SmoothKernelDistribution
SmoothKernelDistribution[{x1,x2,…}]
表示基于数据值 xi 的平滑核分布.
SmoothKernelDistribution[{{x1,y1,…},{x2,y2,…},…}]
表示基于数据值 {xi,yi,…} 的多元平滑核分布.
SmoothKernelDistribution[…,bw]
表示带宽为 bw 的平滑核分布.
SmoothKernelDistribution[…,bw,ker]
表示带宽为 bw 以及平滑核为 ker 的平滑核分布.
更多信息和选项




- SmoothKernelDistribution 返回一个可以像任何其它概率分布一样使用的 DataDistribution 对象.
- 一个值
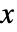 的 SmoothKernelDistribution 的概率密度函数由平滑核
的 SmoothKernelDistribution 的概率密度函数由平滑核 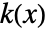 和带宽参数
和带宽参数  的
的 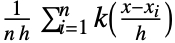 的线性插值版本给出.
的线性插值版本给出. - 可以给出如下带宽说明 bw:
-
h 要使用的带宽 {"Standardized",h} 以标准差为单位的带宽 {"Adaptive",h,s} 具有初始带宽 h 和灵敏度 s 的自适应性 Automatic 自动计算的带宽 "name" 使用一个已命名的带宽选择方法 {bwx,bwy,…} 对 x、y 等的不同的带宽说明 - 对于多变量密度,h 可以是正定对称矩阵.
- 对于自适应带宽,敏感度 s 必须是介于0和1之间的实数或 Automatic. 如果使用 Automatic,s 被设为
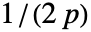 ,其中
,其中  是数据的维数.
是数据的维数. - 可能的已命名带宽选择方法包括:
-
"LeastSquaresCrossValidation" 使用最小二乘交叉核实法 "Oversmooth" 比标准高斯宽1.08倍 "Scott" 使用 Scott 规则来确定带宽 "SheatherJones" 使用 Sheather-Jones 插入式估计量 "Silverman" 使用 Silverman 规则来确定带宽 "StandardDeviation" 使用标准差作为带宽 "StandardGaussian" 标准正态数据的最佳带宽 - 默认使用 "Silverman" 法.
- 对于自动带宽计算,假定常量数组具有单位方差.
- 可以给出的可能的核说明 ker 有:
-
"Biweight" 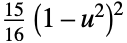
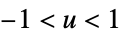
"Cosine" 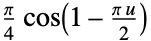

"Epanechnikov" 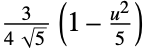
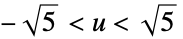
"Gaussian" 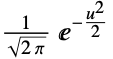
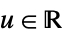
"Rectangular" 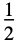

"SemiCircle" 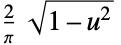
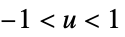
"Triangular" 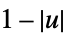
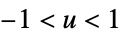
"Triweight" 
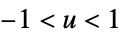
func 

- 为了使 SmoothKernelDistribution 能够生成一个真正的密度估计,函数 fn 应该是一个有效的概率密度函数.
- 默认使用 "Gaussian" 核.
- 内核函数 ker 可以使用 {"Bounded",c,ker} 指定来考虑内在密度的已知边界,其中 c 可以是任意实数、列表 {c1,c2} 满足 c1<c2,或者列表 {{c11,c12},{c21,c22},…},其中长度等于 data 的维度.
- 对于多变量密度,核函数 ker 可以分别使用 {"Product",ker} 和 {"Radial",ker} 指定 Product 和 Radial 类型. 如果没有指定类型,则使用 Product 类型核.
- 密度估计所用的精度是在 bw 和数据中给出的最小精度.
- 可以给出以下选项:
-
InterpolationPoints Automatic 所使用的插值点的初始数目 MaxMixtureKernels Automatic 所使用的核的最大数目 MaxRecursion Automatic 所允许的递归细分数目 PerformanceGoal Automatic 对速度或者质量进行优化 MaxExtraBandwidths Automatic 超过要使用的数据的最大带宽 - SmoothKernelDistribution 可以与诸如 Mean、CDF 和 RandomVariate 等函数一起使用.
范例
打开所有单元关闭所有单元基本范例 (2)
范围 (37)
基本用途 (7)
分布属性 (8)
与 SmoothKernelDistribution 比较:
核函数 (6)
这等同于使用 NormalDistribution[0,1] 的概率密度函数:
使用固定域估计 (4)
与原始 BetaDistribution 比较:
选项 (25)
InterpolationPoints (6)
MaxExtraBandwidths (6)
MaxMixtureKernels (6)
MaxRecursion (4)
PerformanceGoal (3)
对速度或者质量,设置 PerformanceGoal,或使用 Automatic 平衡两者:
在 PerformanceGoal 设置为 "Quality" 时,需要更多时间:
使用 ControlActive 动态变化 PerformanceGoal:
应用 (14)
使用 TruncatedDistribution 来限制平滑后的域:
使用 Cases 来限制平滑前的数据域:
使用 MaxExtraBandwidths 无需删除数据来限制域:
估计 Old Faithful 喷泉持续时间和等待时间的联合分布:
平滑由 SurvivalDistribution 返回一个估计量:
在每个经过自举法处理(bootstrapped)的样本上,进行平滑处理,并且获取置信估计量:
给定 p 维多变量正态数据下,确认 Mahalanobis 距离遵从一个渐进的 ChiSquareDistribution[p]:
属性和关系 (8)
CDF 和 SurvivalFunction 是分段二次的:
在二次上线性的情况下,HazardFunction 是有理分段的:
SmoothKernelDistribution 是内在分布的一个一致的估计量:
SmoothKernelDistribution 是 KernelMixtureDistribution 的一个线性插值:
SmoothKernelDistribution 只在输入为 TimeSeries 或 EventSeries 时才作用于数值:
SmoothKernelDistribution 当输入是 TemporalData 时作用于所有数值:
可能存在的问题 (4)
尝试增加初始带宽,MaxMixtureKernels,或者降低灵敏度:
SmoothKernelDistribution 并不知道内在分布的域:
虽然内在的分布是离散的,估计的 PDF 是连续的:
KernelMixtureDistribution 使用不依赖于插值的符号式方法:
文本
Wolfram Research (2010),SmoothKernelDistribution,Wolfram 语言函数,https://reference.wolfram.com/language/ref/SmoothKernelDistribution.html (更新于 2016 年).
CMS
Wolfram 语言. 2010. "SmoothKernelDistribution." Wolfram 语言与系统参考资料中心. Wolfram Research. 最新版本 2016. https://reference.wolfram.com/language/ref/SmoothKernelDistribution.html.
APA
Wolfram 语言. (2010). SmoothKernelDistribution. Wolfram 语言与系统参考资料中心. 追溯自 https://reference.wolfram.com/language/ref/SmoothKernelDistribution.html 年