 100];AndersonDarlingTest[data, NormalDistribution[], Method -> "MonteCarlo"]AndersonDarlingTest[data, NormalDistribution[], Method -> Automatic]Set the number of samples to use for Monte Carlo-based methods:
data = RandomVariate[NormalDistribution[], 100];pts = Table[{i, AndersonDarlingTest[data, NormalDistribution[], Method -> {"MonteCarlo", "MonteCarloSamples" -> i}]}, {i, Range[5, 250, 15]}];The Monte Carlo estimate converges to the true ![]() -value with increasing samples:
-value with increasing samples:
pval = AndersonDarlingTest[data, NormalDistribution[]];Show[ListLinePlot[pts, PlotRange -> {0, 1}, FrameLabel -> {"Samples", "P-Value"}, Frame -> True, AxesOrigin -> {0, 0}], Graphics[{Dashed, Line[{{0, pval}, {250, pval}}]}]]Set the random seed used in Monte Carlo-based methods:
data = RandomVariate[NormalDistribution[], 100];pts = Table[{i, AndersonDarlingTest[data, NormalDistribution[], Method -> {"MonteCarlo", "RandomSeed" -> i, "MonteCarloSamples" -> 50}]}, {i, Range[1, 10]}];The seed affects the state of the generator and has some effect on the resulting ![]() -value:
-value:
pval = AndersonDarlingTest[data, NormalDistribution[]];Show[ListLinePlot[pts, PlotRange -> {Min[pts[[All, 2]]], Max[pts[[All, 2]]]}, FrameLabel -> {"Seed", "P-Value"}, Frame -> True, AxesOrigin -> {0, 0}], Graphics[{Dashed, Line[{{0, pval}, {100, pval}}]}]]SignificanceLevel (1)
Set the significance level used for "TestConclusion" and "ShortTestConclusion":
data = BlockRandom[SeedRandom[1];RandomVariate[NormalDistribution[], 100]];AndersonDarlingTest[data, NormalDistribution[0, 1.5], "ShortTestConclusion", SignificanceLevel -> .05]AndersonDarlingTest[data, NormalDistribution[0, 1.5], "ShortTestConclusion", SignificanceLevel -> .01]AndersonDarlingTest[data, NormalDistribution[0, 1.5], "TestConclusion"]//TraditionalFormApplications (4)
It can be shown that a GammaDistribution[1,1/λ] is equivalent to an ExponentialDistribution[λ]. This conclusion is supported by simulation:
λvect = {2, 4, 6, 8, 10};data = Table[RandomVariate[GammaDistribution[1, (1/λ)], {1000, 100}], {λ, λvect}];Perform the Anderson–Darling test, grouping each dataset with its expected ![]() value:
value:
p = Table[(AndersonDarlingTest[#1, ExponentialDistribution[λvect[[i]]]]&) /@ data[[i]], {i, Length[λvect]}];The resulting ![]() -value distributions are approximately uniform, supporting the claim:
-value distributions are approximately uniform, supporting the claim:
And@@(AndersonDarlingTest[#, UniformDistribution[], "PValue"] > 0.05& /@ p)A power curve for the Anderson–Darling test:
data = Table[RandomVariate[UniformDistribution[{-4, 4}], {500, i}], {i, n = {5, 7, 10, 15, 20, 25, 30}}];ℋ = Table[AndersonDarlingTest[data[[i, j]], NormalDistribution[]], {i, Length[data]}, {j, Length[data[[i]]]}];pC = Interpolation[Transpose[{n, Table[Probability[x ≤ 0.05, xi], {i, ℋ}]}], InterpolationOrder -> 1];Visualize the approximate power curve:
Plot[pC[x], {x, 5, 30}, PlotRange -> {.6, 1}, Ticks -> {n, Automatic}, AxesOrigin -> {0, 0.6}]Estimate the power of the Anderson–Darling test when the underlying distribution is a UniformDistribution[{-4,4}], the test size is 0.05, and the sample size is 6:
pC[6.]A collection of measurements were taken on 50 members from each of three iris species. It has been observed that the species setosa is easy to identify but that the remaining two species, versicolor and virginica, are often confused:
data = ExampleData[{"Statistics", "FisherIris"}];petalLen = data[[All, 3]];species = data[[All, -1]];The distributions of petal lengths for each species:
SmoothHistogram[Pick[petalLen, species, #], PlotLabel -> #, Filling -> Axis]& /@ DeleteDuplicates[species]The distributions are equivalent for versicolor and virginica, which are very different from setosa:
AndersonDarlingTest[Pick[petalLen, species, "versicolor"], Pick[petalLen, species, "viginica"]]AndersonDarlingTest[Pick[petalLen, species, "setosa"], Pick[petalLen, species, "virginica" | "versicolor"]]Assume the following petal length measures are known for the populations:
Subscript[μ, s] = 1.5;Subscript[μ, vv] = 4.9;Subscript[σ, s] = .2;Subscript[σ, vv] = .8;𝒟 = MixtureDistribution[{50 / 150, 100 / 150}, {NormalDistribution[Subscript[μ, s], Subscript[σ, s]], NormalDistribution[Subscript[μ, vv], Subscript[σ, vv]]}];𝒟data = SmoothKernelDistribution[petalLen, {"Adaptive", Automatic, .5}];Plot[{PDF[𝒟, x], PDF[𝒟data, x]}, {x, 0, 8}, PlotLegends -> {"𝒟", "𝒟data"}]The normal mixture appears to fit the petal length distribution well:
AndersonDarlingTest[petalLen, 𝒟, "TestDataTable"]Estimate distribution parameters by minimizing the Anderson-Darling test statistic:
data = RandomVariate[StudentTDistribution[6.4], 500];adDistance[df_Real] := AndersonDarlingTest[data, StudentTDistribution[df], "TestStatistic"]Plot[adDistance[ν], {ν, 1, 10}]νMinAD = NArgMin[{adDistance[ν], ν > 0}, ν]νMLE = ν /. FindDistributionParameters[data, StudentTDistribution[ν]]Compare Anderson-Darling test statistic for these two optimal parameters:
{adDistance[νMinAD], adDistance[νMLE]}Properties & Relations (9)
By default, univariate data is compared to a NormalDistribution:
data = RandomVariate[NormalDistribution[2, 3], 10^4];ℋ = AndersonDarlingTest[data, Automatic, "HypothesisTestData"];ℋ["TestDataTable"]The parameters have been estimated from the data:
ℋ["FittedDistribution"]Multivariate data is compared to a MultinormalDistribution by default:
data = RandomVariate[MultinormalDistribution[{1, 2, 3}, IdentityMatrix[3]], 1000];ℋ = AndersonDarlingTest[data, Automatic, "HypothesisTestData"];ℋ["TestDataTable"]ℋ["FittedDistribution"]//TraditionalFormThe parameters of the test distribution are estimated from the data if not specified:
data = RandomVariate[NormalDistribution[1, 2], 1000];AndersonDarlingTest[data, NormalDistribution[μ, σ], "FittedDistribution"]Specified parameters are not estimated:
AndersonDarlingTest[data, NormalDistribution[μ, 2], "FittedDistribution"]AndersonDarlingTest[data, NormalDistribution[1, 2], "FittedDistribution"]Maximum likelihood estimates are used for unspecified parameters of the test distribution:
data = RandomVariate[ExponentialDistribution[3], 10^3];ℋ = AndersonDarlingTest[data, ExponentialDistribution[λ], "FittedDistribution"]EstimatedDistribution[data, ExponentialDistribution[λ]]If the parameters are unknown, AndersonDarlingTest applies a correction when possible:
data = RandomVariate[NormalDistribution[3, 4], 10^4];est = EstimatedDistribution[data, NormalDistribution[μ, σ]]The parameters are estimated but no correction is applied:
AndersonDarlingTest[data, est]ℋ = AndersonDarlingTest[data, NormalDistribution[μ, σ], "HypothesisTestData"];The fitted distribution is the same as before and the ![]() -value is corrected:
-value is corrected:
ℋ["FittedDistribution"]ℋ["PValue"]Independent marginal densities are assumed in tests for multivariate goodness of fit:
data = RandomVariate[MultinormalDistribution[{0, 0}, {{0.118, 0.252}, {0.252, 0.665}}], 100];AndersonDarlingTest[data, MultinormalDistribution[{0, 0}, {{0.118, 0.252}, {0.252, 0.665}}], "TestStatistic"]The test statistic is identical when independence is assumed:
AndersonDarlingTest[data, MultinormalDistribution[{0, 0}, {{0.118, 0}, {0, 0.665}}], "TestStatistic"]The Anderson–Darling test statistic:
n = 100;data = Sort@RandomVariate[StudentTDistribution[3], n];F[x_] := CDF[NormalDistribution[], x];-n - Underoverscript[∑, k, n](2 k - 1/n) (Log[1 - F[data[[n - k + 1]]]] + Log[F[data[[k]]]])AndersonDarlingTest[data, NormalDistribution[], "TestStatistic"]The Anderson–Darling statistic can be defined using NExpectation:
n = 10;
h0 = NormalDistribution[1, 2];
data = RandomVariate[h0, n];f[x_] := CDF[h0, x]
Overscript[f, ^ ][x_] := CDF[EmpiricalDistribution[data], x]n NExpectation[((Overscript[f, ^ ][t] - f[t])^2/f[t] (1 - f[t])), th0]AndersonDarlingTest[data, h0, "TestStatistic"]The Anderson–Darling test works on the values only when the input is a TimeSeries:
ts = TemporalData[TimeSeries, {{{0., -0.11029234344648474, 0.0345779635879646, 0.1743666051306928,
0.16967400225598006, 0.1411114639333355, 0.23851991945192513, 0.26921448263698,
0.24027115738328042, 0.17492509184799315, 0.2781622872829057, 0. ... 276577, -0.45856201940681207, -0.4228641161946517,
-0.21228762599990375}}, {{0, 1., 0.01}}, 1, {"Continuous", 1}, {"Continuous", 1}, 1,
{ValueDimensions -> 1, ResamplingMethod -> {"Interpolation", InterpolationOrder -> 1}}}, False,
10.1];AndersonDarlingTest[ts]AndersonDarlingTest[ts["Values"]]Possible Issues (2)
The Anderson–Darling test is not intended for discrete distributions:
data = RandomVariate[PoissonDistribution[30], 35];AndersonDarlingTest[data, PoissonDistribution[30]]The continuity correction typically does a good job of preserving the size of the test:
sim = RandomVariate[PoissonDistribution[30], {500, 35}];p = Quiet[AndersonDarlingTest[#, PoissonDistribution[30]]]& /@ sim;Show[ListLinePlot[Table[{α, Probability[pv ≤ α, pvp]}, {α, .01, 1, .01}]], Plot[x, {x, 0, 1}, PlotStyle -> {Gray, Dashed}]]This may not be the case in some situations:
sim = RandomVariate[DiscreteUniformDistribution[{1, 3}], {500, 35}];p = Quiet[AndersonDarlingTest[#, DiscreteUniformDistribution[{1, 3}]]]& /@ sim;Show[ListLinePlot[Table[{α, Probability[pv ≤ α, pvp]}, {α, .01, 1, .01}]], Plot[x, {x, 0, 1}, PlotStyle -> {Gray, Dashed}]]Use Monte Carlo methods or PearsonChiSquareTest in these cases:
AndersonDarlingTest[sim[[1]], DiscreteUniformDistribution[{1, 3}], Method -> "MonteCarlo"]PearsonChiSquareTest[sim[[1]], DiscreteUniformDistribution[{1, 3}]]The Anderson–Darling test is not valid for some distributions when parameters have been estimated from the data:
data = RandomVariate[BetaDistribution[1, 2], 100];AndersonDarlingTest[data, BetaDistribution[1, b]]Provide parameter values if they are known:
AndersonDarlingTest[data, BetaDistribution[1, 2]]Alternatively, use Monte Carlo methods to approximate the ![]() -value:
-value:
AndersonDarlingTest[data, BetaDistribution[1, b], Method -> "MonteCarlo"]Neat Examples (1)
Compute the statistic when the null hypothesis ![]() is true:
is true:
data = RandomVariate[NormalDistribution[], {2500, 100}];T1 = AndersonDarlingTest[#, NormalDistribution[], "TestStatistic"]& /@ data;The test statistic given a particular alternative:
T2 = AndersonDarlingTest[#, NormalDistribution[1, 2], "TestStatistic"]& /@ data;Compare the distributions of the test statistics:
SmoothHistogram[{T1, T2}, Filling -> Axis, PlotLegends -> {"SubscriptBox[H, 0] is True", "SubscriptBox[H, 0] is False"}, PlotStyle -> Thick]Text
Wolfram Research (2010), AndersonDarlingTest, Wolfram Language function, https://reference.wolfram.com/language/ref/AndersonDarlingTest.html.
CMS
Wolfram Language. 2010. "AndersonDarlingTest." Wolfram Language & System Documentation Center. Wolfram Research. https://reference.wolfram.com/language/ref/AndersonDarlingTest.html.
APA
Wolfram Language. (2010). AndersonDarlingTest. Wolfram Language & System Documentation Center. Retrieved from https://reference.wolfram.com/language/ref/AndersonDarlingTest.html